APriCoT: Action Primitives based on Contact-state Transition for In-Hand Tool Manipulation
作者: Daichi Saito, Atsushi Kanehira, Kazuhiro Sasabuchi, Naoki Wake, Jun Takamatsu, Hideki Koike, Katsushi Ikeuchi
分类: cs.RO
发布日期: 2024-07-16
💡 一句话要点
提出基于接触状态转移的动作原语APriCoT,用于灵巧手工具操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧手操作 工具操作 强化学习 动作原语 接触状态转移
📋 核心要点
- 灵巧手工具操作需要探索长期接触状态变化,且动作高度依赖接触状态转移,导致奖励稀疏和样本效率低。
- APriCoT将操作分解为基于接触状态转移的短期动作原语,每个原语执行相似动作,降低了探索难度。
- 实验表明,APriCoT成功实现了细长物体的旋转和期望抓取,且对物体形状变化具有鲁棒性。
📝 摘要(中文)
本研究旨在通过深度强化学习实现灵巧手工具操作技能,该操作不仅包括手内操作工具,还包括在操作后实现适合任务的抓取。学习该技能的难点在于:(A)需要探索长期接触状态变化以实现期望的抓取;(B)根据接触状态转移,动作需要高度变化。(A)导致成功抓取的奖励稀疏,(B)要求强化学习智能体在状态-动作空间内广泛探索以学习高度变化的动作,导致样本效率低下。为了解决这些问题,本研究提出了基于接触状态转移的动作原语(APriCoT)。APriCoT通过基于三种动作表示(分离、交叉、连接)将操作描述为接触状态转移,从而将操作分解为短期动作原语。在每个动作原语中,手指需要执行短期且相似的动作。通过训练每个原语的策略,我们可以缓解(A)和(B)中的问题。本研究以一个基本操作为例,即旋转一个用精细抓握方式抓取的细长物体半圈,以实现初始抓握。实验结果表明,与现有研究不同,我们的方法成功地实现了旋转和期望抓取的实现。此外,发现该策略对物体形状的变化具有鲁棒性。
🔬 方法详解
问题定义:现有方法在灵巧手工具操作中,难以有效探索长期接触状态变化以实现期望的抓取,并且由于动作的高度多样性,导致强化学习训练的样本效率低下。具体来说,奖励信号稀疏,智能体难以学习到有效的策略。
核心思路:论文的核心思路是将复杂的灵巧手工具操作分解为一系列基于接触状态转移的短期动作原语。通过学习每个动作原语的策略,降低了动作的复杂度和探索空间,从而提高了样本效率,并更容易获得有效的奖励信号。
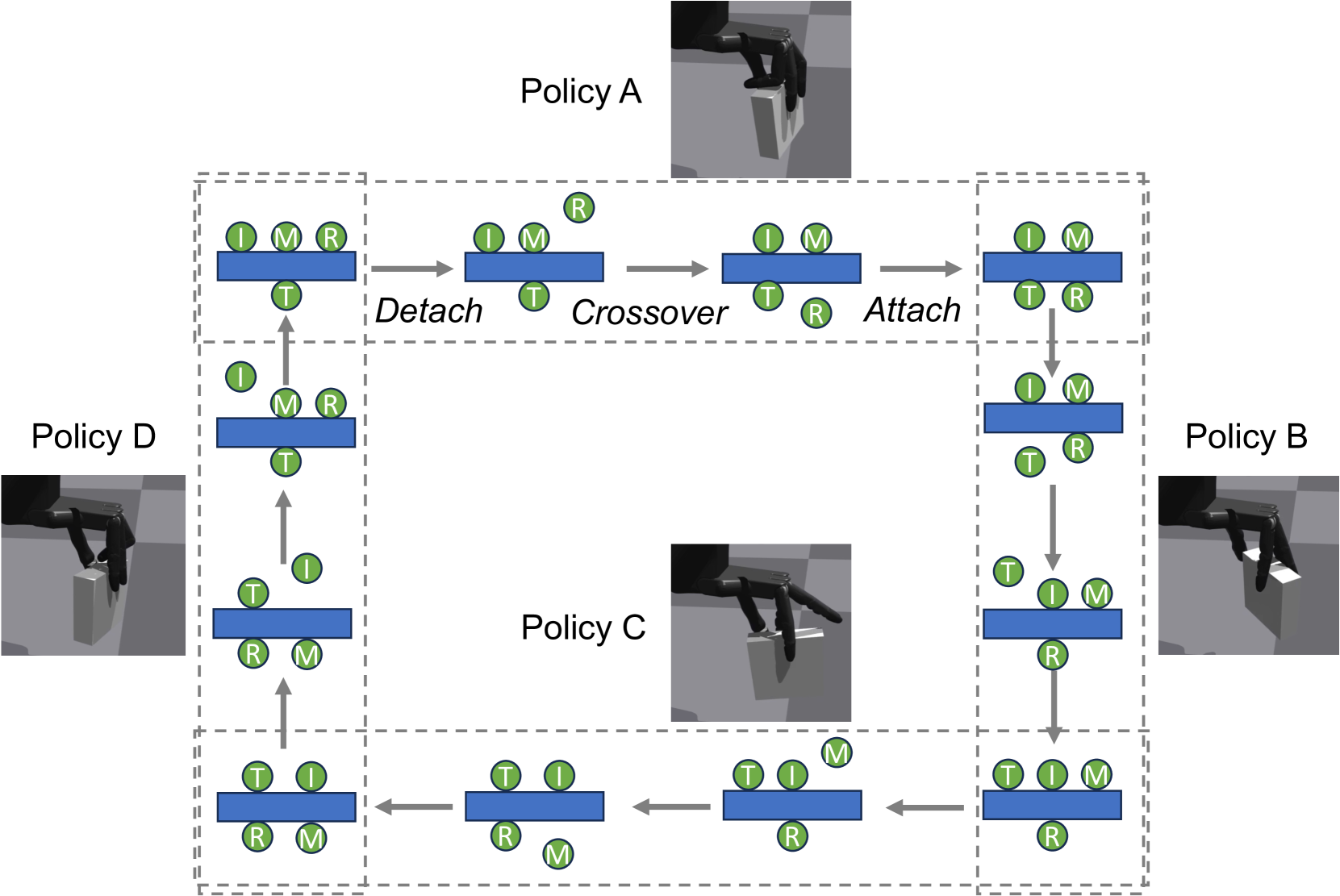
技术框架:APriCoT方法将操作分解为三个动作原语:分离(detach)、交叉(crossover)和连接(attach)。每个动作原语对应一个独立的强化学习策略。整体流程为:首先,根据当前接触状态选择合适的动作原语;然后,执行该动作原语对应的策略;最后,观察新的接触状态,并重复上述过程,直到达到目标抓取状态。
关键创新:APriCoT的关键创新在于将连续的、复杂的灵巧手操作分解为离散的、简单的动作原语。这种分解方式降低了强化学习的难度,使得智能体更容易学习到有效的策略。与直接学习整个操作的策略相比,APriCoT能够更好地处理奖励稀疏和动作多样性的问题。
关键设计:论文中使用了三种动作表示:detach, crossover, attach。具体实现细节未知,但可以推测每个动作原语对应一个独立的神经网络,输入为当前状态(例如,手指关节角度、物体姿态、接触状态),输出为动作(例如,手指关节力矩或角度变化)。损失函数的设计需要考虑奖励的稀疏性,可能使用了奖励塑形或其他技巧来加速学习。
🖼️ 关键图片


📊 实验亮点
实验结果表明,APriCoT方法成功地实现了细长物体的旋转和期望抓取,而现有研究未能实现。此外,该策略对物体形状的变化具有鲁棒性,表明该方法具有一定的泛化能力。具体的性能数据和对比基线未知,但论文强调了APriCoT在实现目标抓取方面的成功。
🎯 应用场景
该研究成果可应用于自动化装配、医疗手术机器人、以及其他需要在狭小空间内进行精细操作的场景。通过学习不同的动作原语,机器人可以灵活地操作各种工具,完成复杂的任务,提高生产效率和操作精度。未来,该技术有望应用于更复杂的工具操作和更广泛的机器人应用领域。
📄 摘要(原文)
In-hand tool manipulation is an operation that not only manipulates a tool within the hand (i.e., in-hand manipulation) but also achieves a grasp suitable for a task after the manipulation. This study aims to achieve an in-hand tool manipulation skill through deep reinforcement learning. The difficulty of learning the skill arises because this manipulation requires (A) exploring long-term contact-state changes to achieve the desired grasp and (B) highly-varied motions depending on the contact-state transition. (A) leads to a sparsity of a reward on a successful grasp, and (B) requires an RL agent to explore widely within the state-action space to learn highly-varied actions, leading to sample inefficiency. To address these issues, this study proposes Action Primitives based on Contact-state Transition (APriCoT). APriCoT decomposes the manipulation into short-term action primitives by describing the operation as a contact-state transition based on three action representations (detach, crossover, attach). In each action primitive, fingers are required to perform short-term and similar actions. By training a policy for each primitive, we can mitigate the issues from (A) and (B). This study focuses on a fundamental operation as an example of in-hand tool manipulation: rotating an elongated object grasped with a precision grasp by half a turn to achieve the initial grasp. Experimental results demonstrated that ours succeeded in both the rotation and the achievement of the desired grasp, unlike existing studies. Additionally, it was found that the policy was robust to changes in object shape.