DexGANGrasp: Dexterous Generative Adversarial Grasping Synthesis for Task-Oriented Manipulation
作者: Qian Feng, David S. Martinez Lema, Mohammadhossein Malmir, Hang Li, Jianxiang Feng, Zhaopeng Chen, Alois Knoll
分类: cs.RO
发布日期: 2024-07-24 (更新: 2024-11-25)
备注: 8 pages, 4 figures
💡 一句话要点
提出DexGANGrasp,利用生成对抗网络合成灵巧抓取,用于面向任务的操作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧抓取 生成对抗网络 机器人操作 单视角视觉 任务导向抓取
📋 核心要点
- 现有抓取方法难以有效利用单视角信息生成稳定的灵巧抓取姿态,限制了其在真实场景中的应用。
- DexGANGrasp利用条件生成对抗网络,通过DexGenerator生成抓取姿态,并使用DexEvaluator评估其稳定性,从而实现高效的灵巧抓取。
- 实验表明,DexGANGrasp在真实世界抓取任务中,成功率显著优于基线方法,并能扩展到面向任务的抓取。
📝 摘要(中文)
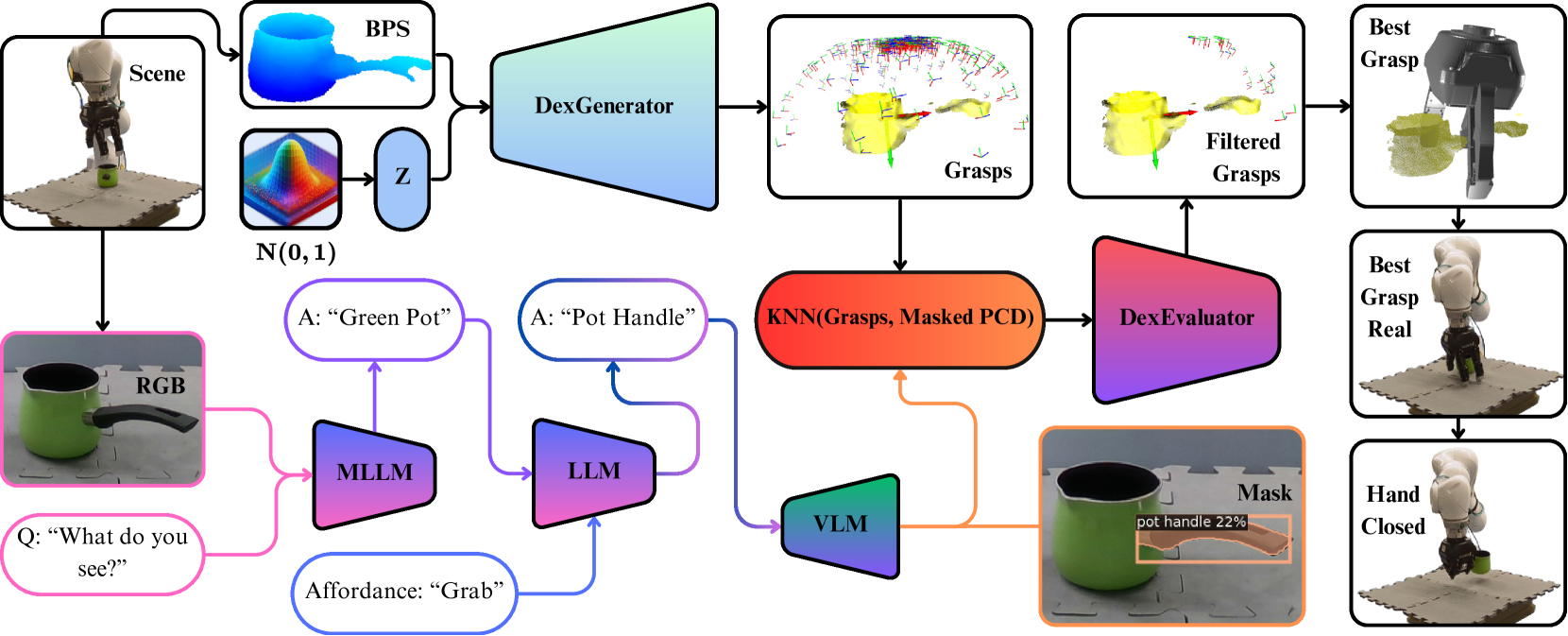
本文介绍了一种灵巧抓取合成方法DexGanGrasp,该方法能够基于单视角实时生成和评估抓取姿态。DexGanGrasp包含一个基于条件生成对抗网络(cGANs)的DexGenerator,用于生成灵巧抓取姿态,以及一个类似判别器的DexEvaluator,用于评估这些抓取姿态的稳定性。大量的仿真和真实世界实验表明了该方法的有效性,在真实世界评估中,其成功率比基线方法FFHNet高出18.57%。此外,本文还将DexGanGrasp扩展到DexAfford-Prompt,这是一个开放词汇的affordance grounding pipeline,它利用多模态大型语言模型(MLLMs)和视觉语言模型(VLMs)进行灵巧抓取,从而实现面向任务的抓取,并在真实世界中成功部署。
🔬 方法详解
问题定义:论文旨在解决机器人灵巧手在单视角条件下进行稳定抓取的问题。现有的方法,如FFHNet,在真实场景中抓取成功率较低,难以满足实际应用需求。主要痛点在于如何仅利用单视角信息,生成并评估稳定的灵巧抓取姿态。
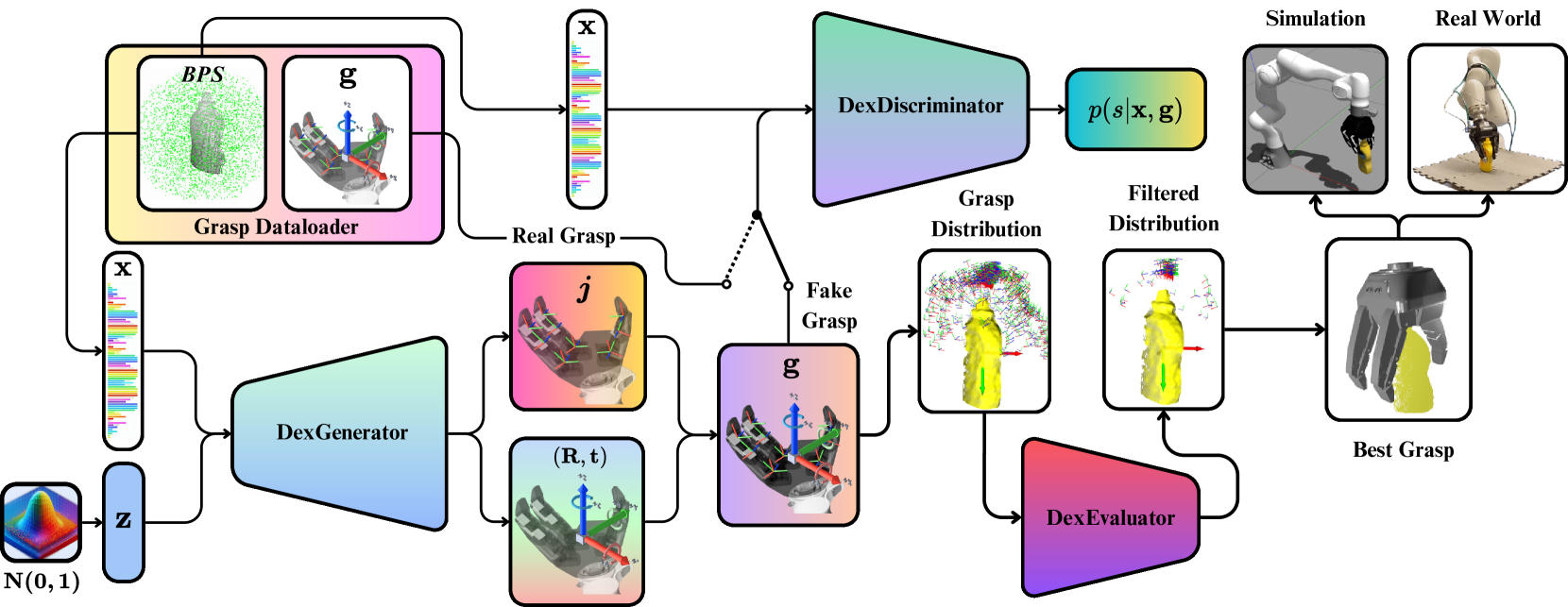
核心思路:论文的核心思路是利用生成对抗网络(GAN)学习抓取姿态的生成和评估。通过生成器(DexGenerator)生成候选抓取姿态,然后使用判别器(DexEvaluator)评估这些姿态的稳定性。这种对抗学习的方式能够使生成器生成更逼真、更稳定的抓取姿态。
技术框架:DexGANGrasp的整体框架包含两个主要模块:DexGenerator和DexEvaluator。DexGenerator是一个基于条件生成对抗网络(cGANs)的生成器,输入是单视角图像,输出是灵巧手的抓取姿态。DexEvaluator是一个类似判别器的网络,用于评估DexGenerator生成的抓取姿态的稳定性。在训练过程中,DexGenerator试图生成能够欺骗DexEvaluator的抓取姿态,而DexEvaluator则试图区分真实抓取姿态和生成的抓取姿态。
关键创新:论文的关键创新在于将生成对抗网络应用于灵巧抓取姿态的生成和评估。通过对抗学习,DexGANGrasp能够学习到更有效的抓取姿态表示,并生成更稳定的抓取姿态。与现有方法相比,DexGANGrasp能够更好地利用单视角信息,并生成更适合真实场景的抓取姿态。
关键设计:DexGenerator采用条件生成对抗网络结构,输入单视角图像,输出抓取姿态的参数。DexEvaluator采用类似判别器的网络结构,输入抓取姿态和对应的图像,输出抓取姿态的稳定性评分。论文使用了特定的损失函数来训练生成器和判别器,包括对抗损失、抓取损失和稳定性损失。具体的网络结构和参数设置在论文中有详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
DexGANGrasp在真实世界实验中表现出色,成功率比基线方法FFHNet高出18.57%。此外,该方法还成功扩展到DexAfford-Prompt,实现了基于多模态大型语言模型的面向任务的抓取。这些实验结果表明了DexGANGrasp在真实场景中的有效性和泛化能力,具有重要的实际应用价值。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的机器人应用场景,例如:工业自动化中的零件抓取和装配、家庭服务机器人中的物品整理、医疗机器人中的手术辅助等。通过结合视觉信息和语言指令,可以实现更智能、更灵活的机器人操作,提高生产效率和服务质量。未来,该技术有望进一步扩展到更复杂的任务和环境。
📄 摘要(原文)
We introduce DexGanGrasp, a dexterous grasping synthesis method that generates and evaluates grasps with single view in real time. DexGanGrasp comprises a Conditional Generative Adversarial Networks (cGANs)-based DexGenerator to generate dexterous grasps and a discriminator-like DexEvalautor to assess the stability of these grasps. Extensive simulation and real-world expriments showcases the effectiveness of our proposed method, outperforming the baseline FFHNet with an 18.57% higher success rate in real-world evaluation. We further extend DexGanGrasp to DexAfford-Prompt, an open-vocabulary affordance grounding pipeline for dexterous grasping leveraging Multimodal Large Language Models (MLLMs) and Vision Language Models (VLMs), to achieve task-oriented grasping with successful real-world deployments.