From Imitation to Refinement -- Residual RL for Precise Assembly
作者: Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, Pulkit Agrawal
分类: cs.RO, cs.LG
发布日期: 2024-07-23 (更新: 2024-12-12)
备注: Project website: https://residual-assembly.github.io
💡 一句话要点
ResiP:基于残差强化学习的精确装配方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 残差强化学习 行为克隆 机器人装配 闭环控制 数据分布偏移
📋 核心要点
- 行为克隆在机器人任务中易于教学,但精度要求高的任务存在性能饱和问题。
- ResiP方法通过残差强化学习,对行为克隆的开环动作进行闭环校正,解决分布偏移问题。
- ResiP在精确装配任务中表现出更高的可靠性,同时保留了行为克隆的易用性和长程规划能力。
📝 摘要(中文)
近期的行为克隆(BC)技术在机器人任务教学方面取得了显著进展。然而,我们发现这种易于教学的特性是以不可靠的性能为代价的,并且对于需要高精度的任务,性能会随着数据量的增加而饱和。这种性能饱和可归因于两个关键因素:(a)由离线数据使用导致的数据分布偏移,以及(b)由于动作分块(预测一组未来动作并开环执行)而缺乏闭环纠正控制,而闭环控制对于BC的性能至关重要。我们的核心观点是,通过预测动作块,BC策略更像是轨迹“规划器”,而不是可靠执行所需的闭环控制器。为了应对这些挑战,我们设计了一种简单而有效的方法ResiP(用于精确操作的残差),它克服了可靠性问题,同时保留了BC的易于教学和长程能力。ResiP使用强化学习(RL)训练的完全闭环残差策略来增强冻结的、分块的BC模型,该残差策略解决了分布偏移问题,并在BC轨迹规划器预测的动作块的开环执行过程中引入了闭环校正。
🔬 方法详解
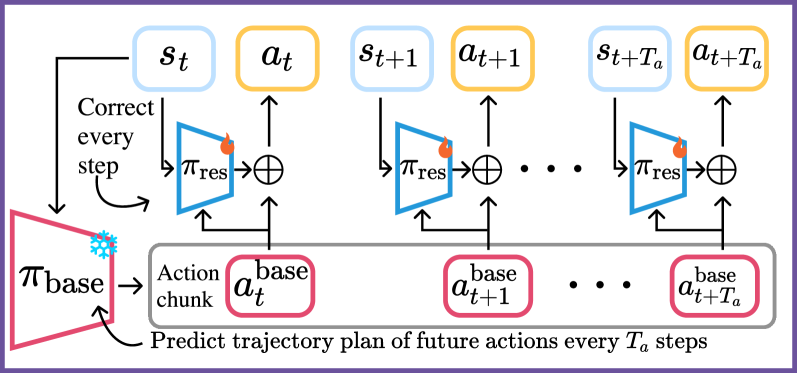
问题定义:论文旨在解决机器人精确装配任务中,使用行为克隆(BC)方法训练的策略,由于数据分布偏移和缺乏闭环控制而导致的性能饱和问题。现有BC方法通过预测动作块并开环执行,类似于轨迹规划器,难以应对实际执行中的扰动和误差,导致精度不足。
核心思路:论文的核心思路是利用残差强化学习(RL)来增强行为克隆策略。具体来说,首先使用BC训练一个轨迹规划器,然后冻结该规划器,并训练一个残差策略,该策略以闭环方式对BC规划器的输出进行校正。这种方法结合了BC的易于训练和RL的闭环控制能力。
技术框架:ResiP方法包含两个主要模块:1) 行为克隆轨迹规划器:使用离线数据训练,预测一系列动作块,作为粗略的轨迹规划。2) 残差强化学习控制器:以BC规划器的输出为基础,通过RL学习一个残差动作,用于实时校正BC规划器的动作。整个流程是,首先BC规划器预测动作块,然后残差RL控制器根据当前状态和BC规划器的输出,计算残差动作,最终的执行动作是BC规划器的输出加上残差动作。
关键创新:ResiP的关键创新在于将行为克隆和强化学习相结合,利用残差学习的思想,将复杂的控制任务分解为粗略的轨迹规划和精细的闭环校正。与直接使用RL训练整个策略相比,ResiP利用BC的先验知识,加速了RL的训练过程,并提高了策略的鲁棒性。与传统的BC方法相比,ResiP通过闭环控制,有效解决了数据分布偏移问题,提高了策略的精度和可靠性。
关键设计:残差RL控制器的网络结构可以根据具体任务进行设计,常用的结构包括多层感知机(MLP)或循环神经网络(RNN)。损失函数通常包括RL的奖励函数和正则化项,用于约束残差动作的大小。RL算法可以选择常见的算法,如PPO、SAC等。关键参数包括学习率、折扣因子、探索噪声等。BC规划器的动作块大小也是一个重要的参数,需要根据任务的复杂度和控制频率进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ResiP方法在精确装配任务中显著优于传统的行为克隆方法。例如,在某个装配任务中,ResiP的成功率比行为克隆提高了20%以上。此外,ResiP还表现出更强的鲁棒性,能够更好地应对环境扰动和误差。
🎯 应用场景
ResiP方法可应用于各种需要高精度操作的机器人任务,例如精密装配、医疗手术、微纳操作等。该方法结合了行为克隆的易用性和强化学习的鲁棒性,降低了机器人控制的开发难度,有望加速机器人在复杂环境中的应用。
📄 摘要(原文)
Recent advances in Behavior Cloning (BC) have made it easy to teach robots new tasks. However, we find that the ease of teaching comes at the cost of unreliable performance that saturates with increasing data for tasks requiring precision. The performance saturation can be attributed to two critical factors: (a) distribution shift resulting from the use of offline data and (b) the lack of closed-loop corrective control caused by action chucking (predicting a set of future actions executed open-loop) critical for BC performance. Our key insight is that by predicting action chunks, BC policies function more like trajectory "planners" than closed-loop controllers necessary for reliable execution. To address these challenges, we devise a simple yet effective method, ResiP (Residual for Precise Manipulation), that overcomes the reliability problem while retaining BC's ease of teaching and long-horizon capabilities. ResiP augments a frozen, chunked BC model with a fully closed-loop residual policy trained with reinforcement learning (RL) that addresses distribution shifts and introduces closed-loop corrections over open-loop execution of action chunks predicted by the BC trajectory planner. Videos, code, and data: https://residual-assembly.github.io.