Towards Interpretable Visuo-Tactile Predictive Models for Soft Robot Interactions
作者: Enrico Donato, Thomas George Thuruthel, Egidio Falotico
分类: cs.RO, cs.AI
发布日期: 2024-07-16 (更新: 2024-07-25)
备注: IEEE RAS EMBS 10th International Conference on Biomedical Robotics and Biomechatronics (BioRob 2024)
DOI: 10.1109/BioRob60516.2024.10719859
💡 一句话要点
提出一种可解释的视觉-触觉预测模型,用于软机器人交互
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 软机器人 多模态感知 视觉-触觉融合 生成模型 可解释性 接触交互预测 机器人控制
📋 核心要点
- 软机器人在复杂环境中与物体交互时,由于其结构的柔顺性,预测接触交互变得困难且缺乏可解释性。
- 论文提出一种基于生成模型的多模态感知模型,融合视觉和触觉信息,用于软机器人的接触交互预测和解释。
- 论文提供了一套工具来解释感知模型,揭示了学习后多模态输入融合和预测的过程,并探讨了其对控制的潜在影响。
📝 摘要(中文)
自主系统面临着在不可预测环境中导航和与外部物体交互的复杂挑战。机器人代理成功集成到现实场景中取决于其感知能力,这涉及融合世界模型和预测技能。有效的感知模型建立在融合各种感觉模态以探测周围环境的基础上。深度学习应用于原始感觉模态提供了一种可行的选择。然而,基于学习的感知表示变得难以解释。这种挑战在软机器人中尤为突出,因为结构的柔顺性和材料使得预测更加困难。我们的工作通过利用生成模型构建软机器人的多模态感知模型,并利用本体感觉和视觉信息来预测和解释与外部物体的接触交互,从而解决了这一复杂性。提供了一套解释感知模型的工具,阐明了学习阶段后跨多个感觉输入的融合和预测过程。我们将深入研究感知模型的前景及其对控制目的的影响。
🔬 方法详解
问题定义:论文旨在解决软机器人在与外部物体交互时,由于自身结构的柔顺性,导致难以准确预测和解释接触交互的问题。现有方法,特别是基于深度学习的方法,虽然在感知方面表现良好,但其学习到的表征往往缺乏可解释性,这对于软机器人的控制和调试带来了挑战。
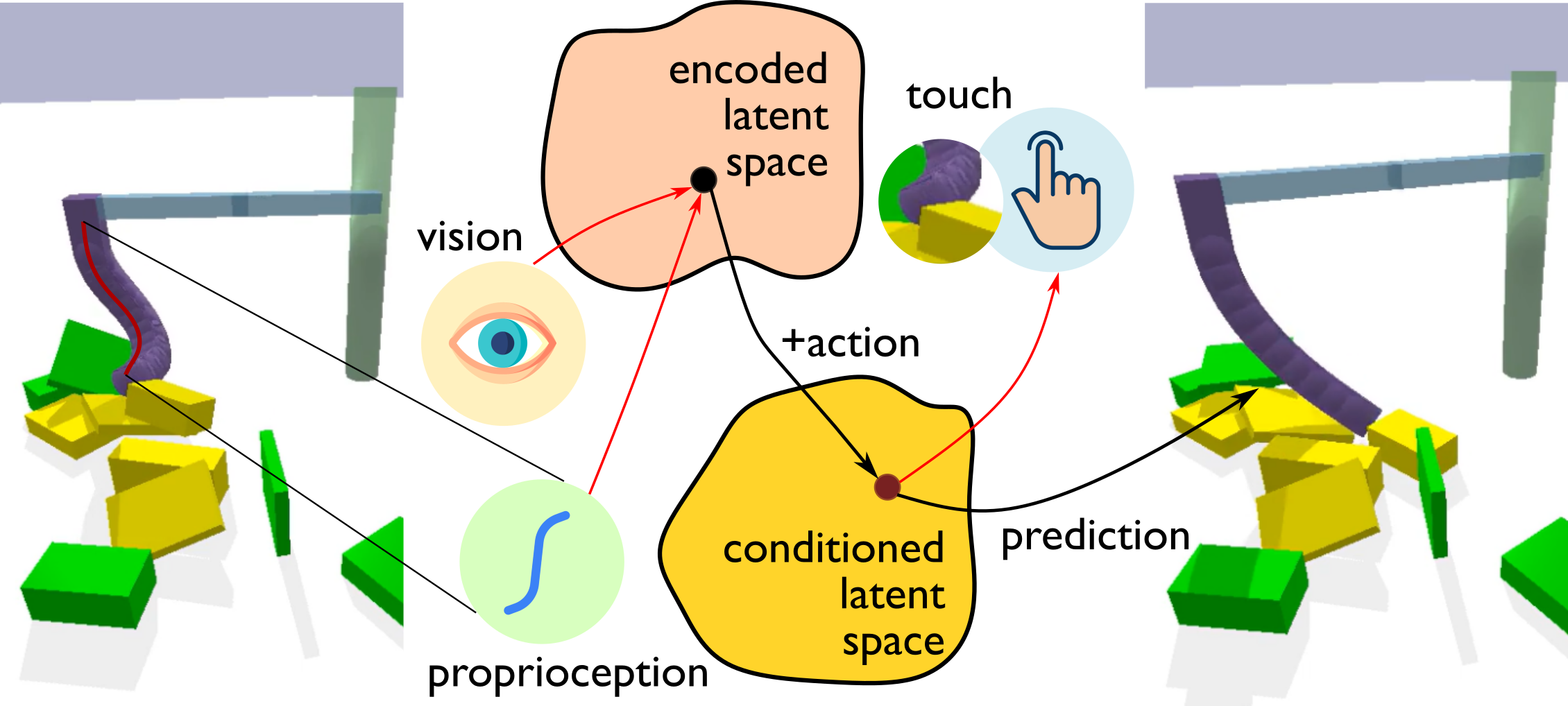
核心思路:论文的核心思路是利用生成模型构建一个多模态感知模型,该模型能够融合视觉和触觉信息,从而预测软机器人与外部物体的接触交互。通过生成模型,可以更好地理解和解释模型内部的表征,从而提高模型的可解释性。
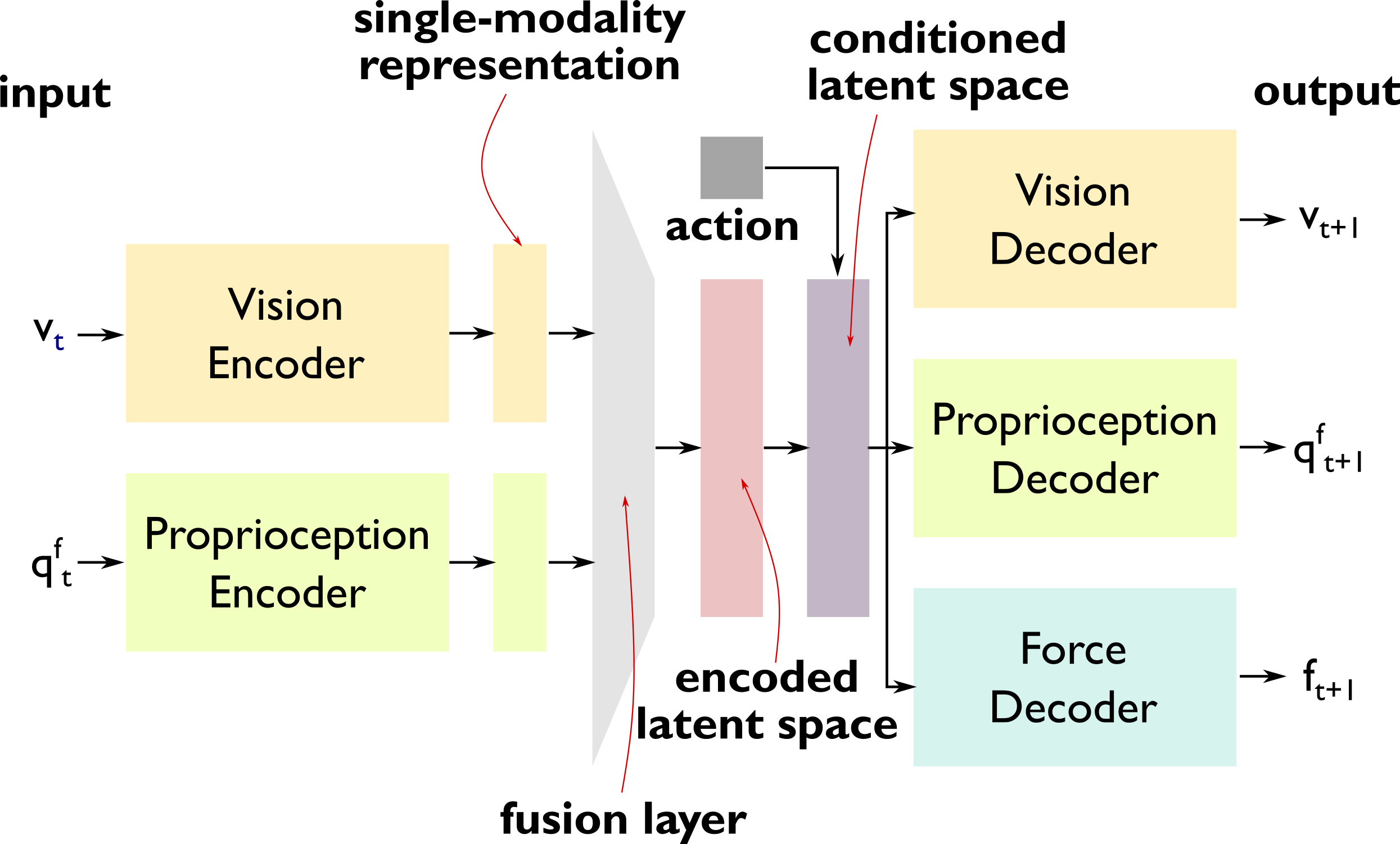
技术框架:整体框架包含以下几个主要模块:1) 视觉信息输入模块,用于获取软机器人的视觉图像;2) 触觉信息输入模块,用于获取软机器人的触觉传感器数据;3) 多模态融合模块,将视觉和触觉信息进行融合,生成统一的表征;4) 生成模型,基于融合后的表征,预测软机器人与外部物体的接触交互;5) 可解释性分析模块,用于分析生成模型的内部表征,从而理解模型的预测过程。
关键创新:论文的关键创新在于将生成模型应用于软机器人的多模态感知,并提供了一套工具来解释模型的内部表征。这使得研究人员能够更好地理解模型是如何进行预测的,从而提高模型的可信度和可靠性。此外,该方法还能够有效地融合视觉和触觉信息,从而提高预测的准确性。
关键设计:论文中生成模型的具体结构未知,但可以推测其可能采用变分自编码器(VAE)或生成对抗网络(GAN)等结构。损失函数的设计可能包括重构损失(用于保证生成模型的生成能力)和预测损失(用于保证模型能够准确预测接触交互)。具体的网络结构和参数设置未知。
🖼️ 关键图片

📊 实验亮点
由于论文未提供具体的实验数据,因此无法总结实验亮点。但根据摘要描述,该研究提供了一套工具来解释感知模型,阐明了学习阶段后跨多个感觉输入的融合和预测过程。这表明该方法在提高软机器人感知模型的可解释性方面具有潜在的优势。
🎯 应用场景
该研究成果可应用于各种软机器人操作任务,例如物体抓取、操作和导航。通过提高软机器人感知的准确性和可解释性,可以显著提升其在复杂环境中的适应性和鲁棒性。此外,该研究还有助于开发更安全、更可靠的软机器人系统,从而促进其在医疗、康复和工业等领域的应用。
📄 摘要(原文)
Autonomous systems face the intricate challenge of navigating unpredictable environments and interacting with external objects. The successful integration of robotic agents into real-world situations hinges on their perception capabilities, which involve amalgamating world models and predictive skills. Effective perception models build upon the fusion of various sensory modalities to probe the surroundings. Deep learning applied to raw sensory modalities offers a viable option. However, learning-based perceptive representations become difficult to interpret. This challenge is particularly pronounced in soft robots, where the compliance of structures and materials makes prediction even harder. Our work addresses this complexity by harnessing a generative model to construct a multi-modal perception model for soft robots and to leverage proprioceptive and visual information to anticipate and interpret contact interactions with external objects. A suite of tools to interpret the perception model is furnished, shedding light on the fusion and prediction processes across multiple sensory inputs after the learning phase. We will delve into the outlooks of the perception model and its implications for control purposes.