Optimizing Robotic Manipulation with Decision-RWKV: A Recurrent Sequence Modeling Approach for Lifelong Learning
作者: Yujian Dong, Tianyu Wu, Chaoyang Song
分类: cs.RO
发布日期: 2024-07-23
备注: 14 pages, 7 figures, 1 table, submitted to the Special Issue on Large Language Models In Design And Manufacturing in the Journal of Computing and Information Science in Engineering, see https://github.com/ancorasir/DecisionRWKV
🔗 代码/项目: GITHUB
💡 一句话要点
提出Decision-RWKV模型,用于优化机器人操作中的终身学习序列决策问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 终身学习 序列建模 决策Transformer RWKV
📋 核心要点
- 传统机器学习算法在机器人部署中面临灾难性遗忘问题,阻碍了机器人获得多样化和泛化的能力。
- 本文提出Decision-RWKV模型,利用RWKV在序列建模方面的优势,结合决策Transformer和经验回放机制,提升机器人终身学习能力。
- 实验结果表明,DRWKV模型在单任务和终身学习场景中均表现出高效处理多个子任务的能力,验证了其有效性。
📝 摘要(中文)
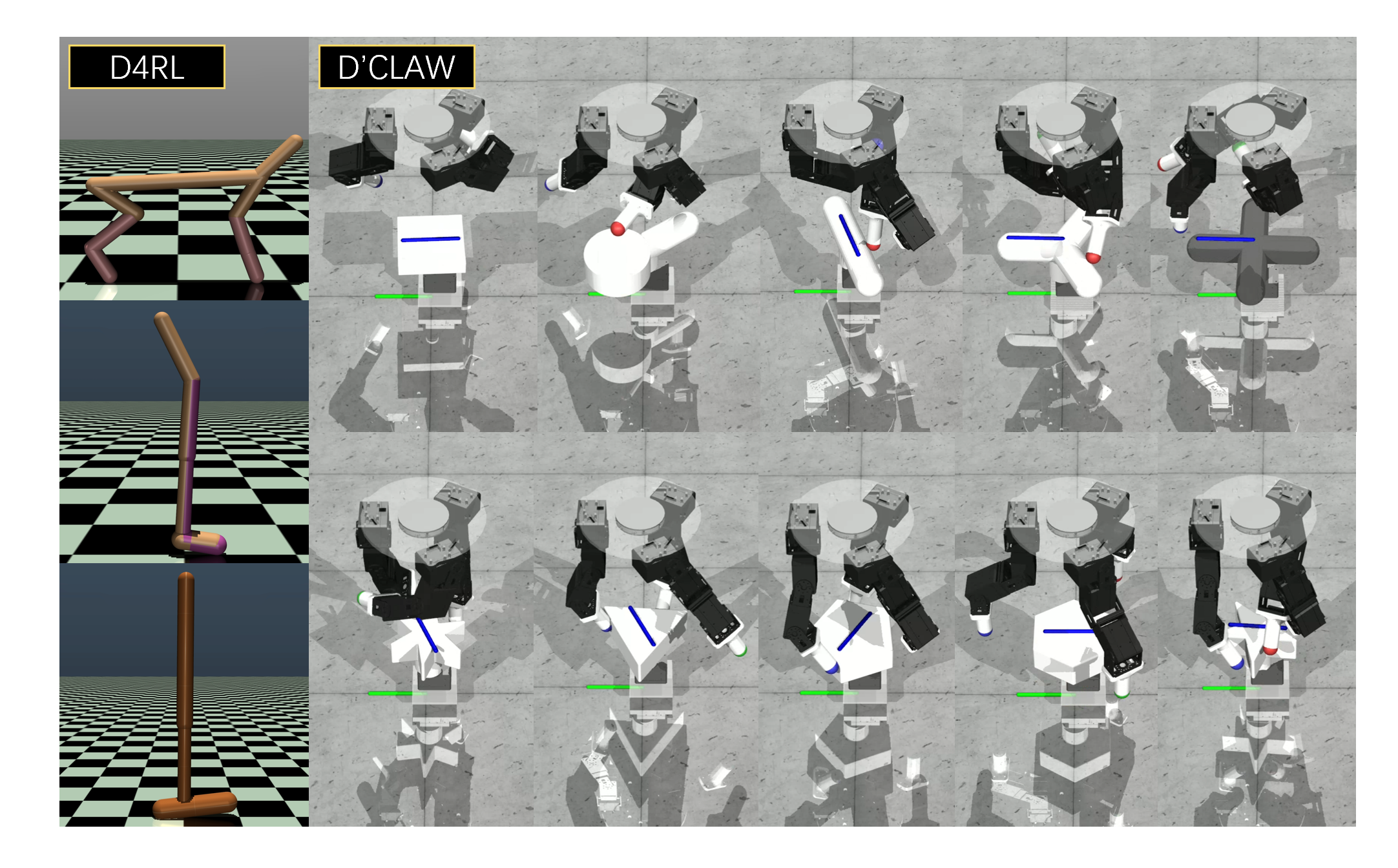
本文研究了Receptance Weighted Key Value (RWKV) 框架,该框架以其在高效序列建模方面的先进能力而闻名,并将其与决策Transformer和经验回放架构相结合。研究重点在于提升序列决策和终身机器人学习任务中的潜在性能。我们引入了Decision-RWKV (DRWKV) 模型,并在OpenAI Gym环境中使用D4RL数据库以及在D'Claw平台上进行了大量实验,以评估DRWKV模型在单任务测试和终身学习场景中的性能,展示了其有效处理多个子任务的能力。本文所有算法、训练和图像渲染的代码均已开源。
🔬 方法详解
问题定义:论文旨在解决机器人操作中的终身学习问题,即机器人需要在不断变化的环境中持续学习新的技能,同时避免遗忘已学技能。现有方法,特别是基于Transformer的模型,虽然在很多领域表现出色,但在机器人终身学习中面临灾难性遗忘的挑战。
核心思路:论文的核心思路是将RWKV架构引入到决策Transformer框架中。RWKV是一种循环序列模型,具有高效的序列建模能力和良好的长期记忆特性,这有助于缓解灾难性遗忘问题。通过结合RWKV和决策Transformer,模型可以更好地处理序列决策任务,并在终身学习过程中保持已学知识。
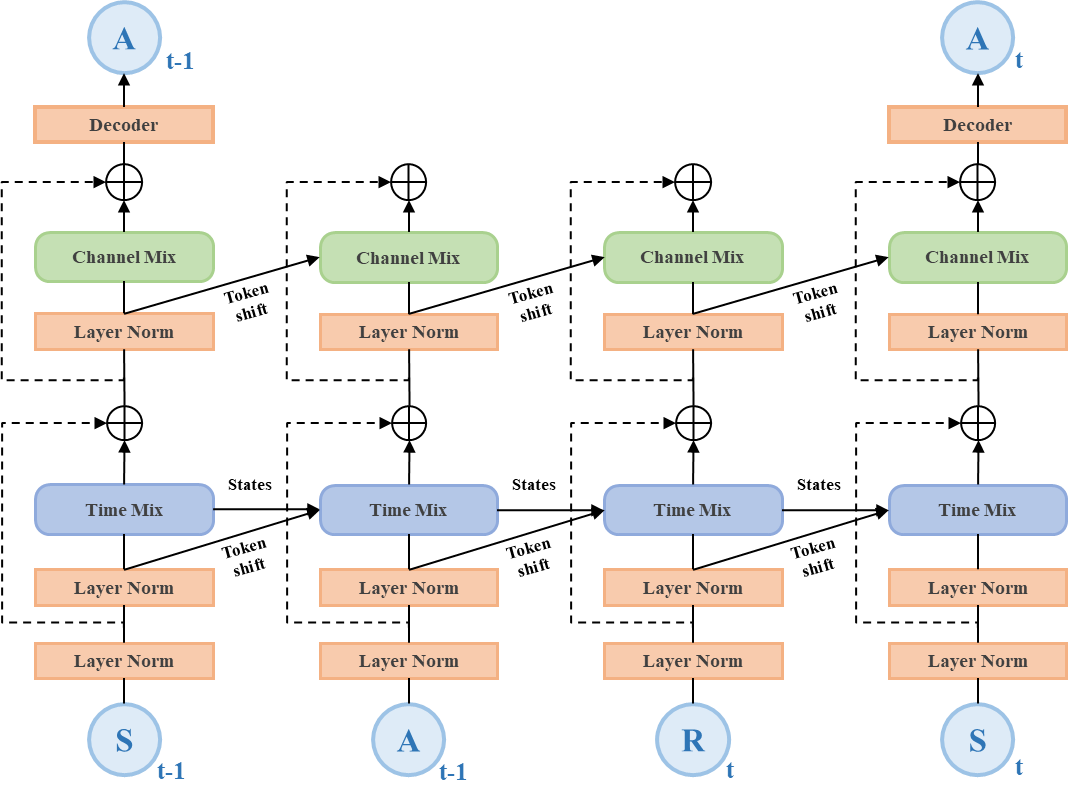
技术框架:Decision-RWKV (DRWKV) 模型基于决策Transformer架构,并用RWKV模块替换了原始的Transformer中的自注意力机制。整体流程包括:1) 收集机器人与环境交互的数据,并存储在经验回放缓冲区中;2) 从经验回放缓冲区中采样数据,包括状态、动作和奖励;3) 将采样的数据输入到DRWKV模型中进行训练,模型通过学习历史经验来预测未来的动作;4) 将预测的动作发送给机器人执行,并观察环境的反馈;5) 将新的经验添加到经验回放缓冲区中,并重复以上步骤。
关键创新:最重要的技术创新点在于将RWKV架构引入到决策Transformer框架中。与传统的Transformer相比,RWKV具有更高效的序列建模能力和更好的长期记忆特性,这使得DRWKV模型能够更好地处理序列决策任务,并在终身学习过程中保持已学知识。此外,论文还针对机器人操作任务对RWKV进行了优化,使其更适合于处理机器人控制问题。
关键设计:论文中没有明确给出关键参数设置和损失函数的具体细节,这部分信息未知。但是,可以推测,RWKV模块中的一些关键参数,如状态向量的维度、时间衰减参数等,会对模型的性能产生重要影响。此外,损失函数的设计也至关重要,需要能够有效地指导模型学习最优策略,并避免灾难性遗忘。
🖼️ 关键图片

📊 实验亮点
论文通过在D4RL数据库和D'Claw平台上进行的大量实验,验证了DRWKV模型的有效性。实验结果表明,DRWKV模型在单任务测试和终身学习场景中均表现出高效处理多个子任务的能力。具体的性能数据和对比基线未知,但论文强调了DRWKV模型在处理多个子任务方面的优势。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过利用DRWKV模型,机器人可以不断学习新的技能,适应不断变化的环境,从而提高其工作效率和智能化水平。此外,该研究还有助于推动机器人终身学习领域的发展,为实现更智能、更自主的机器人奠定基础。
📄 摘要(原文)
Models based on the Transformer architecture have seen widespread application across fields such as natural language processing, computer vision, and robotics, with large language models like ChatGPT revolutionizing machine understanding of human language and demonstrating impressive memory and reproduction capabilities. Traditional machine learning algorithms struggle with catastrophic forgetting, which is detrimental to the diverse and generalized abilities required for robotic deployment. This paper investigates the Receptance Weighted Key Value (RWKV) framework, known for its advanced capabilities in efficient and effective sequence modeling, and its integration with the decision transformer and experience replay architectures. It focuses on potential performance enhancements in sequence decision-making and lifelong robotic learning tasks. We introduce the Decision-RWKV (DRWKV) model and conduct extensive experiments using the D4RL database within the OpenAI Gym environment and on the D'Claw platform to assess the DRWKV model's performance in single-task tests and lifelong learning scenarios, showcasing its ability to handle multiple subtasks efficiently. The code for all algorithms, training, and image rendering in this study is open-sourced at https://github.com/ancorasir/DecisionRWKV.