KOI: Accelerating Online Imitation Learning via Hybrid Key-state Guidance
作者: Jingxian Lu, Wenke Xia, Dong Wang, Zhigang Wang, Bin Zhao, Di Hu, Xuelong Li
分类: cs.RO, cs.AI
发布日期: 2024-08-06 (更新: 2024-10-17)
备注: Accepted by CoRL 2024
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
KOI:通过混合关键状态引导加速在线模仿学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 在线模仿学习 关键状态引导 视觉-语言模型 光流法 机器人操作
📋 核心要点
- 在线模仿学习因探索空间大和专家数据少,导致奖励估计不准,探索效率低。
- KOI方法结合语义和运动关键状态,指导奖励估计,实现任务感知的在线探索。
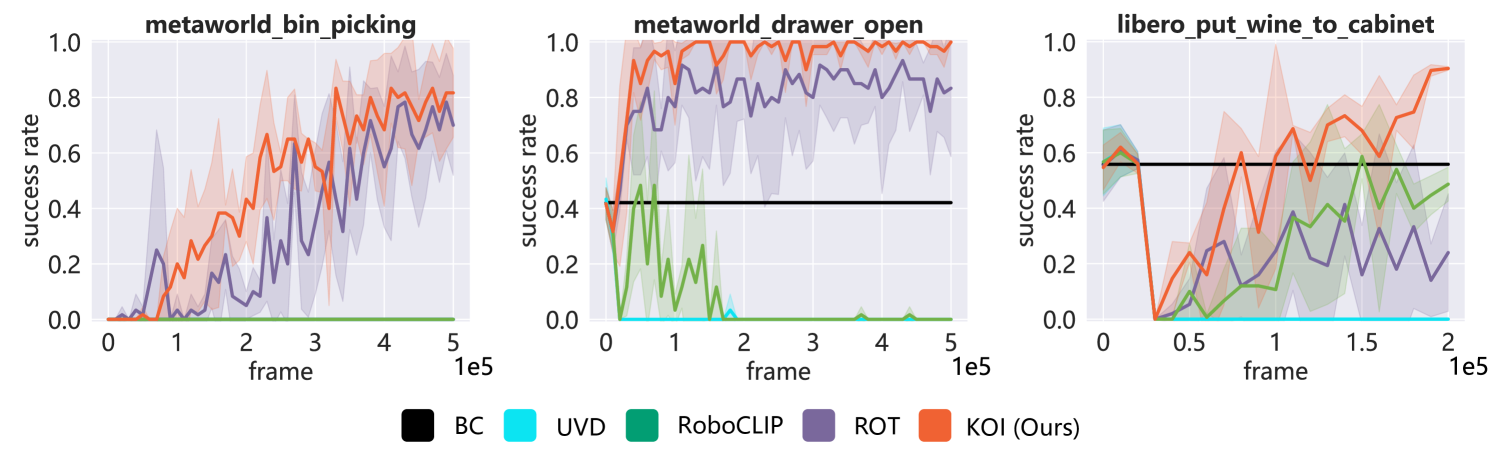
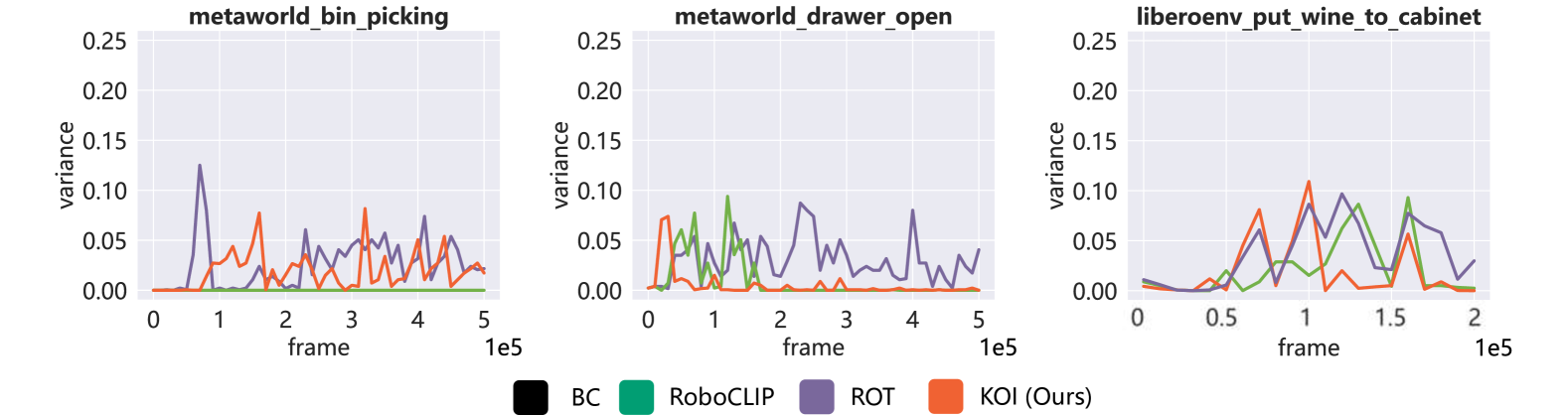
- 实验表明,KOI在Meta-World、LIBERO和真实机器人操作中,均表现出更高的样本效率。
📝 摘要(中文)
在线模仿学习面临着广泛的在线探索空间和有限的专家轨迹之间的差距,由于不准确的奖励估计,阻碍了高效探索。受认知神经科学研究的启发,我们假设智能体可以通过将目标任务分解为“做什么”的目标和“如何做”的机制,来估计精确的、任务感知的奖励,从而实现高效的在线探索。本文提出了一种混合关键状态引导的在线模仿(KOI)学习方法,该方法利用语义和运动关键状态的集成作为奖励估计的指导。首先,我们利用视觉-语言模型从专家轨迹中提取语义关键状态,指示“做什么”的目标。在语义关键状态之间的间隔内,采用光流来捕获运动关键状态,以理解“如何做”的机制。通过对混合关键状态的透彻理解,我们改进了轨迹匹配奖励的计算,从而通过任务感知的探索加速在线模仿学习。我们不仅评估了Meta-World和LIBERO环境中任务的成功率,还评估了在线模仿学习期间方差的趋势,证明了我们的方法具有更高的样本效率。我们还进行了真实的机器人操作实验,以验证我们方法的有效性,证明了KOI方法的实际适用性。
🔬 方法详解
问题定义:在线模仿学习旨在让智能体通过与环境交互和模仿专家轨迹来学习策略。然而,由于在线探索空间巨大,而专家轨迹有限,智能体难以准确估计奖励函数,导致探索效率低下,学习效果不佳。现有的方法通常依赖于简单的轨迹匹配或行为克隆,无法充分利用专家知识,难以适应复杂任务。
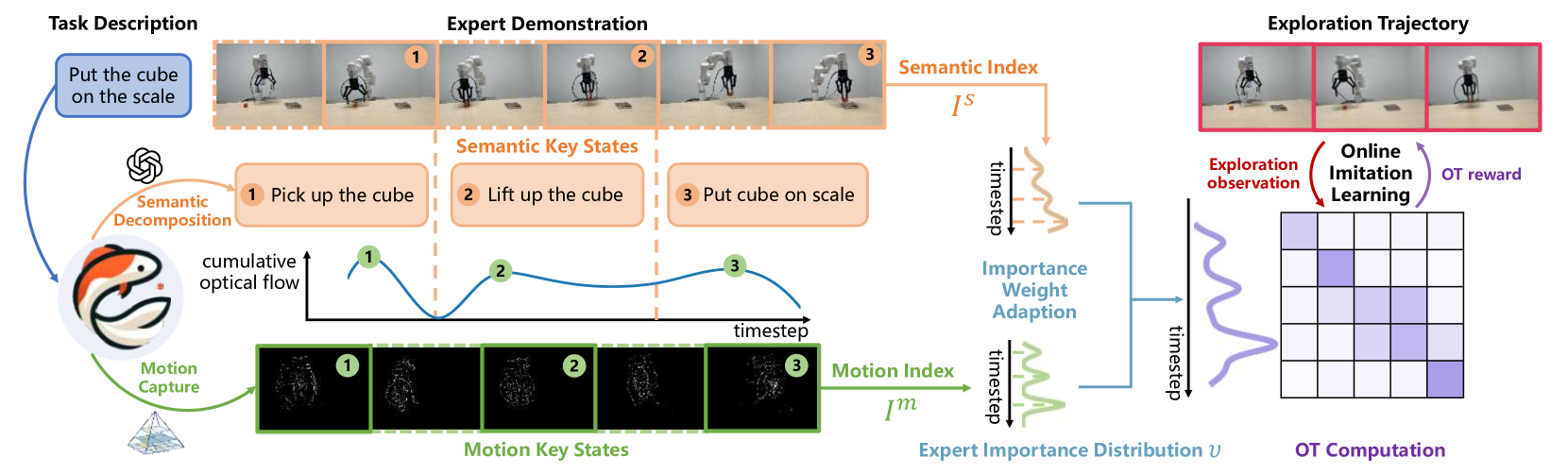
核心思路:KOI的核心思路是将任务分解为“做什么”(语义关键状态)和“如何做”(运动关键状态)两个层面。通过视觉-语言模型提取语义关键状态,明确任务目标;通过光流提取运动关键状态,理解动作执行方式。将二者结合,更准确地估计奖励,引导智能体进行任务感知的探索。这种分解方式借鉴了认知神经科学的发现,更符合人类解决问题的思路。
技术框架:KOI方法的整体框架包括以下几个主要模块:1) 语义关键状态提取:使用视觉-语言模型(如CLIP)从专家轨迹中提取语义关键状态,这些状态代表了任务的关键目标。2) 运动关键状态提取:在语义关键状态之间,使用光流法提取运动关键状态,这些状态代表了实现目标的具体动作。3) 混合关键状态融合:将语义和运动关键状态进行融合,形成对任务的全面理解。4) 奖励函数设计:基于混合关键状态,设计奖励函数,鼓励智能体模仿专家轨迹,并完成任务目标。5) 在线模仿学习:使用强化学习算法(如PPO)进行在线模仿学习,通过与环境交互,不断优化策略。
关键创新:KOI方法的关键创新在于混合关键状态的表示和利用。与传统方法只关注轨迹匹配或行为克隆不同,KOI方法同时考虑了任务的语义目标和动作执行方式,从而更准确地估计奖励,引导智能体进行高效的探索。这种混合表示方式能够更好地利用专家知识,提高学习效率。
关键设计:在语义关键状态提取方面,使用了预训练的CLIP模型,并根据具体任务进行了微调。在运动关键状态提取方面,使用了光流法来捕捉相邻帧之间的运动信息。奖励函数的设计采用了加权求和的方式,将语义关键状态和运动关键状态的匹配程度作为奖励信号。具体权重的选择需要根据任务进行调整。
🖼️ 关键图片
📊 实验亮点
KOI方法在Meta-World和LIBERO环境中取得了显著的性能提升。在Meta-World环境中,KOI方法在多个任务上的成功率超过了现有基线方法。在LIBERO环境中,KOI方法也表现出更高的样本效率和更快的收敛速度。此外,真实的机器人操作实验也验证了KOI方法的有效性,表明该方法具有实际应用价值。
🎯 应用场景
KOI方法具有广泛的应用前景,可以应用于各种机器人操作任务,例如物体抓取、装配、导航等。该方法还可以应用于虚拟环境中的智能体控制,例如游戏AI、自动驾驶等。通过结合视觉-语言模型和运动信息,KOI方法可以使智能体更好地理解任务目标,并高效地学习完成任务所需的策略,具有重要的实际应用价值和潜在的未来影响。
📄 摘要(原文)
Online Imitation Learning struggles with the gap between extensive online exploration space and limited expert trajectories, hindering efficient exploration due to inaccurate reward estimation. Inspired by the findings from cognitive neuroscience, we hypothesize that an agent could estimate precise task-aware reward for efficient online exploration, through decomposing the target task into the objectives of "what to do" and the mechanisms of "how to do". In this work, we introduce the hybrid Key-state guided Online Imitation (KOI) learning method, which leverages the integration of semantic and motion key states as guidance for reward estimation. Initially, we utilize visual-language models to extract semantic key states from expert trajectory, indicating the objectives of "what to do". Within the intervals between semantic key states, optical flow is employed to capture motion key states to understand the mechanisms of "how to do". By integrating a thorough grasp of hybrid key states, we refine the trajectory-matching reward computation, accelerating online imitation learning with task-aware exploration. We evaluate not only the success rate of the tasks in the Meta-World and LIBERO environments, but also the trend of variance during online imitation learning, proving that our method is more sample efficient. We also conduct real-world robotic manipulation experiments to validate the efficacy of our method, demonstrating the practical applicability of our KOI method. Videos and code are available at https://gewu-lab.github.io/Keystate_Online_Imitation/.