OVExp: Open Vocabulary Exploration for Object-Oriented Navigation
作者: Meng Wei, Tai Wang, Yilun Chen, Hanqing Wang, Jiangmiao Pang, Xihui Liu
分类: cs.RO
发布日期: 2024-07-12
💡 一句话要点
提出OVExp框架以解决开放词汇目标导航问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇导航 视觉-语言模型 目标导向探索 场景表示 轻量级变换器 零-shot学习 智能导航
📋 核心要点
- 现有物体导航方法在开放词汇目标上泛化能力不足,且需要大量训练数据。
- OVExp框架通过集成视觉-语言模型,构建场景表示并进行目标导向探索,解决了开放词汇导航的挑战。
- 实验结果显示OVExp在多个基准测试中超越了传统零-shot方法,展现出强大的泛化能力。
📝 摘要(中文)
面向物体的具身导航旨在定位特定物体,现有方法在开放词汇目标上常常难以泛化。尽管近期视觉-语言模型(VLMs)的进展为超越预定义类别的物体识别提供了希望,但在开放词汇环境中实现高效的目标导向探索仍然具有挑战性。本文提出OVExp,一个基于学习的框架,集成了VLMs以实现开放词汇探索。OVExp通过使用VLMs对观察进行编码并将其投影到自上而下的地图上来构建场景表示。目标在同一VLM特征空间中编码,轻量级的基于变换器的解码器预测目标位置,同时保持多样的表示能力。实验结果表明,OVExp在多个基准测试中优于以往的零-shot方法,能够泛化到多样的场景,并处理不同的目标模态。
🔬 方法详解
问题定义:本文旨在解决开放词汇目标导航中的泛化问题,现有方法在面对未见过的目标时表现不佳,且通常依赖于大量的训练数据。
核心思路:OVExp框架通过将视觉-语言模型(VLMs)与目标导向探索相结合,构建场景表示并在同一特征空间中编码目标,从而提高了开放词汇环境下的导航能力。
技术框架:OVExp的整体架构包括观察编码、场景表示构建、目标编码和目标位置预测四个主要模块。首先,通过VLMs对观察进行编码,然后将其投影到自上而下的地图上,接着在同一特征空间中编码目标,最后通过轻量级变换器解码器预测目标位置。
关键创新:OVExp的主要创新在于使用低成本的语义类别构建地图,并通过文本编码器将其转换为CLIP的嵌入空间,这一设计显著降低了计算成本,并增强了模型的泛化能力。
关键设计:在设计中,OVExp采用了轻量级的变换器结构作为解码器,优化了参数设置以提高效率,同时使用了特定的损失函数来确保目标位置预测的准确性。整体设计旨在在保持性能的同时,降低计算资源的消耗。
🖼️ 关键图片


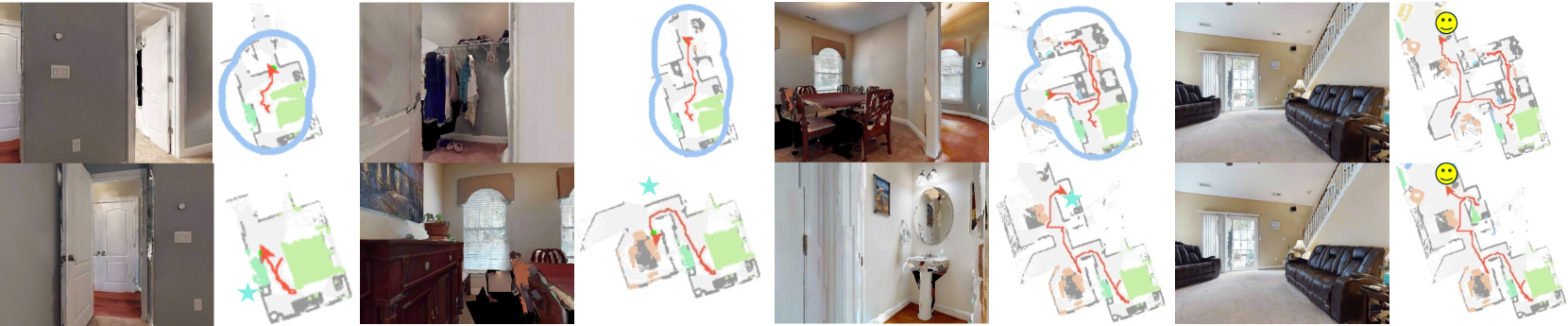
📊 实验亮点
在多个标准基准测试中,OVExp的性能超越了以往的零-shot方法,展现出在不同场景和目标模态下的强泛化能力。具体实验结果表明,OVExp在目标定位准确性和计算效率上均有显著提升,展示了其在开放词汇导航中的有效性。
🎯 应用场景
OVExp框架在机器人导航、智能家居和增强现实等领域具有广泛的应用潜力。通过实现开放词汇目标的高效导航,OVExp能够提升智能系统在复杂环境中的自主决策能力,推动相关技术的实际应用和发展。
📄 摘要(原文)
Object-oriented embodied navigation aims to locate specific objects, defined by category or depicted in images. Existing methods often struggle to generalize to open vocabulary goals without extensive training data. While recent advances in Vision-Language Models (VLMs) offer a promising solution by extending object recognition beyond predefined categories, efficient goal-oriented exploration becomes more challenging in an open vocabulary setting. We introduce OVExp, a learning-based framework that integrates VLMs for Open-Vocabulary Exploration. OVExp constructs scene representations by encoding observations with VLMs and projecting them onto top-down maps for goal-conditioned exploration. Goals are encoded in the same VLM feature space, and a lightweight transformer-based decoder predicts target locations while maintaining versatile representation abilities. To address the impracticality of fusing dense pixel embeddings with full 3D scene reconstruction for training, we propose constructing maps using low-cost semantic categories and transforming them into CLIP's embedding space via the text encoder. The simple but effective design of OVExp significantly reduces computational costs and demonstrates strong generalization abilities to various navigation settings. Experiments on established benchmarks show OVExp outperforms previous zero-shot methods, can generalize to diverse scenes, and handle different goal modalities.