Contact-conditioned learning of multi-gait locomotion policies
作者: Michal Ciebielski, Federico Burgio, Majid Khadiv
分类: cs.RO
发布日期: 2024-07-16 (更新: 2025-03-07)
💡 一句话要点
提出接触条件多步态运动策略学习方法,提升泛化性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多步态运动 强化学习 腿式机器人 接触条件 策略学习
📋 核心要点
- 现有方法在多步态运动策略学习中泛化性不足,难以适应复杂环境。
- 论文提出基于未来接触切换条件的策略学习方法,利用步态间的共享结构。
- 实验表明,该方法在双足和四足机器人上学习多种步态有效,泛化性更强。
📝 摘要(中文)
本文研究了目标表示对腿式机器人多步态策略学习的性能和泛化能力的影响。为了单独研究这个问题,我们将策略学习问题转化为模仿能够生成多种步态的模型预测控制器。我们假设,将学习到的策略建立在未来的接触切换条件之上,是学习能够生成各种步态的单一策略的合适目标表示。我们的理由是,以接触信息为条件的策略可以利用不同步态之间的共享结构。大量的仿真结果表明,我们的假设对于学习双足和四足机器人的多种步态是有效的。最有趣的是,我们的结果表明,当机器人在训练数据分布之外进行测试时,接触条件策略比文献中其他常见的目标表示具有更好的泛化能力。
🔬 方法详解
问题定义:论文旨在解决腿式机器人多步态运动策略学习中的泛化性问题。现有方法难以在训练数据分布之外的环境中保持良好的性能,尤其是在步态切换和地形变化时。这些方法通常依赖于特定的目标表示,例如目标位置或速度,但这些表示可能无法充分捕捉不同步态之间的共性,导致策略难以泛化。
核心思路:论文的核心思路是将学习到的策略以未来的接触切换作为条件。作者认为,不同步态之间存在共享的结构,而接触信息能够有效地捕捉这些结构。通过将策略与接触信息关联起来,可以使策略更好地理解不同步态之间的关系,从而提高泛化能力。这种方法允许机器人根据环境和任务需求,灵活地切换不同的步态。
技术框架:整体框架包括一个模型预测控制器(MPC)和一个接触条件策略网络。首先,使用MPC生成多种步态的运动轨迹,作为训练数据。然后,训练一个神经网络,该网络以当前状态和未来的接触信息作为输入,输出控制指令。接触信息通过预测未来一段时间内的足端接触状态来表示。训练完成后,该网络可以直接用于控制机器人,实现多步态运动。
关键创新:论文的关键创新在于将接触信息作为条件,用于多步态运动策略的学习。与传统的基于目标位置或速度的策略学习方法相比,该方法能够更好地捕捉不同步态之间的共性,从而提高泛化能力。此外,该方法还能够使机器人根据环境和任务需求,灵活地切换不同的步态。
关键设计:接触信息通过预测未来一段时间内的足端接触状态来表示,例如,可以使用一个二元向量来表示每个足端在未来几个时间步内的接触状态。策略网络可以使用循环神经网络(RNN)或Transformer等结构,以处理时序信息。损失函数可以包括模仿损失(用于模仿MPC的输出)和正则化项(用于防止过拟合)。具体的参数设置和网络结构需要根据具体的机器人和任务进行调整。
🖼️ 关键图片


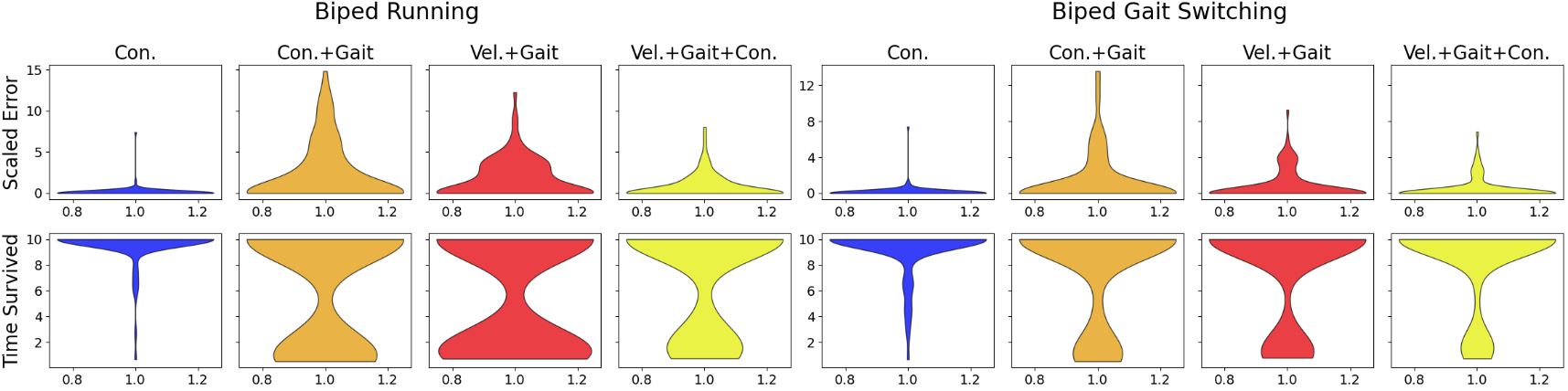
📊 实验亮点
实验结果表明,接触条件策略在双足和四足机器人上均能有效地学习多种步态。与基于目标位置或速度的策略相比,接触条件策略在训练数据分布之外的环境中具有更好的泛化能力。例如,在地形变化和步态切换等情况下,接触条件策略能够保持较高的运动性能,而其他策略则可能出现明显的性能下降。
🎯 应用场景
该研究成果可应用于各种腿式机器人,例如双足人形机器人、四足机器人等,使其能够在复杂地形和动态环境中实现稳定、高效的运动。例如,可用于搜救机器人、物流机器人、巡检机器人等,提高其在实际应用中的适应性和可靠性。此外,该方法还可以扩展到其他类型的机器人,例如多足机器人和蛇形机器人。
📄 摘要(原文)
In this paper, we examine the effects of goal representation on the performance and generalization in multi-gait policy learning settings for legged robots. To study this problem in isolation, we cast the policy learning problem as imitating model predictive controllers that can generate multiple gaits. We hypothesize that conditioning a learned policy on future contact switches is a suitable goal representation for learning a single policy that can generate a variety of gaits. Our rationale is that policies conditioned on contact information can leverage the shared structure between different gaits. Our extensive simulation results demonstrate the validity of our hypothesis for learning multiple gaits on a bipedal and a quadrupedal robot. Most interestingly, our results show that contact-conditioned policies generalize much better than other common goal representations in the literature, when the robot is tested outside the distribution of the training data.