CodedVO: Coded Visual Odometry
作者: Sachin Shah, Naitri Rajyaguru, Chahat Deep Singh, Christopher Metzler, Yiannis Aloimonos
分类: cs.RO, cs.CV
发布日期: 2024-07-25
备注: 7 pages, 4 figures, IEEE ROBOTICS AND AUTOMATION LETTERS
期刊: IEEE ROBOTICS AND AUTOMATION LETTERS, 2024
💡 一句话要点
CodedVO:利用定制光学编码深度信息的单目视觉里程计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目视觉里程计 尺度模糊 定制光学 深度编码 机器人导航
📋 核心要点
- 单目视觉里程计面临尺度模糊的挑战,限制了其在机器人导航中的应用。
- CodedVO通过定制光学器件,将深度信息编码到图像中,从而显式地提供尺度信息。
- 实验表明,CodedVO在室内环境中实现了优异的里程计精度,平均轨迹误差仅为0.08米。
📝 摘要(中文)
自主机器人在里程计估计和导航方面通常依赖单目相机。然而,尺度模糊问题是有效单目视觉里程计的关键障碍。本文提出了CodedVO,一种新颖的单目视觉里程计方法,通过采用定制光学器件将度量深度信息物理编码到图像中,从而克服了尺度模糊问题。通过将此信息整合到我们的里程计流程中,我们在已知尺度的单目视觉里程计中实现了最先进的性能。我们在不同的室内环境中评估了我们的方法,并证明了其鲁棒性和适应性。在ICL-NUIM室内里程计数据集的里程计评估中,我们实现了0.08米的平均轨迹误差。
🔬 方法详解
问题定义:单目视觉里程计(VO)的核心问题之一是尺度模糊,即无法仅从单张图像确定场景的真实尺度。传统的单目VO方法通常需要复杂的后处理或外部信息来估计尺度,这增加了系统的复杂性和不确定性。现有方法在尺度估计方面存在精度不足或鲁棒性较差的痛点,尤其是在光照变化剧烈或纹理稀疏的环境中。
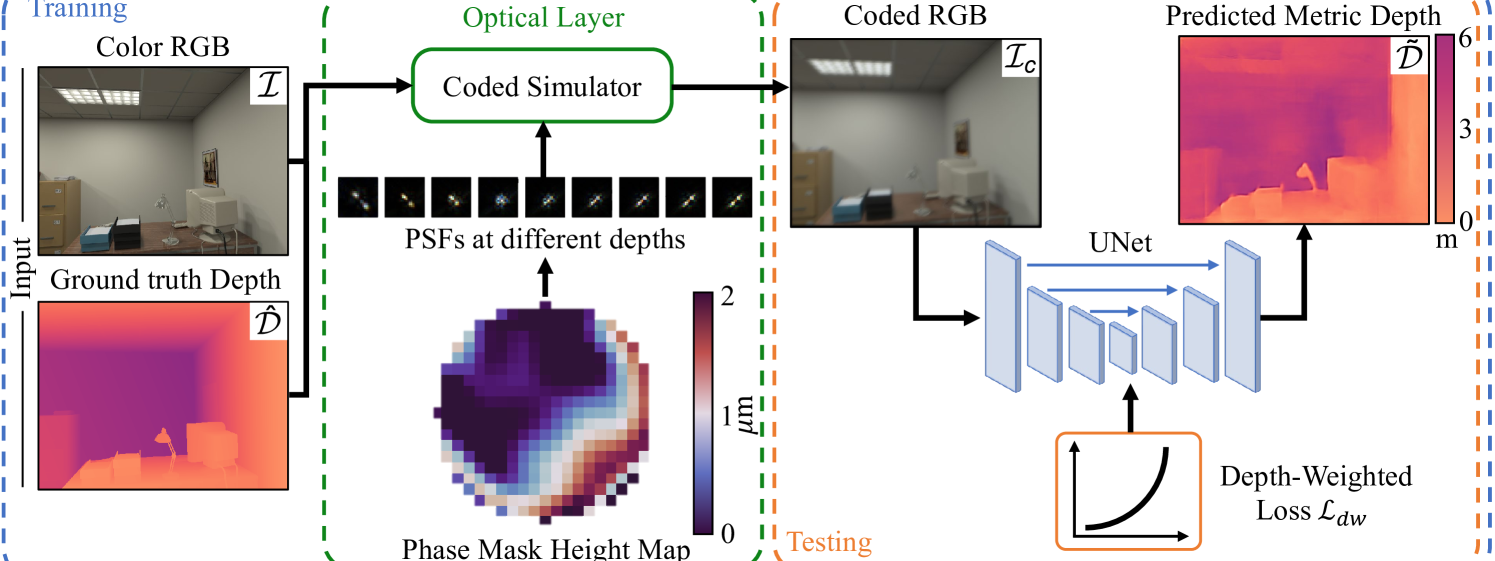
核心思路:CodedVO的核心思路是通过定制光学器件,主动地将深度信息编码到图像中。这种编码过程类似于结构光,但无需额外的投影设备,而是通过特殊设计的透镜或光栅来实现。通过分析编码后的图像,可以直接提取出像素的深度信息,从而消除尺度模糊。
技术框架:CodedVO的整体框架包括以下几个主要模块:1)图像采集模块:使用配备定制光学器件的单目相机采集图像。2)深度解码模块:对采集到的图像进行处理,提取编码的深度信息。这可能涉及到图像校正、特征提取和深度估计等步骤。3)里程计估计模块:将解码后的深度信息与图像特征相结合,使用传统的VO算法(如基于特征点或直接法)估计相机的位姿。4)优化模块:对估计的位姿进行优化,以提高里程计的精度和鲁棒性。
关键创新:CodedVO最重要的技术创新在于使用定制光学器件进行深度编码。与传统的单目VO方法相比,CodedVO无需依赖复杂的算法或外部信息来估计尺度,而是通过物理手段直接获取深度信息。这种方法具有更高的精度和鲁棒性,尤其是在光照变化剧烈或纹理稀疏的环境中。
关键设计:关于关键设计,论文中可能涉及以下细节(由于信息有限,部分内容未知):定制光学器件的具体设计(例如,透镜的形状、光栅的参数等);深度解码算法的具体实现(例如,使用的特征提取方法、深度估计模型等);里程计估计模块中使用的VO算法(例如,基于特征点的ORB-SLAM或直接法DSO);以及优化模块中使用的优化算法(例如,Bundle Adjustment)。这些细节将直接影响CodedVO的性能。
🖼️ 关键图片

📊 实验亮点
CodedVO在ICL-NUIM室内里程计数据集上进行了评估,结果表明其在单目视觉里程计中实现了最先进的性能。具体来说,CodedVO实现了0.08米的平均轨迹误差,显著优于传统的单目VO方法。这一结果表明,通过定制光学器件进行深度编码可以有效地解决尺度模糊问题,并提高单目VO的精度和鲁棒性。
🎯 应用场景
CodedVO在机器人导航、增强现实(AR)、虚拟现实(VR)等领域具有广泛的应用前景。例如,它可以用于室内服务机器人,使其能够在未知环境中进行自主导航;也可以用于AR/VR设备,提供更精确的定位和跟踪,从而增强用户体验。此外,CodedVO还可以应用于无人机、自动驾驶等领域,提高其在复杂环境中的定位精度和鲁棒性。
📄 摘要(原文)
Autonomous robots often rely on monocular cameras for odometry estimation and navigation. However, the scale ambiguity problem presents a critical barrier to effective monocular visual odometry. In this paper, we present CodedVO, a novel monocular visual odometry method that overcomes the scale ambiguity problem by employing custom optics to physically encode metric depth information into imagery. By incorporating this information into our odometry pipeline, we achieve state-of-the-art performance in monocular visual odometry with a known scale. We evaluate our method in diverse indoor environments and demonstrate its robustness and adaptability. We achieve a 0.08m average trajectory error in odometry evaluation on the ICL-NUIM indoor odometry dataset.