VITAL: Interactive Few-Shot Imitation Learning via Visual Human-in-the-Loop Corrections
作者: Hamidreza Kasaei, Mohammadreza Kasaei
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-07-30 (更新: 2025-05-21)
💡 一句话要点
VITAL:基于视觉人机交互修正的少样本模仿学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 少样本学习 人机交互 数据增强 机器人操作
📋 核心要点
- 模仿学习数据收集成本高、泛化性差是核心问题,高质量演示数据难以获取。
- 利用模拟环境进行数据增强,结合人机交互修正,提升策略的泛化性和鲁棒性。
- 实验表明,该方法在多种操作任务中有效,并能推广到新任务,具有良好的适应性。
📝 摘要(中文)
模仿学习(IL)已成为机器人领域一种强大的方法,它允许机器人通过模仿人类行为来获得新技能。尽管其潜力巨大,但IL的数据收集过程仍然是一个重大挑战,因为获取高质量演示在后勤方面存在困难且成本高昂。为了解决这些问题,我们提出了一种通过在模拟中进行数据增强,从少量演示中生成大规模数据的方法。我们的方法利用经济实惠的硬件和视觉处理技术来收集演示,然后对其进行增强,从而为模仿学习创建广泛的训练数据集。通过利用真实和模拟环境,以及人机交互修正,我们增强了学习策略的泛化性和鲁棒性。我们通过在模拟和真实机器人环境中进行的多轮实验评估了我们的方法,重点关注不同复杂程度的任务,包括收集瓶子、堆叠物体和锤击。我们的实验结果验证了我们的方法在从模拟数据中学习鲁棒机器人策略方面的有效性,并通过人机交互修正和真实世界数据集成得到了显著改进。此外,我们展示了该框架推广到新任务(如设置饮料托盘)的能力,展示了其适应性和处理各种现实世界操作任务的潜力。
🔬 方法详解
问题定义:模仿学习旨在让机器人通过观察人类演示来学习技能。然而,现有方法面临数据收集的挑战,高质量的演示数据往往难以获取,成本高昂,并且容易受到环境变化的影响,导致泛化能力不足。因此,需要一种能够利用少量演示数据,学习鲁棒且泛化的机器人策略的方法。
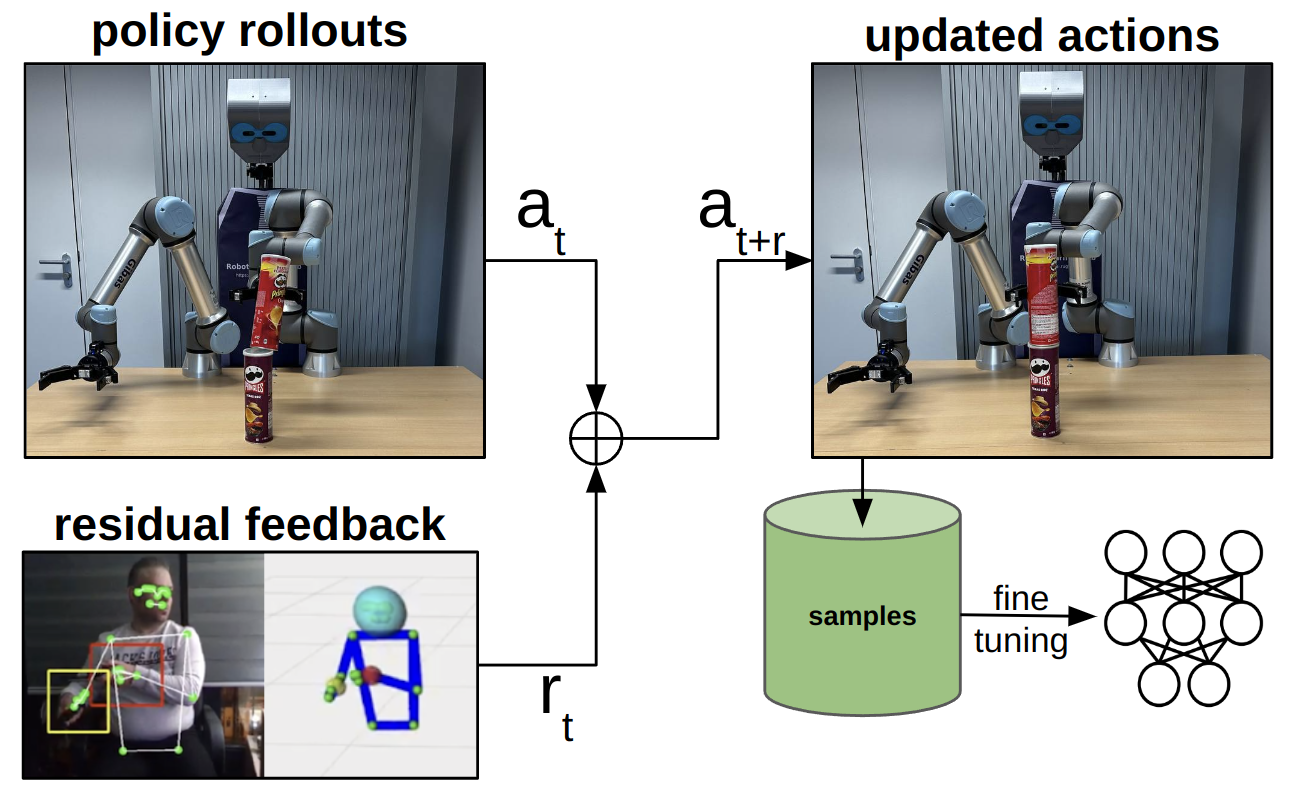
核心思路:该论文的核心思路是利用模拟环境进行数据增强,从而扩展少量真实演示数据。同时,引入人机交互修正机制,允许人类专家对机器人的行为进行纠正,从而提高学习策略的准确性和鲁棒性。通过结合模拟数据、真实数据和人机交互,弥补了数据不足和泛化性差的问题。
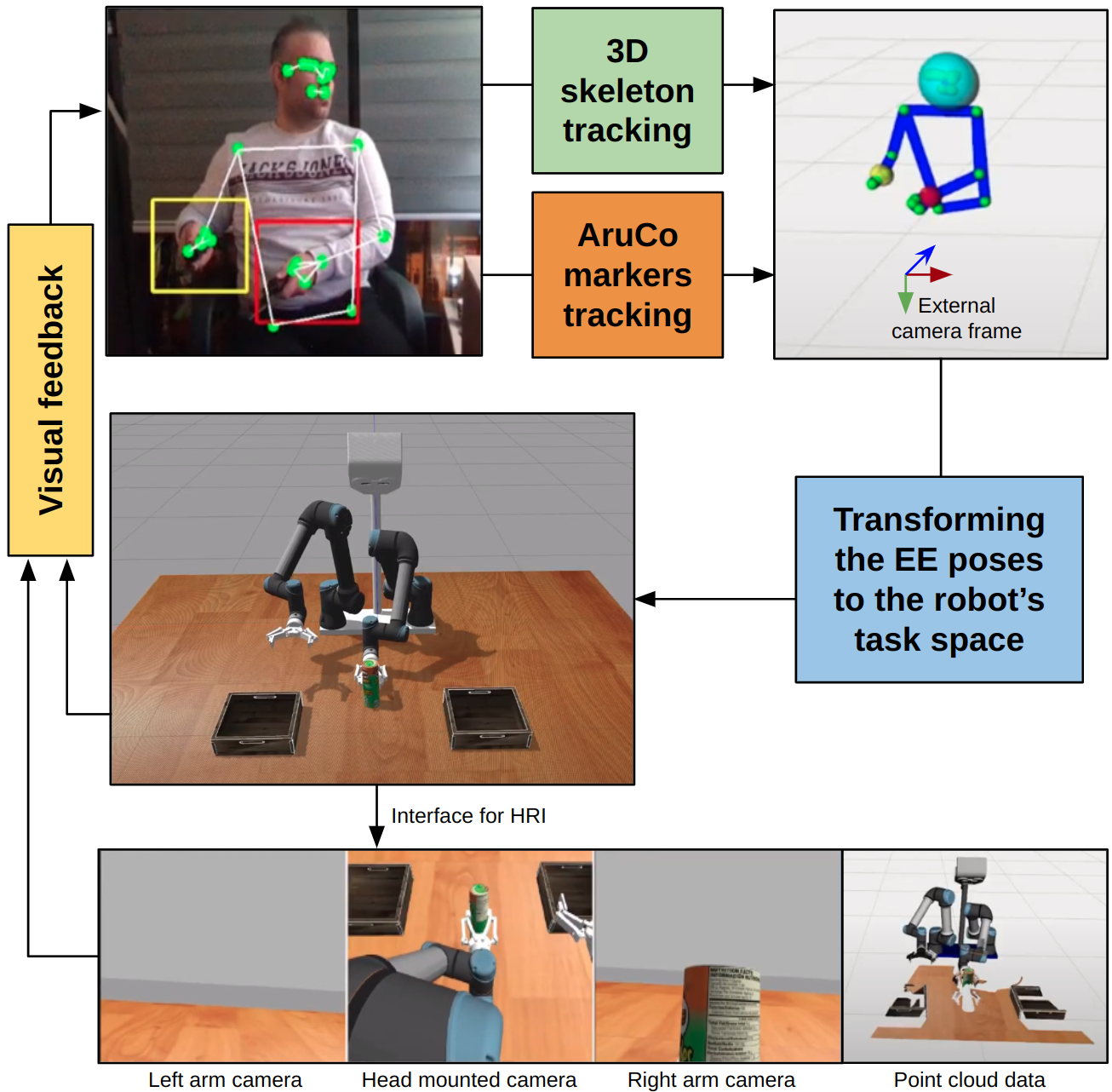
技术框架:该方法包含以下主要阶段:1) 使用经济的硬件和视觉处理技术收集少量真实演示数据。2) 在模拟环境中,利用数据增强技术,从真实数据生成大量模拟数据。3) 使用模仿学习算法,在模拟数据上训练机器人策略。4) 引入人机交互修正环节,让人类专家对机器人的行为进行纠正,并将修正后的数据用于进一步训练。5) 将训练好的策略部署到真实机器人上,并进行评估。
关键创新:该论文的关键创新在于结合了模拟数据增强和人机交互修正,从而在少样本模仿学习中实现了更好的性能。与传统的模仿学习方法相比,该方法能够利用少量真实数据生成大量训练数据,并利用人机交互提高策略的准确性和鲁棒性。
关键设计:论文中使用了视觉处理技术来提取演示数据中的关键特征。数据增强方法包括随机噪声、视角变换等。人机交互修正环节允许人类专家通过视觉反馈对机器人的动作进行调整。具体的损失函数和网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在收集瓶子、堆叠物体和锤击等任务中表现出色,显著提高了机器人策略的鲁棒性和泛化能力。通过人机交互修正和真实世界数据集成,该方法能够从模拟数据中学习到有效的机器人策略,并成功推广到新的任务,如设置饮料托盘。具体的性能数据和提升幅度在论文中可能有所体现,但摘要中未明确给出。
🎯 应用场景
该研究具有广泛的应用前景,可应用于各种需要机器人进行操作的场景,如智能制造、物流仓储、家庭服务等。通过少量演示和人机交互,机器人可以快速学习新的技能,从而提高生产效率和服务质量。该研究还有助于降低机器人部署和维护的成本,促进机器人在更多领域的应用。
📄 摘要(原文)
Imitation Learning (IL) has emerged as a powerful approach in robotics, allowing robots to acquire new skills by mimicking human actions. Despite its potential, the data collection process for IL remains a significant challenge due to the logistical difficulties and high costs associated with obtaining high-quality demonstrations. To address these issues, we propose a large-scale data generation from a handful of demonstrations through data augmentation in simulation. Our approach leverages affordable hardware and visual processing techniques to collect demonstrations, which are then augmented to create extensive training datasets for imitation learning. By utilizing both real and simulated environments, along with human-in-the-loop corrections, we enhance the generalizability and robustness of the learned policies. We evaluated our method through several rounds of experiments in both simulated and real-robot settings, focusing on tasks of varying complexity, including bottle collecting, stacking objects, and hammering. Our experimental results validate the effectiveness of our approach in learning robust robot policies from simulated data, significantly improved by human-in-the-loop corrections and real-world data integration. Additionally, we demonstrate the framework's capability to generalize to new tasks, such as setting a drink tray, showcasing its adaptability and potential for handling a wide range of real-world manipulation tasks. A video of the experiments can be found at: https://youtu.be/YeVAMRqRe64?si=R179xDlEGc7nPu8i