Learning a Shape-Conditioned Agent for Purely Tactile In-Hand Manipulation of Various Objects
作者: Johannes Pitz, Lennart Röstel, Leon Sievers, Darius Burschka, Berthold Bäuml
分类: cs.RO
发布日期: 2024-07-26 (更新: 2024-08-29)
💡 一句话要点
提出基于触觉反馈和形状信息的机械手灵巧操作学习框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机械手灵巧操作 触觉反馈 强化学习 形状条件策略 状态估计 物体重定向 机器人操作 泛化能力
📋 核心要点
- 现有机械手灵巧操作方法依赖视觉传感器或针对特定物体,泛化性和鲁棒性不足。
- 提出一种基于形状条件的强化学习框架,仅使用触觉反馈实现多物体操作。
- 实验表明,该方法在仿真和真实环境中均能成功重新定向多种物体,并具备良好的泛化性。
📝 摘要(中文)
本文提出了一种基于形状条件的强化学习方法,用于仅通过触觉反馈(手指关节的扭矩和位置测量)来重新定向手中的各种物体。该方法利用强化学习策略和学习的状态估计器中的形状信息。研究发现,通过一组固定基点到物体表面的向量来表示3D形状,并结合预测的3D姿态进行变换,对于学习灵巧的机械手操作特别有效。在仿真和真实世界的实验中,该方法能够以高成功率重新定向多个物体,与使用特定单物体代理获得的最新结果相当。此外,该方法还展示了对新物体的泛化能力,即使对于非凸形状,也能达到约90%的成功率。
🔬 方法详解
问题定义:现有机械手灵巧操作方法通常依赖视觉信息,这在实际应用中可能受到遮挡、光照变化等因素的影响。此外,许多方法是针对特定物体设计的,难以泛化到新的物体。因此,如何在仅依赖触觉反馈的情况下,实现对多种物体的灵巧操作是一个重要的挑战。
核心思路:本文的核心思路是利用物体的形状信息来指导机械手的操作。通过学习一个形状条件策略,使机械手能够根据物体的形状调整其操作策略。此外,该方法还学习一个状态估计器,用于从触觉反馈中估计物体的姿态。
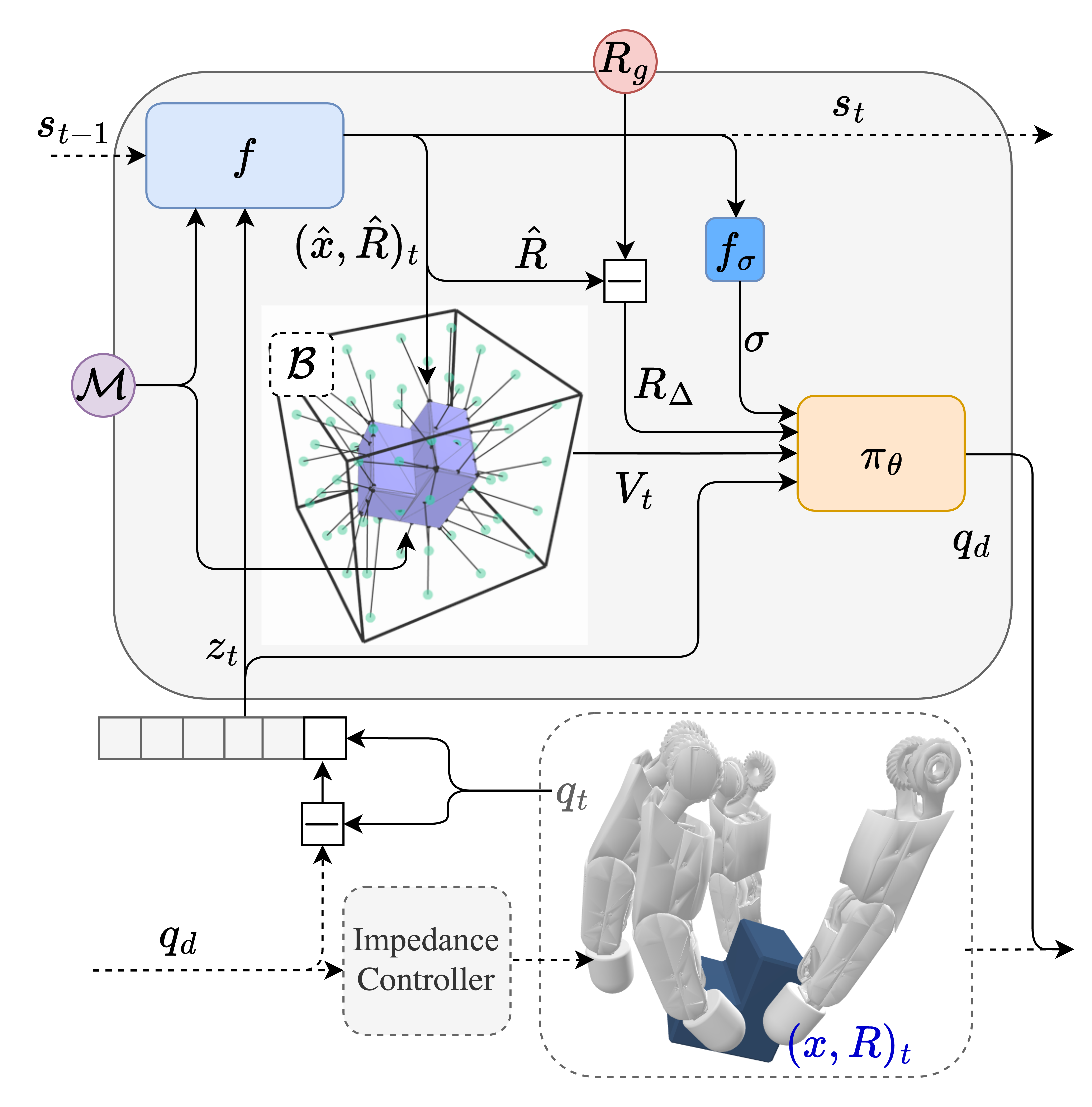
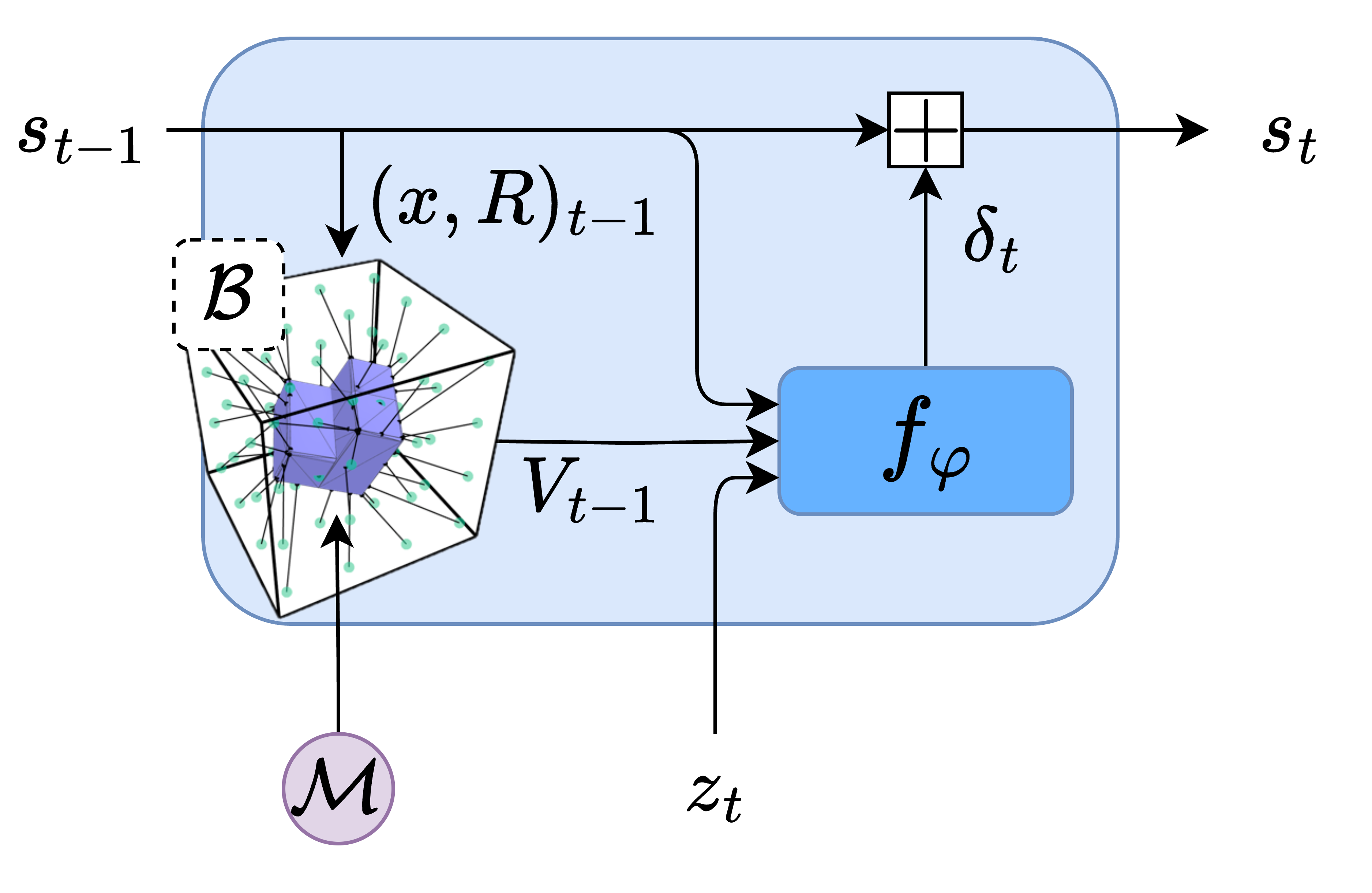
技术框架:该方法的技术框架主要包括以下几个模块:1) 形状表示模块:使用一组固定基点到物体表面的向量来表示3D形状,并结合预测的3D姿态进行变换。2) 状态估计器:从触觉反馈中估计物体的姿态。3) 强化学习策略:根据物体的形状和姿态,选择合适的动作。整个流程是,首先通过状态估计器从触觉反馈中估计物体的姿态,然后将物体的形状和姿态输入到强化学习策略中,策略输出机械手的动作,机械手执行动作后,产生新的触觉反馈,重复以上过程,直到物体达到目标姿态。
关键创新:该方法最重要的技术创新点在于将形状信息融入到强化学习策略中。通过使用形状条件策略,机械手能够根据物体的形状调整其操作策略,从而实现对多种物体的灵巧操作。与现有方法相比,该方法不需要视觉信息,并且能够泛化到新的物体。
关键设计:在形状表示方面,作者选择了一组固定的基点,并计算这些基点到物体表面的向量。这种表示方法能够有效地捕捉物体的形状信息,并且易于计算。在强化学习方面,作者使用了PPO算法,并设计了一个奖励函数,鼓励机械手将物体重新定向到目标姿态。状态估计器使用了一个神经网络,输入是触觉反馈,输出是物体的姿态。
🖼️ 关键图片
📊 实验亮点
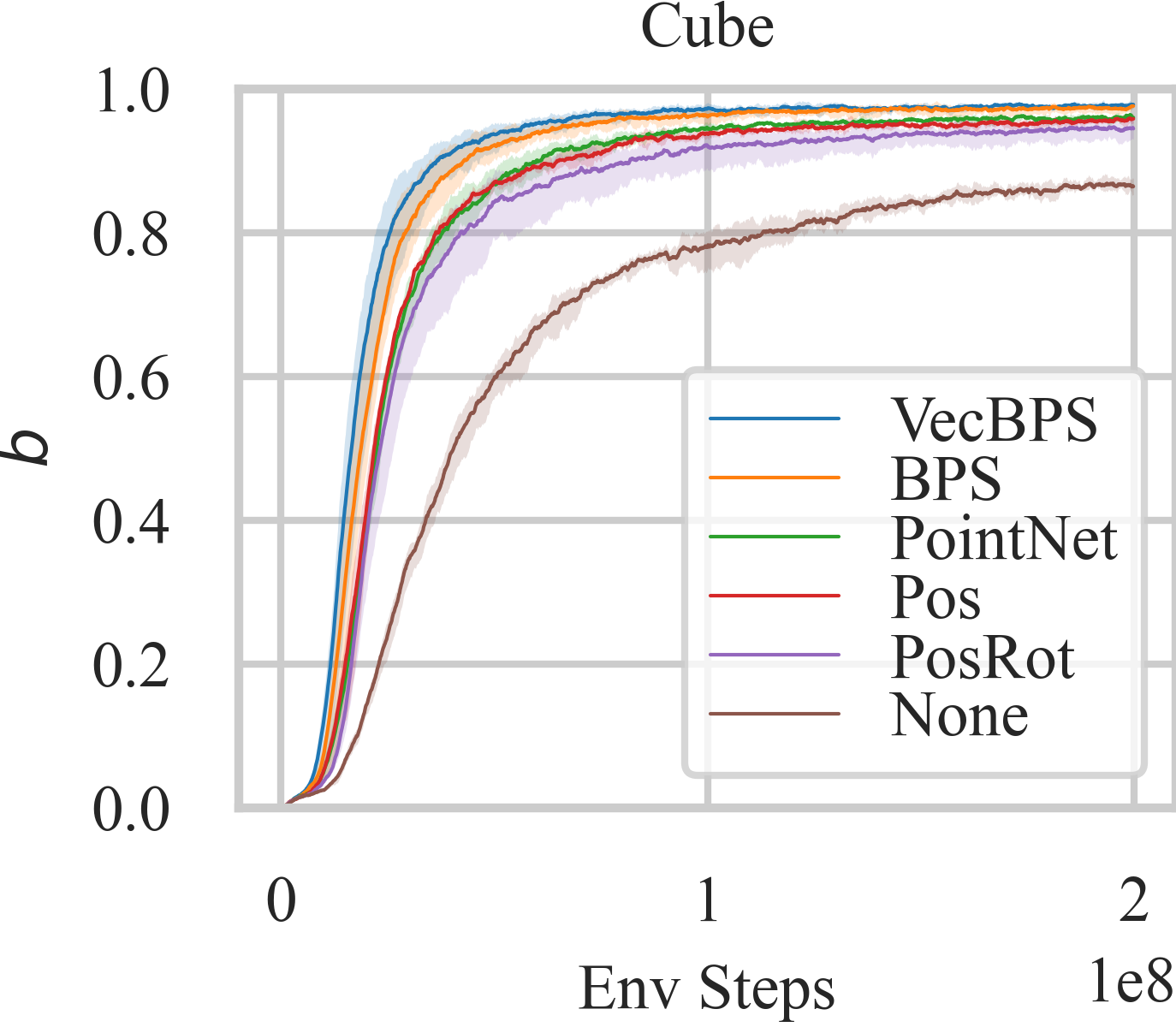
该方法在仿真和真实世界的实验中均取得了良好的效果。在真实世界实验中,该方法能够以高成功率重新定向多个物体,与使用特定单物体代理获得的最新结果相当。此外,该方法还展示了对新物体的泛化能力,即使对于非凸形状,也能达到约90%的成功率。这些结果表明,该方法具有很强的实用价值。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的场景,例如:在光线不足或存在遮挡的环境中进行物体抓取和操作;在自动化装配线上处理各种形状的零件;在医疗领域进行微创手术等。该研究有望提高机器人的自主性和适应性,使其能够更好地服务于人类。
📄 摘要(原文)
Reorienting diverse objects with a multi-fingered hand is a challenging task. Current methods in robotic in-hand manipulation are either object-specific or require permanent supervision of the object state from visual sensors. This is far from human capabilities and from what is needed in real-world applications. In this work, we address this gap by training shape-conditioned agents to reorient diverse objects in hand, relying purely on tactile feedback (via torque and position measurements of the fingers' joints). To achieve this, we propose a learning framework that exploits shape information in a reinforcement learning policy and a learned state estimator. We find that representing 3D shapes by vectors from a fixed set of basis points to the shape's surface, transformed by its predicted 3D pose, is especially helpful for learning dexterous in-hand manipulation. In simulation and real-world experiments, we show the reorientation of many objects with high success rates, on par with state-of-the-art results obtained with specialized single-object agents. Moreover, we show generalization to novel objects, achieving success rates of $\sim$90% even for non-convex shapes.