Robotic Arm Manipulation with Inverse Reinforcement Learning & TD-MPC
作者: Md Shoyib Hassan, Sabir Md Sanaullah
分类: cs.RO
发布日期: 2024-07-17 (更新: 2024-08-07)
备注: 10 pages, 13 figures
💡 一句话要点
提出基于视觉的逆强化学习与TD-MPC的机器人手臂操作方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 机器人操作 模型预测控制 视觉学习 TD-MPC
📋 核心要点
- 现有方法难以将基于模型的逆强化学习扩展到具有复杂动力学的真实机器人操作任务。
- 该论文提出了一种基于梯度的逆强化学习框架,仅从视觉演示中学习成本函数。
- 通过TD视觉模型预测控制优化轨迹,并在硬件上验证了对象操作任务的有效性。
📝 摘要(中文)
一个尚未解决的问题是如何将基于模型的逆强化学习(IRL)扩展到具有不可预测动力学的实际机器人操作任务中。主要障碍包括:从视觉和本体感受示例中学习的能力,创建可扩展到高维状态空间的算法,以及掌握强大的动力学模型。本文提出了一种基于梯度的逆强化学习框架,该框架仅从视觉人类演示中学习成本函数。然后,使用TD视觉模型预测控制(MPC)和学习到的成本函数来优化所展示的行为和轨迹。我们在硬件上使用基本的对象操作任务测试了我们的系统。
🔬 方法详解
问题定义:论文旨在解决机器人手臂操作中,如何仅通过视觉演示学习成本函数,并利用学习到的成本函数控制机器人完成复杂操作的问题。现有方法的痛点在于难以处理高维状态空间和不可预测的动力学,并且通常需要本体感受信息,限制了其在实际场景中的应用。
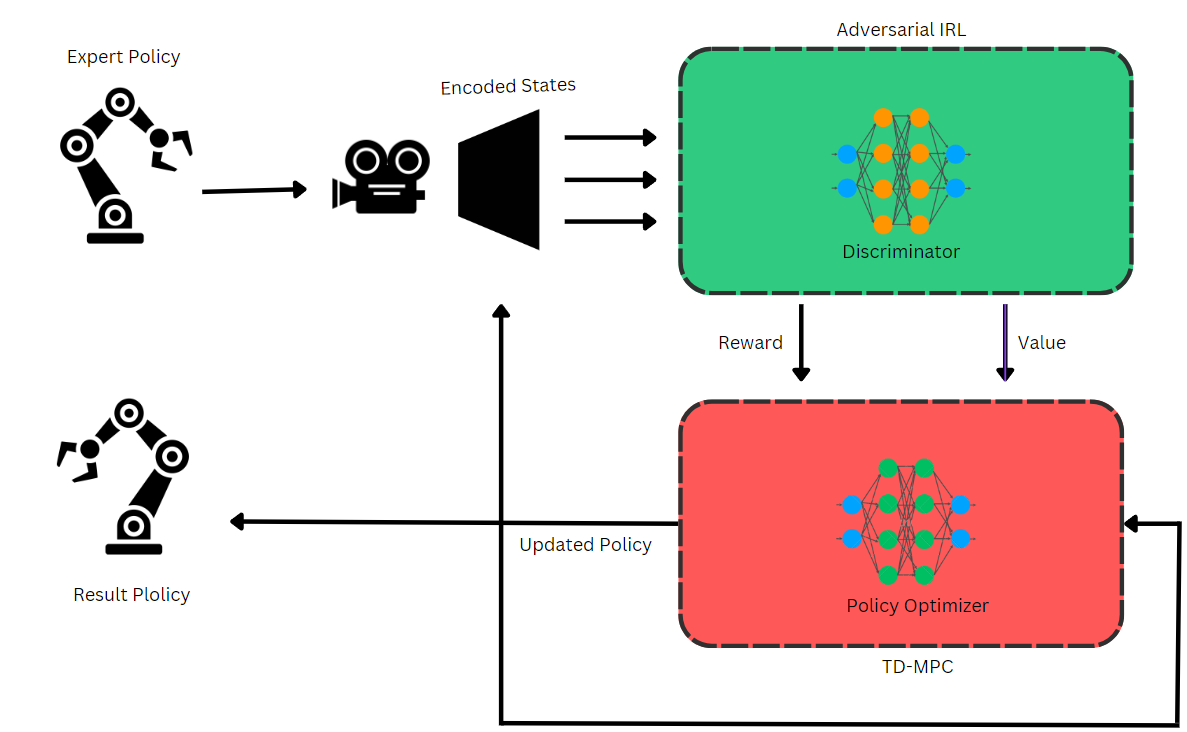
核心思路:论文的核心思路是利用逆强化学习(IRL)从人类视觉演示中学习成本函数,然后使用模型预测控制(MPC)根据学习到的成本函数优化机器人的运动轨迹。通过这种方式,机器人可以模仿人类的操作行为,而无需显式地建模复杂的动力学。
技术框架:整体框架包含两个主要阶段:1) 逆强化学习阶段:从人类视觉演示中学习成本函数。该阶段使用基于梯度的优化方法,直接从视觉数据中估计成本函数参数。2) 模型预测控制阶段:使用学习到的成本函数,通过TD视觉模型预测控制(TD-MPC)优化机器人的运动轨迹。TD-MPC利用视觉信息进行状态估计和预测,从而实现对机器人运动的精确控制。
关键创新:最重要的技术创新点在于提出了一种完全基于视觉的逆强化学习框架,该框架可以直接从视觉演示中学习成本函数,而无需依赖本体感受信息。此外,结合TD-MPC,实现了对机器人运动轨迹的精确控制,克服了传统MPC方法对精确动力学模型的依赖。
关键设计:论文中关键的设计包括:1) 使用深度神经网络来表示成本函数,并使用梯度下降法进行优化。2) 采用TD-MPC作为控制策略,利用视觉信息进行状态估计和预测。3) 针对具体的机器人操作任务,设计了合适的奖励函数和状态空间表示。
🖼️ 关键图片

📊 实验亮点
该论文在真实的机器人硬件平台上进行了实验验证,展示了该方法在对象操作任务中的有效性。虽然论文中没有给出具体的性能数据和对比基线,但实验结果表明,该方法可以使机器人成功地模仿人类的操作行为,完成各种复杂的操作任务。未来的工作可以进一步量化性能提升,并与其他基线方法进行比较。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过学习人类的视觉演示,机器人可以完成各种复杂的操作任务,提高生产效率和服务质量。此外,该方法还可以扩展到其他类型的机器人,例如无人机、无人车等,实现更智能化的自主控制。
📄 摘要(原文)
One unresolved issue is how to scale model-based inverse reinforcement learning (IRL) to actual robotic manipulation tasks with unpredictable dynamics. The ability to learn from both visual and proprioceptive examples, creating algorithms that scale to high-dimensional state-spaces, and mastering strong dynamics models are the main obstacles. In this work, we provide a gradient-based inverse reinforcement learning framework that learns cost functions purely from visual human demonstrations. The shown behavior and the trajectory is then optimized using TD visual model predictive control(MPC) and the learned cost functions. We test our system using fundamental object manipulation tasks on hardware.