Privileged Reinforcement and Communication Learning for Distributed, Bandwidth-limited Multi-robot Exploration
作者: Yixiao Ma, Jingsong Liang, Yuhong Cao, Derek Ming Siang Tan, Guillaume Sartoretti
分类: cs.RO
发布日期: 2024-07-29
备注: Accepted by DARS2024
💡 一句话要点
提出基于特权强化学习和通信学习的分布式多机器人探索方法,解决带宽限制问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多机器人探索 强化学习 通信学习 特权学习 带宽限制 分布式系统
📋 核心要点
- 多机器人探索中,机器人间的通信带宽是重要瓶颈,现有方法在降低通信量的同时,往往需要大量计算或牺牲探索效率。
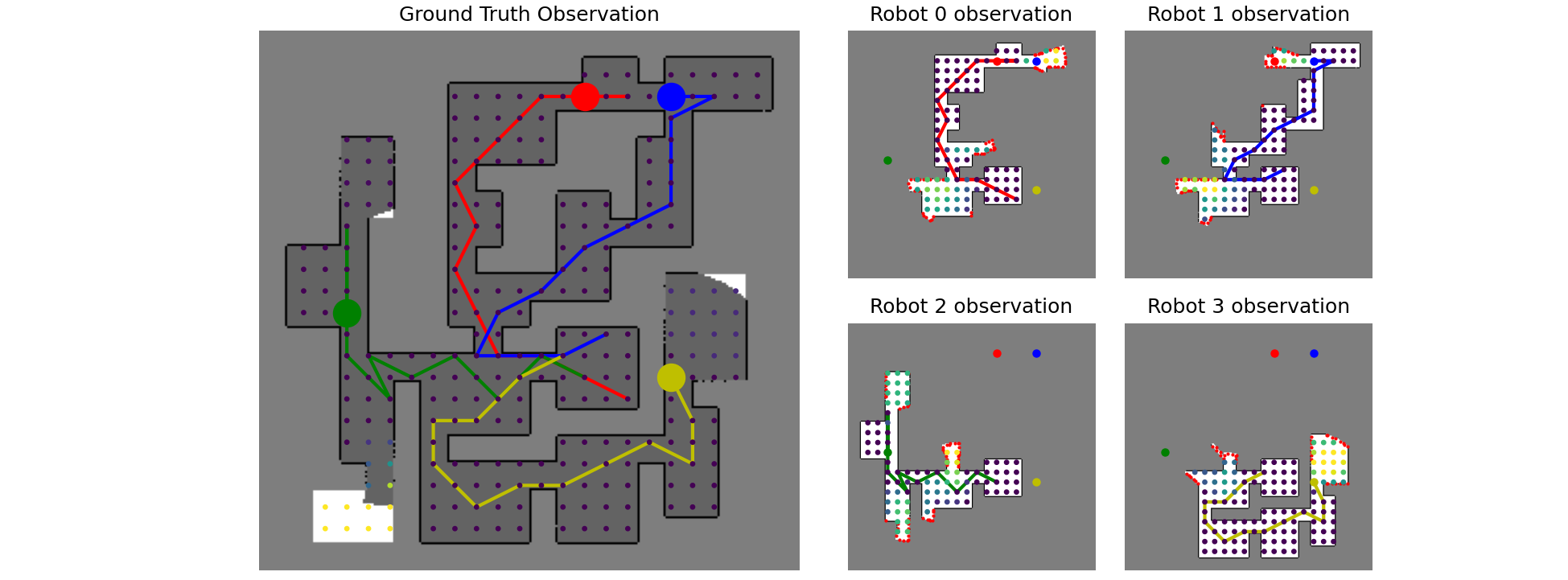
- 该论文提出一种基于通信和特权强化学习的框架,让机器人学习将局部地图的关键信息嵌入定长消息,并结合自身信念和接收到的消息进行探索。
- 实验表明,该方法在通信量减少高达两个数量级的同时,仅牺牲了2.4%的总行驶距离,实现了高效的分布式探索。
📝 摘要(中文)
本文提出了一种基于通信和特权强化学习的深度强化学习框架,旨在显著降低多机器人探索中的带宽消耗,同时尽量减少探索效率的损失。该方法允许机器人学习将来自其个体信念(局部地图)中的最显著信息嵌入到固定大小的消息中。然后,机器人推理自身信念和接收到的消息,以分布式地探索环境,同时避免冗余工作。为此,我们采用特权学习和学习到的注意力机制,使评论家(即教师)网络具备真实地图知识,从而有效地指导策略(即学生)网络进行训练。与相关基线相比,我们的模型使团队能够将通信量减少高达两个数量级,而总行驶距离仅牺牲了2.4%,为带宽受限场景中高效的分布式多机器人探索铺平了道路。
🔬 方法详解
问题定义:多机器人探索任务中,如何在带宽受限的情况下,实现高效的分布式探索是一个关键问题。现有方法要么计算复杂度高,要么会显著降低探索效率,无法在通信效率和探索性能之间取得良好平衡。
核心思路:该论文的核心思路是让机器人学习如何有效地压缩和传递局部地图中的关键信息,并利用这些信息进行协同探索。通过学习通信策略,机器人可以避免传递冗余信息,从而降低带宽消耗。同时,利用特权学习,让评论家网络拥有全局地图信息,从而更好地指导策略网络的训练,提升探索效率。
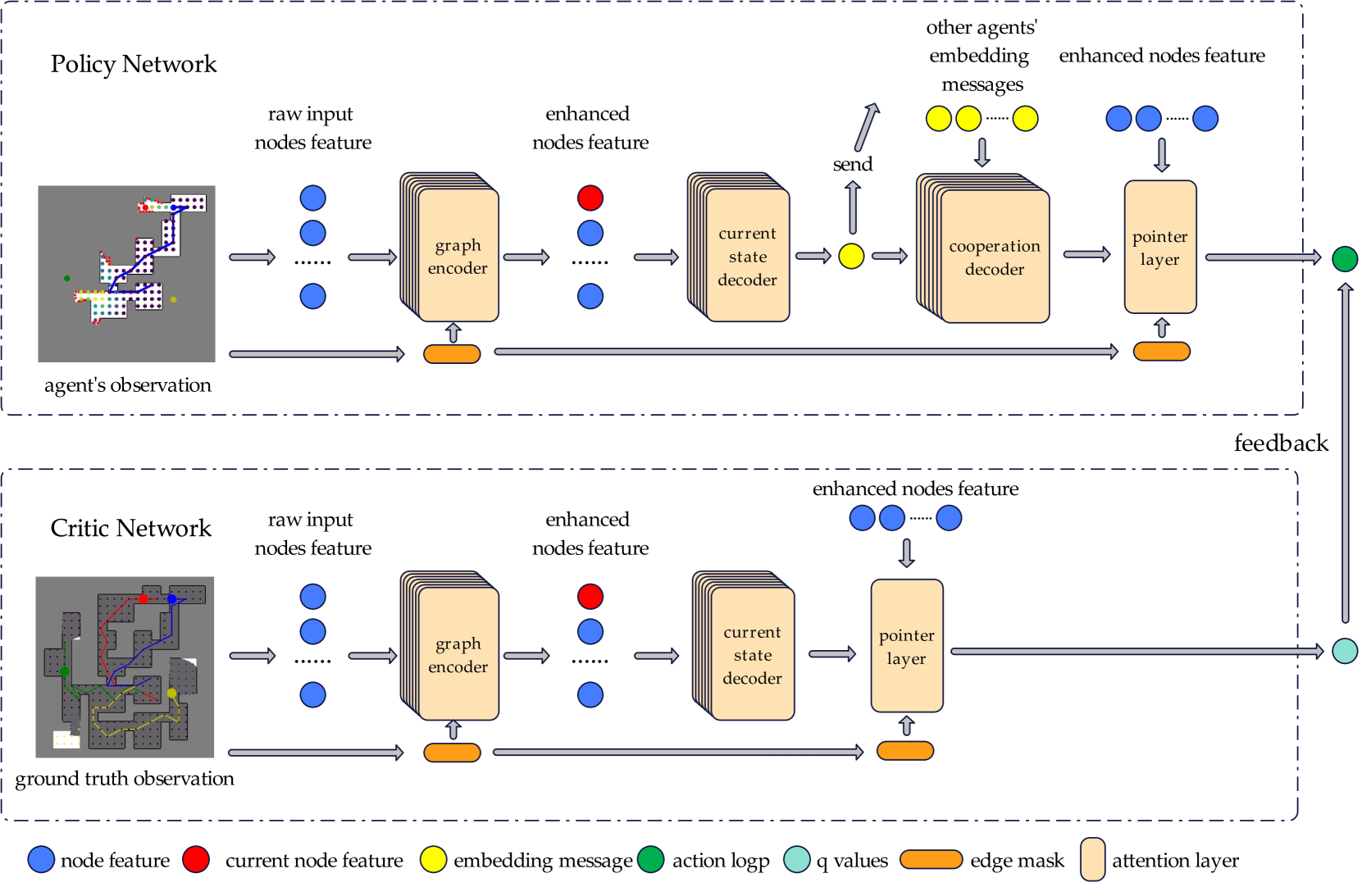
技术框架:整体框架包含多个机器人个体,每个机器人都有自己的策略网络和信念网络。策略网络负责根据当前信念和接收到的消息选择下一步动作,信念网络负责维护机器人的局部地图。此外,还有一个评论家网络,用于评估机器人的行为。训练过程中,评论家网络可以访问全局地图信息(特权信息),从而提供更准确的奖励信号。机器人之间通过通信信道传递固定大小的消息。
关键创新:该论文的关键创新在于结合了通信学习和特权强化学习。通信学习让机器人学会如何有效地压缩和传递信息,而特权强化学习则利用全局信息来指导策略网络的训练。此外,论文还使用了学习到的注意力机制,让机器人能够关注接收到的消息中的关键信息。
关键设计:论文使用了Actor-Critic架构,其中Actor网络负责学习策略,Critic网络负责评估策略。Critic网络使用了特权信息,即全局地图信息。通信信道被限制为固定大小,迫使机器人学习如何有效地压缩信息。损失函数包括探索奖励、通信惩罚和一致性损失。一致性损失鼓励机器人之间的信念保持一致。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型与基线方法相比,可以将通信量减少高达两个数量级,同时仅牺牲了2.4%的总行驶距离。这表明该方法在显著降低带宽消耗的同时,能够保持较高的探索效率。该结果验证了特权强化学习和通信学习在分布式多机器人探索中的有效性。
🎯 应用场景
该研究成果可应用于各种带宽受限的分布式多机器人探索场景,例如灾难救援、环境监测、矿产勘探等。在这些场景中,机器人需要在资源有限的环境下协同工作,快速有效地探索未知区域。该方法能够显著降低通信成本,提高探索效率,具有重要的实际应用价值。
📄 摘要(原文)
Communication bandwidth is an important consideration in multi-robot exploration, where information exchange among robots is critical. While existing methods typically aim to reduce communication throughput, they either require significant computation or significantly compromise exploration efficiency. In this work, we propose a deep reinforcement learning framework based on communication and privileged reinforcement learning to achieve a significant reduction in bandwidth consumption, while minimally sacrificing exploration efficiency. Specifically, our approach allows robots to learn to embed the most salient information from their individual belief (partial map) over the environment into fixed-sized messages. Robots then reason about their own belief as well as received messages to distributedly explore the environment while avoiding redundant work. In doing so, we employ privileged learning and learned attention mechanisms to endow the critic (i.e., teacher) network with ground truth map knowledge to effectively guide the policy (i.e., student) network during training. Compared to relevant baselines, our model allows the team to reduce communication by up to two orders of magnitude, while only sacrificing a marginal 2.4\% in total travel distance, paving the way for efficient, distributed multi-robot exploration in bandwidth-limited scenarios.