Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion
作者: Ho Jae Lee, Seungwoo Hong, Sangbae Kim
分类: cs.RO, eess.SY
发布日期: 2024-08-05
备注: 8 pages
💡 一句话要点
结合模型预测与强化学习,实现动态腿足机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿足机器人 强化学习 模型预测控制 足迹规划 动态运动
📋 核心要点
- 现有腿足机器人控制方法难以兼顾模型预测性和适应性,易出现策略过拟合。
- 提出结合LIP模型足迹规划与强化学习的控制框架,利用模型预测提供部分指导。
- 实验表明,该方法在MIT人形机器人上实现了稳定、动态的行走和转弯,并在不平坦地形上表现出良好的适应性。
📝 摘要(中文)
本文提出了一种控制框架,该框架结合了基于模型的足迹规划与强化学习(RL),利用线性倒立摆(LIP)动力学推导出的期望足迹模式。该方法利用LIP模型,前向预测机器人状态,并根据速度指令确定期望的足部位置。然后,训练一个RL策略来跟踪足部位置,而无需遵循LIP模型导出的完整参考运动。来自物理模型的这种部分指导,使RL策略能够整合物理信息动力学的预测能力和RL控制器的适应性特征,而不会使策略过度拟合模板模型。该方法在MIT人形机器人上进行了验证,证明了该策略可以实现稳定而动态的步行和转弯运动。通过将运动任务扩展到未见过的、不平坦的地形,进一步验证了策略的适应性和泛化性。在硬件部署期间,在跑步机上实现了高达1.5米/秒的前进速度,并成功地执行了动态运动动作,例如90度和180度转弯。
🔬 方法详解
问题定义:现有腿足机器人控制方法通常依赖于精确的动力学模型或纯数据驱动的强化学习。基于模型的控制方法虽然具有良好的预测性,但对模型误差敏感,难以适应复杂环境。纯强化学习方法虽然具有较强的适应性,但训练成本高,且难以保证运动的稳定性。因此,如何结合两者的优点,实现稳定、动态且适应性强的腿足机器人运动控制是一个挑战。
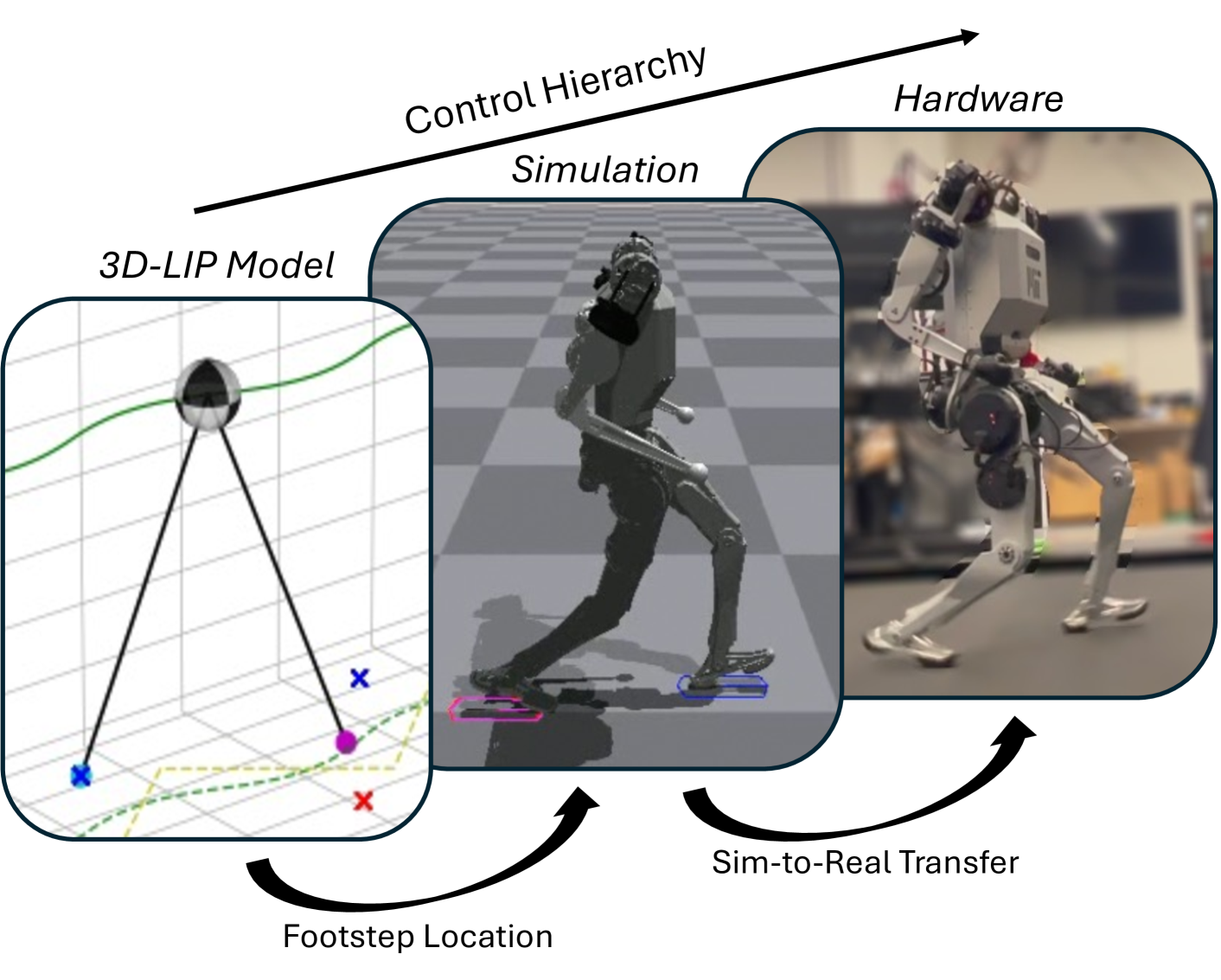
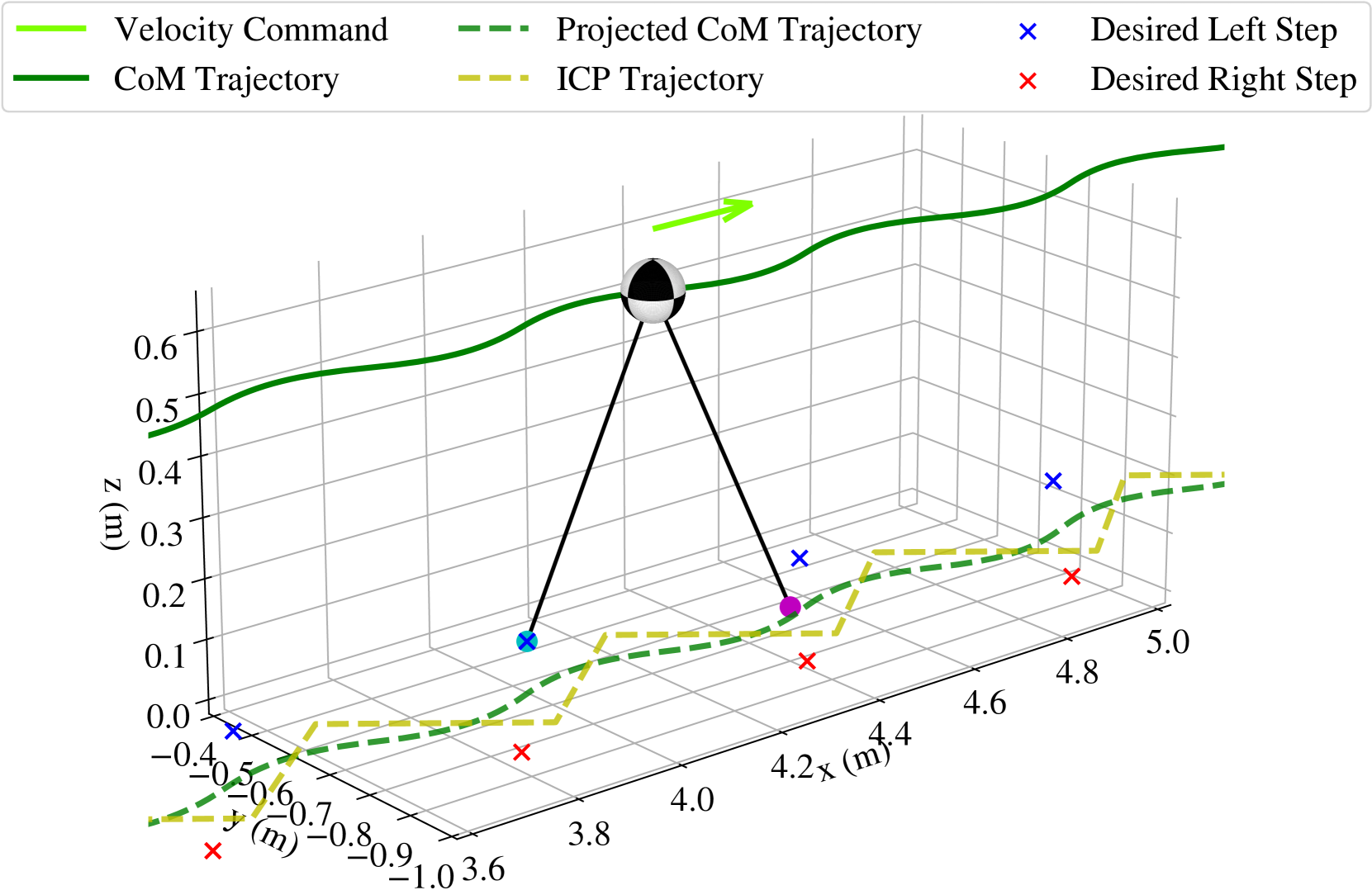
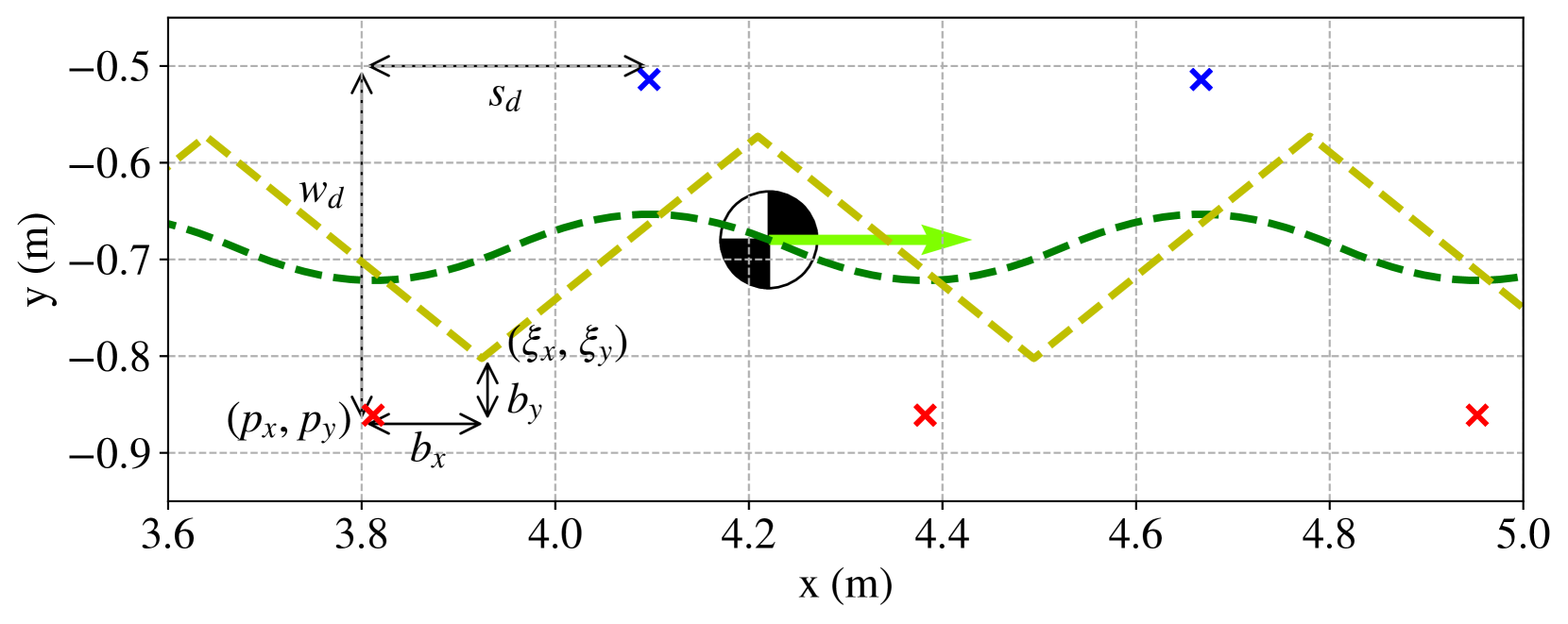
核心思路:本文的核心思路是将基于模型的足迹规划与强化学习相结合。具体而言,首先利用线性倒立摆(LIP)模型进行足迹规划,生成期望的足部位置。然后,训练一个强化学习策略来跟踪这些期望的足部位置,但并不完全依赖LIP模型生成的完整参考轨迹。这种部分指导的方式,既利用了LIP模型的预测能力,又赋予了强化学习策略一定的自由度,使其能够适应环境变化。
技术框架:整体框架包含两个主要模块:足迹规划模块和强化学习控制模块。足迹规划模块基于LIP模型,根据期望的速度指令,预测机器人的状态,并生成期望的足部位置。强化学习控制模块则接收期望的足部位置作为输入,通过训练一个策略网络,输出机器人的关节控制指令。这两个模块协同工作,共同实现腿足机器人的运动控制。
关键创新:本文最重要的技术创新在于将基于模型的足迹规划与强化学习进行有效结合。与传统的基于模型的控制方法相比,该方法具有更强的适应性。与纯强化学习方法相比,该方法具有更高的训练效率和更好的运动稳定性。通过LIP模型提供的部分指导,强化学习策略能够更快地学习到有效的控制策略,并避免过度拟合到特定的环境或任务。
关键设计:在足迹规划模块中,LIP模型的参数需要根据具体的机器人进行调整。在强化学习控制模块中,策略网络的设计至关重要。本文采用了一种Actor-Critic架构的策略网络,其中Actor网络负责输出控制指令,Critic网络负责评估当前状态的价值。损失函数的设计需要综合考虑足部位置跟踪误差、关节力矩限制以及运动平滑性等因素。具体的参数设置和网络结构需要在实验中进行调整和优化。
🖼️ 关键图片
📊 实验亮点
该方法在MIT人形机器人上进行了实验验证,结果表明,该策略能够实现稳定且动态的行走和转弯运动。在跑步机上实现了高达1.5米/秒的前进速度,并成功地执行了动态运动动作,例如90度和180度转弯。此外,该策略在未见过的、不平坦的地形上表现出良好的适应性和泛化性,验证了该方法的有效性和鲁棒性。
🎯 应用场景
该研究成果可应用于各种腿足机器人,例如人形机器人、四足机器人等,使其能够在复杂地形和动态环境中实现稳定、高效的运动。潜在应用领域包括搜救、物流、巡检、以及人机协作等。通过结合模型预测和强化学习,可以显著提高腿足机器人的自主性和适应性,使其能够更好地服务于人类社会。
📄 摘要(原文)
In this work, we introduce a control framework that combines model-based footstep planning with Reinforcement Learning (RL), leveraging desired footstep patterns derived from the Linear Inverted Pendulum (LIP) dynamics. Utilizing the LIP model, our method forward predicts robot states and determines the desired foot placement given the velocity commands. We then train an RL policy to track the foot placements without following the full reference motions derived from the LIP model. This partial guidance from the physics model allows the RL policy to integrate the predictive capabilities of the physics-informed dynamics and the adaptability characteristics of the RL controller without overfitting the policy to the template model. Our approach is validated on the MIT Humanoid, demonstrating that our policy can achieve stable yet dynamic locomotion for walking and turning. We further validate the adaptability and generalizability of our policy by extending the locomotion task to unseen, uneven terrain. During the hardware deployment, we have achieved forward walking speeds of up to 1.5 m/s on a treadmill and have successfully performed dynamic locomotion maneuvers such as 90-degree and 180-degree turns.