Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
作者: Jiaqi Chen, Bingqian Lin, Xinmin Liu, Lin Ma, Xiaodan Liang, Kwan-Yee K. Wong
分类: cs.RO, cs.CL
发布日期: 2024-07-08 (更新: 2024-08-20)
💡 一句话要点
提出AO-Planner,利用基础模型进行面向可供性的连续视觉-语言导航
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言导航 基础模型 可供性 零样本学习 运动规划 机器人导航
📋 核心要点
- 现有基于LLM的VLN方法侧重于高级任务规划,忽略了导航场景中的低级控制。
- AO-Planner利用视觉可供性提示(VAP)和PathAgent,结合基础模型实现零样本低级运动规划和高级决策。
- 在R2R-CE和RxR-CE数据集上,AO-Planner取得了SOTA零样本性能,SPL提升8.8%,并可用于生成伪标签。
📝 摘要(中文)
本文提出了一种新颖的面向可供性的规划器AO-Planner,用于连续视觉-语言导航(VLN)任务。AO-Planner集成了多种基础模型,以实现面向可供性的低级运动规划和高级决策,均在零样本设置下进行。具体来说,我们采用了一种视觉可供性提示(VAP)方法,其中使用SAM分割可见地面以提供导航可供性,LLM基于此选择潜在的候选航路点并规划通往所选航路点的低级路径。我们进一步提出了一个高级PathAgent,它将规划的路径标记到图像输入中,并通过理解所有环境信息来推断最可能的路径。最后,我们使用相机内部参数和深度信息将所选路径转换为3D坐标,避免了LLM具有挑战性的3D预测。在具有挑战性的R2R-CE和RxR-CE数据集上的实验表明,AO-Planner实现了最先进的零样本性能(SPL提高了8.8%)。我们的方法还可以作为数据标注器来获得伪标签,将其航路点预测能力提炼到基于学习的预测器中。这种新的预测器不需要来自模拟器的任何航路点数据,并且实现了与监督方法竞争的47%的SR。我们建立了LLM和3D世界之间的有效连接,为在低级运动控制中采用基础模型提供了新的前景。
🔬 方法详解
问题定义:现有基于LLM的视觉-语言导航方法主要关注于利用LLM进行高级的任务规划,例如在预定义的导航图中选择节点进行移动。然而,这些方法忽略了导航场景中至关重要的低级运动控制,导致导航过程不够精细和灵活。因此,需要一种能够将LLM的高级规划能力与低级运动控制相结合的方法,以实现更高效和精确的导航。
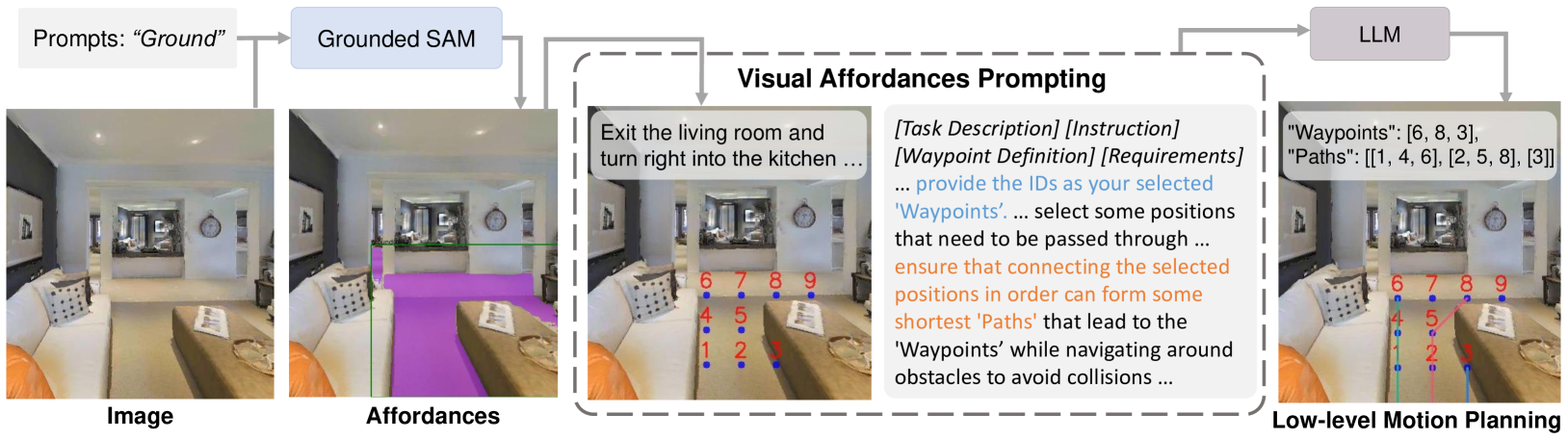
核心思路:本文的核心思路是利用基础模型(如SAM和LLM)的强大能力,构建一个面向可供性的规划器(AO-Planner)。通过视觉可供性提示(VAP),将环境信息转化为LLM可以理解和利用的可供性表示,从而指导LLM进行低级路径规划。同时,利用PathAgent进行高级路径选择,最终将选定的路径转化为3D坐标,实现精确的导航控制。这种设计避免了LLM直接进行复杂的3D预测,降低了任务难度。
技术框架:AO-Planner的整体框架包括以下几个主要模块:1) 视觉可供性提示(VAP):使用SAM分割可见地面,提取导航可供性信息。2) LLM路径规划:基于VAP提供的可供性信息,LLM选择潜在的候选航路点,并规划通往这些航路点的低级路径。3) PathAgent:将规划的路径标记到图像输入中,利用LLM理解环境信息,选择最优路径。4) 3D坐标转换:使用相机内部参数和深度信息将选定的2D路径转换为3D坐标,用于实际的导航控制。
关键创新:本文最重要的技术创新在于将基础模型(SAM和LLM)有效地结合起来,用于解决连续视觉-语言导航中的低级运动控制问题。通过视觉可供性提示,将环境信息转化为LLM可以理解和利用的可供性表示,从而指导LLM进行路径规划。此外,PathAgent的设计使得LLM能够更好地理解环境信息,选择最优路径。这种方法避免了LLM直接进行复杂的3D预测,降低了任务难度,提高了导航性能。
关键设计:VAP模块使用SAM进行地面分割,为LLM提供可供性信息。LLM使用提示工程选择候选航路点并规划路径。PathAgent通过将规划路径标记到图像中,并结合环境信息,利用LLM进行路径选择。3D坐标转换模块使用相机内参和深度信息,将2D路径转换为3D坐标。没有提及具体的损失函数和网络结构等细节,可能使用了标准的基础模型和现有的技术。
🖼️ 关键图片


📊 实验亮点
AO-Planner在R2R-CE和RxR-CE数据集上取得了显著的零样本性能提升,SPL指标提高了8.8%,达到了SOTA水平。此外,该方法还可以作为数据标注器,生成高质量的伪标签,用于训练基于学习的导航预测器,该预测器在不使用任何模拟器航路点数据的情况下,实现了与监督方法竞争的47%的SR。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过结合视觉信息和语言指令,机器人可以在复杂环境中自主规划路径并完成任务。该方法还可以用于生成训练数据,提升学习型导航算法的性能。未来,该研究有望推动基础模型在机器人控制领域的应用,实现更智能、更自主的机器人系统。
📄 摘要(原文)
LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) task. However, existing LLM-based methods often focus only on solving high-level task planning by selecting nodes in predefined navigation graphs for movements, overlooking low-level control in navigation scenarios. To bridge this gap, we propose AO-Planner, a novel Affordances-Oriented Planner for continuous VLN task. Our AO-Planner integrates various foundation models to achieve affordances-oriented low-level motion planning and high-level decision-making, both performed in a zero-shot setting. Specifically, we employ a Visual Affordances Prompting (VAP) approach, where the visible ground is segmented by SAM to provide navigational affordances, based on which the LLM selects potential candidate waypoints and plans low-level paths towards selected waypoints. We further propose a high-level PathAgent which marks planned paths into the image input and reasons the most probable path by comprehending all environmental information. Finally, we convert the selected path into 3D coordinates using camera intrinsic parameters and depth information, avoiding challenging 3D predictions for LLMs. Experiments on the challenging R2R-CE and RxR-CE datasets show that AO-Planner achieves state-of-the-art zero-shot performance (8.8% improvement on SPL). Our method can also serve as a data annotator to obtain pseudo-labels, distilling its waypoint prediction ability into a learning-based predictor. This new predictor does not require any waypoint data from the simulator and achieves 47% SR competing with supervised methods. We establish an effective connection between LLM and 3D world, presenting novel prospects for employing foundation models in low-level motion control.