Safe Learning of Locomotion Skills from MPC
作者: Xun Pua, Majid Khadiv
分类: cs.RO
发布日期: 2024-07-16
💡 一句话要点
提出基于MPC安全学习的步态控制方法,降低训练失败率并提升鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 步态控制 安全学习 模型预测控制 强化学习 SafeDAGGER
📋 核心要点
- 步态控制系统开环不稳定性导致从零开始学习容易失败,现有方法难以保证训练过程的安全性。
- 借鉴SafeDAGGER框架,利用MPC作为专家指导,迭代优化策略,降低训练过程中的失败次数。
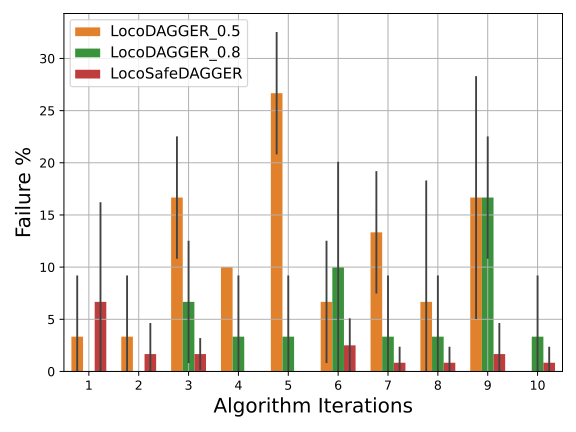
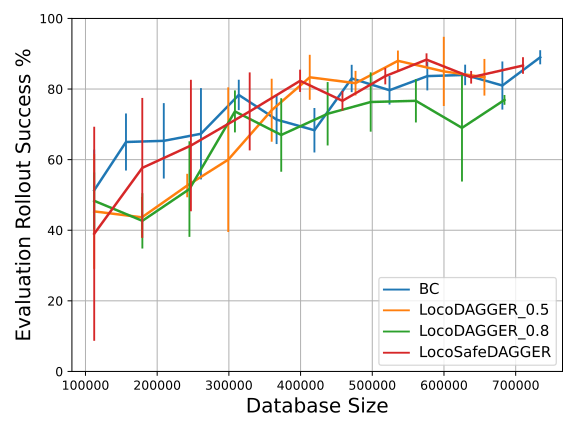
- 实验表明,该方法显著减少了训练失败次数,并提高了策略对外部干扰的鲁棒性,优于行为克隆和 vanilla DAGGER。
📝 摘要(中文)
安全地学习步态控制技能仍然是一个开放性问题。步态系统开环动力学本质上的不稳定性,使得从零开始的朴素学习容易在现实世界中发生灾难性故障。本文研究了使用迭代算法从模型预测控制(MPC)中安全地学习步态控制技能。在我们的框架中,我们使用MPC作为专家,并从安全数据聚合(SafeDAGGER)框架中获得灵感,以最大限度地减少策略训练期间的失败次数。通过与其他标准方法(如行为克隆和 vanilla DAGGER)的比较,我们表明,我们的方法不仅在训练期间的失败次数明显更少,而且生成的策略对外部干扰也更具鲁棒性。
🔬 方法详解
问题定义:论文旨在解决步态控制技能安全学习的问题。现有的从零开始学习方法,由于步态系统固有的不稳定性,容易在训练过程中发生灾难性失败,导致机器人损坏或任务无法完成。因此,如何在训练过程中保证安全性,减少失败次数,是该论文要解决的核心问题。
核心思路:论文的核心思路是利用模型预测控制(MPC)作为专家,指导强化学习策略的训练。MPC能够提供安全的控制策略,避免系统进入危险状态。通过模仿MPC的控制行为,并结合SafeDAGGER框架,可以在训练过程中逐步提升策略的性能,同时保证安全性。
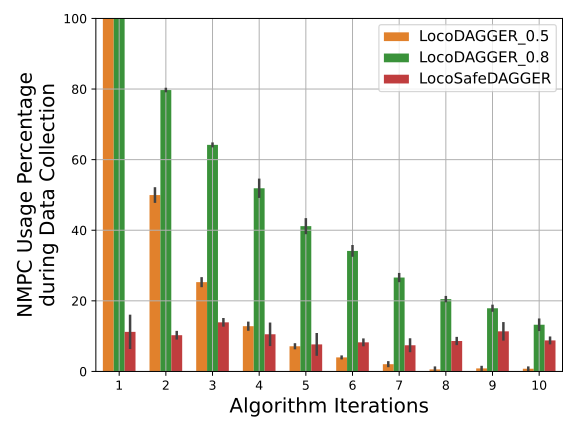
技术框架:整体框架包含以下几个主要模块:1)MPC控制器:作为专家,提供安全的控制策略。2)强化学习策略:学习MPC的控制行为,并逐步提升性能。3)SafeDAGGER框架:用于迭代优化策略,并选择安全的数据进行训练。4)环境交互模块:用于与真实环境或仿真环境进行交互,收集训练数据。
关键创新:该论文的关键创新在于将MPC和SafeDAGGER框架结合起来,用于步态控制技能的安全学习。与传统的行为克隆或 vanilla DAGGER相比,该方法能够显著减少训练过程中的失败次数,并提高策略的鲁棒性。
关键设计:论文的关键设计包括:1)MPC控制器的设计,需要保证其能够提供安全的控制策略。2)强化学习策略的选择,可以选择合适的算法(如TRPO、PPO等)进行训练。3)SafeDAGGER框架的参数设置,需要根据具体问题进行调整,以保证训练的效率和安全性。4)损失函数的设计,需要考虑模仿MPC的控制行为,并加入正则化项,以提高策略的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在训练过程中显著减少了失败次数,优于行为克隆和 vanilla DAGGER。同时,该方法训练得到的策略对外部干扰具有更强的鲁棒性,能够在复杂环境中稳定运行。具体性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种步态控制机器人,如人形机器人、四足机器人等。通过安全地学习步态控制技能,可以提高机器人在复杂环境中的运动能力和适应性,使其能够完成各种任务,如搜救、巡检、物流等。此外,该方法还可以推广到其他控制领域,如自动驾驶、飞行器控制等。
📄 摘要(原文)
Safe learning of locomotion skills is still an open problem. Indeed, the intrinsically unstable nature of the open-loop dynamics of locomotion systems renders naive learning from scratch prone to catastrophic failures in the real world. In this work, we investigate the use of iterative algorithms to safely learn locomotion skills from model predictive control (MPC). In our framework, we use MPC as an expert and take inspiration from the safe data aggregation (SafeDAGGER) framework to minimize the number of failures during training of the policy. Through a comparison with other standard approaches such as behavior cloning and vanilla DAGGER, we show that not only our approach has a substantially fewer number of failures during training, but the resulting policy is also more robust to external disturbances.