Continuous Control with Coarse-to-fine Reinforcement Learning
作者: Younggyo Seo, Jafar Uruç, Stephen James
分类: cs.RO, cs.AI, cs.CV, cs.LG, eess.SY
发布日期: 2024-07-10
备注: Project webpage: https://younggyo.me/cqn/
💡 一句话要点
提出粗到精强化学习框架,解决连续动作空间中样本效率低的挑战
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 连续控制 粗到精学习 样本效率 机器人操作
📋 核心要点
- 现有强化学习算法在样本效率方面有所提升,但设计能够在真实环境中实际部署的强化学习算法仍然是一个挑战。
- CRL框架的核心思想是以粗到精的方式迭代离散化连续动作空间,并选择具有最高Q值的区间进行下一层离散化,从而实现高效的连续控制。
- 实验结果表明,CQN在稀疏奖励的RLBench操作任务上显著优于基线方法,并且能够在现实世界操作任务中快速学习。
📝 摘要(中文)
本文提出了一种粗到精强化学习(CRL)框架,该框架训练强化学习智能体以粗到精的方式“放大”连续动作空间,从而能够使用稳定、样本高效的基于价值的强化学习算法来处理细粒度的连续控制任务。我们的核心思想是训练智能体,通过迭代以下步骤来输出动作:(i)将连续动作空间离散化为多个区间;(ii)选择具有最高Q值的区间,以便在下一层进一步离散化。然后,我们在CRL框架内引入了一种具体的、基于价值的算法,称为粗到精Q网络(CQN)。我们的实验表明,在少量环境交互和专家演示的情况下,CQN在20个稀疏奖励的RLBench操作任务上显著优于强化学习和行为克隆基线。我们还表明,CQN能够稳健地学习在几分钟的在线训练中解决现实世界的操作任务。
🔬 方法详解
问题定义:论文旨在解决连续动作空间强化学习中样本效率低的问题。传统的强化学习算法在处理连续动作空间时,往往需要大量的样本才能学习到有效的策略,这限制了它们在真实世界机器人控制等任务中的应用。现有的方法,如直接在连续空间中学习策略或使用离散化方法,要么样本效率不高,要么难以处理细粒度的控制任务。
核心思路:论文的核心思路是采用一种粗到精的策略来探索连续动作空间。智能体首先在一个粗略的离散化动作空间中进行探索,然后逐步细化动作空间,聚焦于更有希望的区域。这种方法可以有效地减少搜索空间,提高样本效率,并允许智能体学习到细粒度的控制策略。
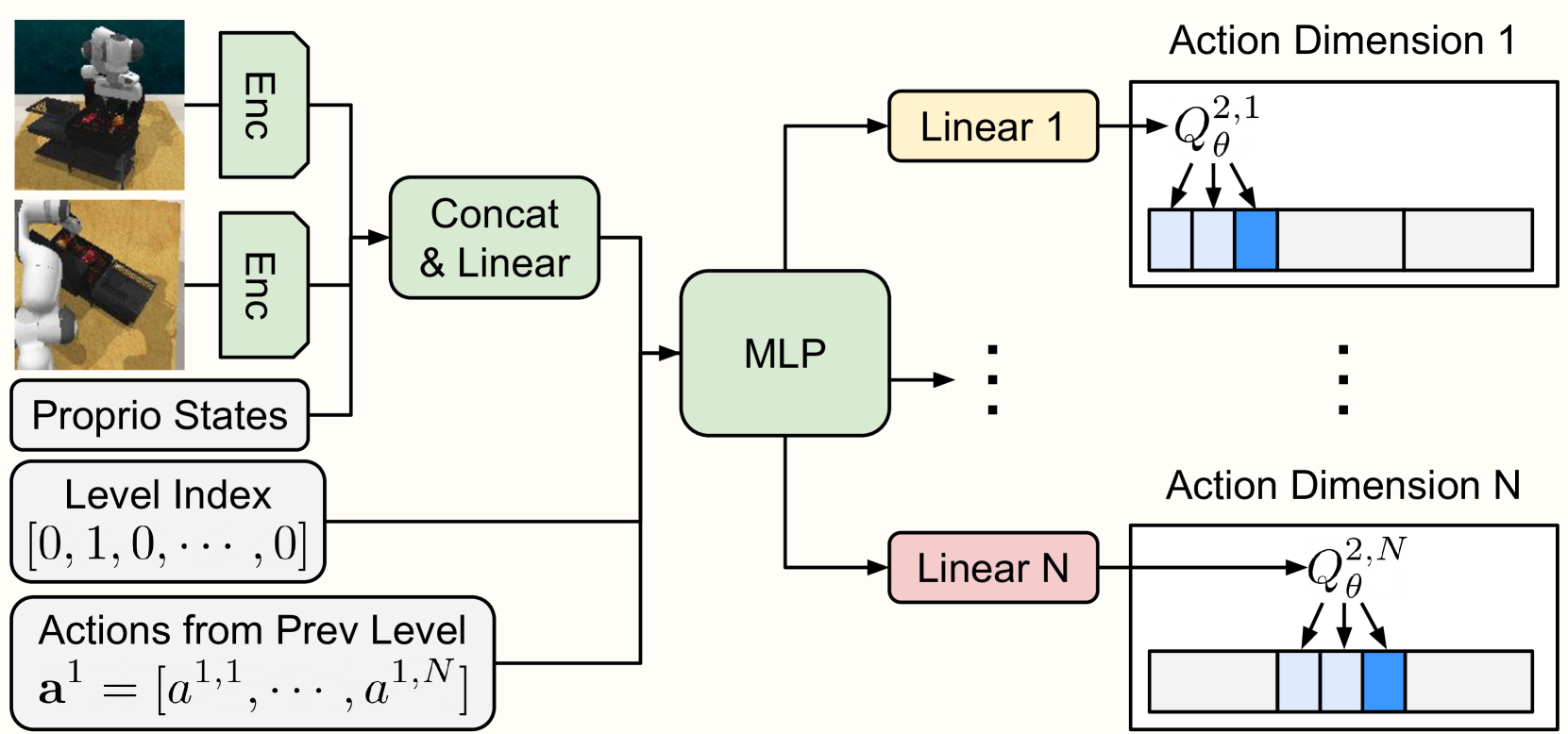
技术框架:CRL框架包含以下主要步骤:1. 初始化:将连续动作空间离散化为若干个粗略的区间。2. Q值估计:使用Q网络估计每个区间的Q值。3. 区间选择:选择具有最高Q值的区间。4. 细化:将选定的区间进一步离散化为更小的区间。5. 迭代:重复步骤2-4,直到达到所需的动作精度。最终选择的最小区间的中心点作为输出动作。
关键创新:该方法最重要的创新点在于其粗到精的动作空间探索策略。与传统的直接在连续空间中学习或一次性离散化动作空间的方法不同,CRL通过迭代地细化动作空间,实现了样本效率和控制精度的平衡。这种方法能够有效地利用价值函数的信息来指导动作空间的探索,从而加速学习过程。
关键设计:CQN算法是CRL框架下的一个具体实现,它使用Q网络来估计每个区间的Q值。关键设计包括:1. Q网络结构:可以使用任何标准的Q网络结构,如DQN或Double DQN。2. 离散化方法:可以使用均匀离散化或基于Q值的自适应离散化方法。3. 奖励函数:可以使用稀疏奖励或密集奖励。4. 训练过程:可以使用标准的强化学习训练方法,如经验回放和目标网络。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CQN在20个稀疏奖励的RLBench操作任务上显著优于强化学习和行为克隆基线。具体来说,CQN在样本效率方面取得了显著提升,能够在少量环境交互和专家演示的情况下学习到有效的策略。此外,CQN还能够在几分钟的在线训练中解决现实世界的操作任务,展示了其在实际应用中的潜力。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、游戏AI等领域。特别是在需要精确控制但样本获取成本较高的场景下,例如复杂环境下的机器人装配、高精度医疗手术等,CRL框架能够显著提升学习效率,降低训练成本,加速智能体的部署。
📄 摘要(原文)
Despite recent advances in improving the sample-efficiency of reinforcement learning (RL) algorithms, designing an RL algorithm that can be practically deployed in real-world environments remains a challenge. In this paper, we present Coarse-to-fine Reinforcement Learning (CRL), a framework that trains RL agents to zoom-into a continuous action space in a coarse-to-fine manner, enabling the use of stable, sample-efficient value-based RL algorithms for fine-grained continuous control tasks. Our key idea is to train agents that output actions by iterating the procedure of (i) discretizing the continuous action space into multiple intervals and (ii) selecting the interval with the highest Q-value to further discretize at the next level. We then introduce a concrete, value-based algorithm within the CRL framework called Coarse-to-fine Q-Network (CQN). Our experiments demonstrate that CQN significantly outperforms RL and behavior cloning baselines on 20 sparsely-rewarded RLBench manipulation tasks with a modest number of environment interactions and expert demonstrations. We also show that CQN robustly learns to solve real-world manipulation tasks within a few minutes of online training.