Simultaneous Localization and Affordance Prediction of Tasks from Egocentric Video
作者: Zachary Chavis, Hyun Soo Park, Stephen J. Guy
分类: cs.RO, cs.CV
发布日期: 2024-07-18 (更新: 2025-06-12)
💡 一句话要点
提出空间扩展的视觉-语言模型,用于从自我中心视频中同步定位任务并预测其可供性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视觉-语言模型 自我中心视频 任务可供性 空间推理 机器人导航
📋 核心要点
- 现有的视觉-语言模型(VLMs)在理解图像中的物体和动作方面表现出色,但缺乏对任务发生位置的空间推理能力。
- 该论文通过引入空间扩展,利用自我中心视频来增强VLM,使其能够理解任务的空间可供性以及任务相对于观察者的位置。
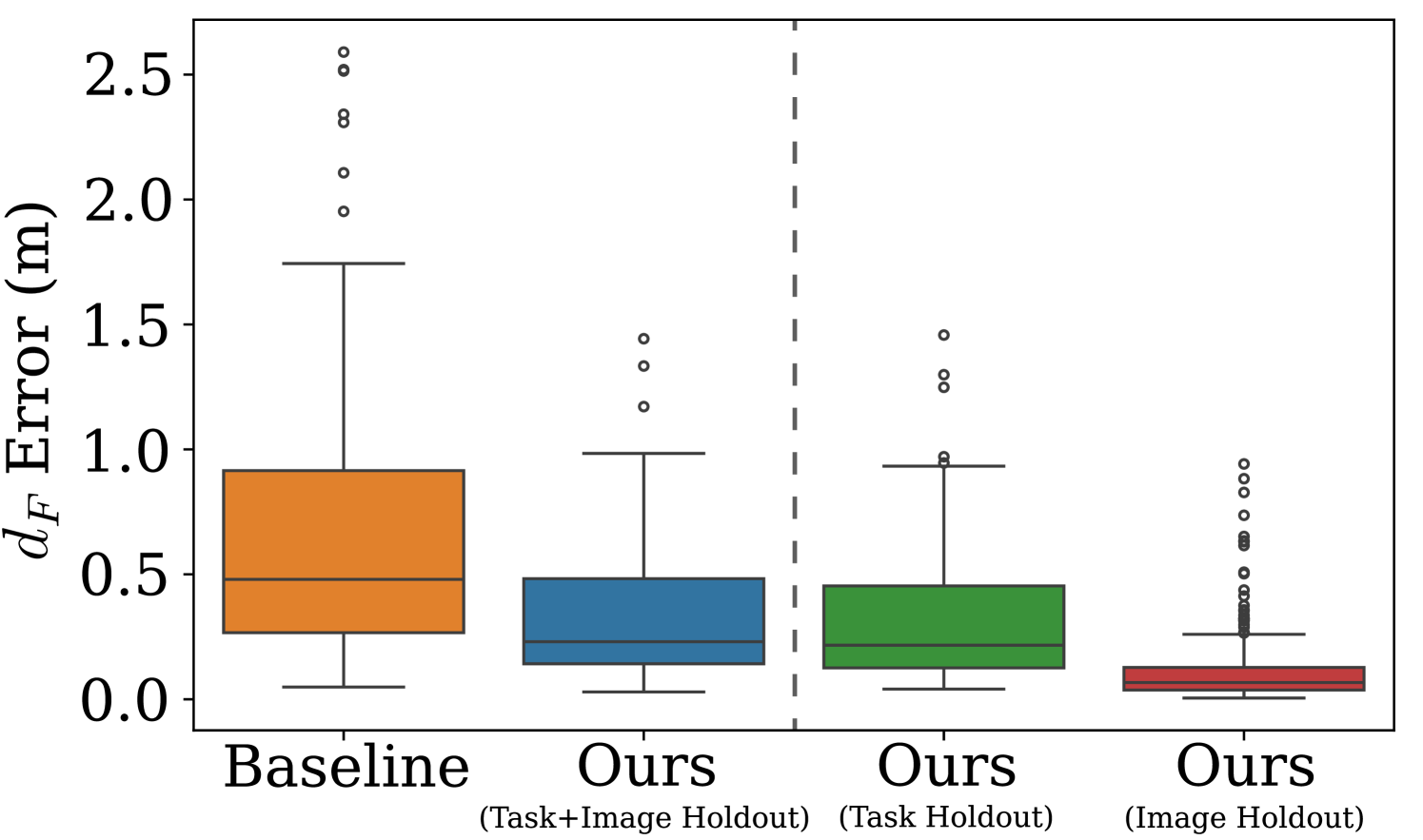
- 实验结果表明,该方法在预测任务发生位置和基于位置预测任务方面,均优于直接使用VLM的基线方法。
📝 摘要(中文)
视觉-语言模型(VLMs)已在各个领域作为下游视觉和自然语言应用的基础模型取得了巨大成功。然而,这些模型仅限于对图像平面上当前可见的物体和动作进行推理。本文提出了一种VLM的空间扩展,它利用空间定位的自我中心视频演示,通过两种方式增强VLM:理解空间任务可供性,即智能体必须位于何处才能实际执行任务;以及相对于自我中心观察者的任务定位。实验表明,本文方法优于使用VLM来映射任务描述与一组位置标记图像的相似性的基线方法,在预测任务可能发生的位置和预测当前位置可能发生的任务方面,误差都更小。由此产生的表示将使机器人能够使用自我中心感知来导航到或绕过自然语言指定的新任务的感兴趣物理区域。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)无法理解任务的空间上下文的问题。现有的VLMs主要关注图像中物体的识别和动作的理解,而忽略了任务发生的必要空间位置,这限制了它们在机器人导航和任务规划等领域的应用。例如,一个机器人需要知道“做饭”这个任务通常发生在厨房,并且需要靠近炉灶才能完成。
核心思路:论文的核心思路是通过引入空间信息来扩展VLMs,使其能够理解任务的空间可供性,即任务发生的必要空间位置。具体来说,论文利用带有空间定位信息的自我中心视频演示来训练模型,使模型能够学习任务描述与空间位置之间的关系。这样,模型就可以根据任务描述预测任务可能发生的空间位置,或者根据当前位置预测可能发生的任务。
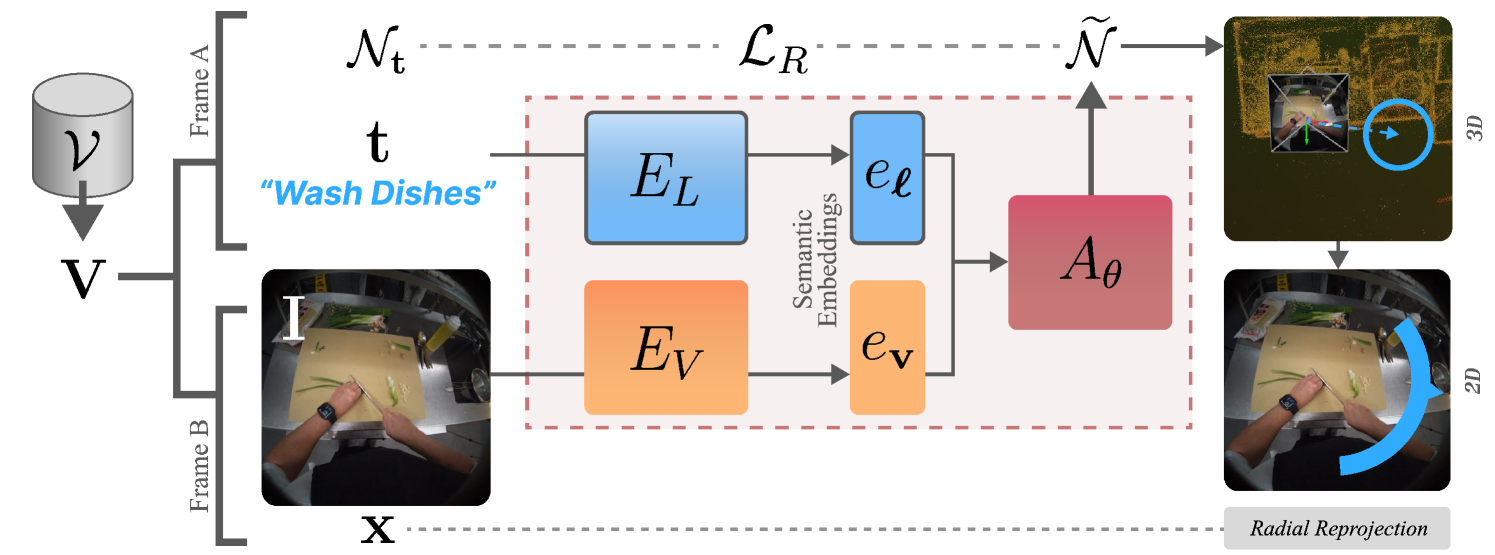
技术框架:该方法的技术框架主要包括以下几个模块:1) 自我中心视频数据收集:收集带有空间位置标签的自我中心视频,用于训练模型。2) 视觉-语言模型(VLM):使用预训练的VLM作为基础模型,例如CLIP。3) 空间编码器:将空间位置信息编码为向量表示。4) 任务可供性预测模块:将任务描述和空间位置编码作为输入,预测任务在该位置发生的可行性。5) 任务定位模块:根据自我中心视频帧预测任务相对于观察者的位置。整体流程是,首先利用自我中心视频数据训练模型,然后使用训练好的模型进行任务可供性预测和任务定位。
关键创新:该论文的关键创新在于将空间信息融入到视觉-语言模型中,使其能够理解任务的空间上下文。与现有方法相比,该方法不仅能够识别图像中的物体和动作,还能够预测任务发生的空间位置,从而提高了模型在机器人导航和任务规划等领域的应用能力。
关键设计:论文的关键设计包括:1) 使用自我中心视频数据进行训练,因为自我中心视频能够提供丰富的空间信息。2) 使用空间编码器将空间位置信息编码为向量表示,以便与视觉和语言特征进行融合。3) 设计任务可供性预测模块和任务定位模块,分别用于预测任务发生的空间位置和任务相对于观察者的位置。具体的损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
该论文通过实验验证了所提出方法的有效性。实验结果表明,该方法在预测任务发生位置和基于位置预测任务方面,均优于使用VLM直接映射任务描述与位置标记图像相似度的基线方法。具体的性能提升数据在摘要中没有给出,属于未知信息。
🎯 应用场景
该研究成果可应用于机器人导航、任务规划、人机交互等领域。例如,机器人可以利用该模型理解用户的自然语言指令,并导航到合适的地点执行任务。在人机交互方面,该模型可以根据用户的当前位置和任务需求,推荐相关的操作或信息。未来,该技术有望应用于智能家居、自动驾驶等领域,提升智能化水平。
📄 摘要(原文)
Vision-Language Models (VLMs) have shown great success as foundational models for downstream vision and natural language applications in a variety of domains. However, these models are limited to reasoning over objects and actions currently visible on the image plane. We present a spatial extension to the VLM, which leverages spatially-localized egocentric video demonstrations to augment VLMs in two ways -- through understanding spatial task-affordances, i.e. where an agent must be for the task to physically take place, and the localization of that task relative to the egocentric viewer. We show our approach outperforms the baseline of using a VLM to map similarity of a task's description over a set of location-tagged images. Our approach has less error both on predicting where a task may take place and on predicting what tasks are likely to happen at the current location. The resulting representation will enable robots to use egocentric sensing to navigate to, or around, physical regions of interest for novel tasks specified in natural language.