MetaLoco: Universal Quadrupedal Locomotion with Meta-Reinforcement Learning and Motion Imitation
作者: Fatemeh Zargarbashi, Fabrizio Di Giuro, Jin Cheng, Dongho Kang, Bhavya Sukhija, Stelian Coros
分类: cs.RO
发布日期: 2024-07-05 (更新: 2024-11-04)
备注: The supplementary video is available at https://youtu.be/PaFRUDOrh_U?si=hfdbng3Wxo_GnxIA
💡 一句话要点
MetaLoco:基于元强化学习和运动模仿的通用四足机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元强化学习 运动模仿 四足机器人 通用运动控制 零样本泛化
📋 核心要点
- 现有四足机器人运动控制方法难以泛化到不同结构和参数的机器人,需要大量特定机器人的训练数据。
- MetaLoco利用元强化学习,训练一个具备记忆单元的智能体,通过模仿少量机器人的运动,学习通用的运动控制策略。
- 实验表明,MetaLoco无需针对特定机器人进行微调,即可在多种四足机器人上实现有效的运动控制,并具有良好的泛化能力。
📝 摘要(中文)
本文提出了一种元强化学习方法,用于开发一种通用的运动控制策略,该策略能够对各种四足机器人平台进行零样本泛化。该方法训练一个配备记忆单元的强化学习智能体,通过模仿一小组程序生成的四足机器人的参考运动来实现。通过全面的仿真和真实硬件实验,我们证明了该方法在各种机器人上实现运动的有效性,而无需针对特定机器人进行微调。此外,我们强调了记忆单元在实现泛化、促进对机器人属性变化的快速适应以及提高样本效率方面的关键作用。
🔬 方法详解
问题定义:现有四足机器人运动控制方法通常需要针对特定机器人进行训练,难以泛化到具有不同结构和参数的机器人上。这导致了开发和部署成本的增加,并且限制了机器人在各种环境中的应用。现有的方法通常需要大量的机器人特定数据,并且难以适应机器人属性的变化。
核心思路:MetaLoco的核心思路是利用元强化学习,训练一个能够快速适应新机器人的通用运动控制策略。通过模仿少量不同机器人的运动,智能体学习到一种通用的运动模式,并利用记忆单元来存储和利用机器人特定的信息,从而实现零样本泛化。这种方法避免了针对每个机器人进行单独训练的需求,提高了样本效率和泛化能力。
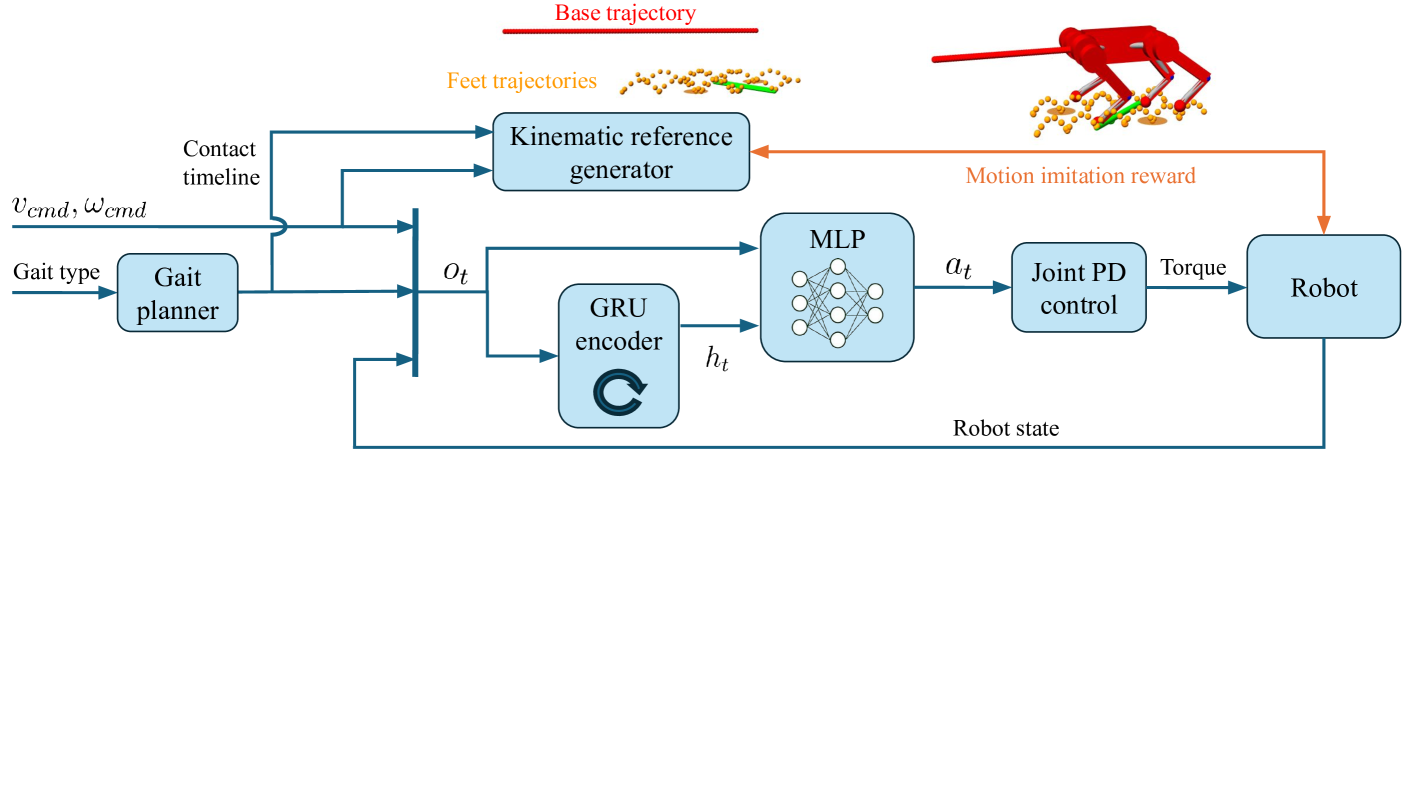
技术框架:MetaLoco的整体框架包括以下几个主要模块:1) 环境生成器:程序化生成具有不同属性的四足机器人,用于训练智能体。2) 运动模仿器:利用参考运动数据,训练智能体模仿各种运动模式。3) 元强化学习智能体:配备记忆单元,学习通用的运动控制策略,并能够快速适应新机器人。4) 奖励函数:设计奖励函数,鼓励智能体模仿参考运动,并保持平衡和稳定。训练过程分为元训练和元测试两个阶段。在元训练阶段,智能体在多个程序生成的机器人上进行训练,学习通用的运动控制策略。在元测试阶段,智能体在未见过的机器人上进行测试,评估其泛化能力。
关键创新:MetaLoco最重要的技术创新点在于利用元强化学习和记忆单元来实现零样本泛化。与传统的强化学习方法相比,MetaLoco不需要针对每个机器人进行单独训练,而是通过模仿少量机器人的运动,学习到一种通用的运动模式,并利用记忆单元来存储和利用机器人特定的信息。这使得MetaLoco能够快速适应新机器人,并具有良好的泛化能力。
关键设计:MetaLoco的关键设计包括:1) 记忆单元:用于存储和利用机器人特定的信息,例如质量、尺寸和关节限制。记忆单元的设计允许智能体快速适应新机器人,并提高样本效率。2) 奖励函数:设计奖励函数,鼓励智能体模仿参考运动,并保持平衡和稳定。奖励函数包括运动模仿奖励、平衡奖励和能量消耗惩罚。3) 网络结构:采用Actor-Critic网络结构,其中Actor网络用于生成动作,Critic网络用于评估状态价值。网络结构的设计考虑了运动控制的特点,并能够有效地学习通用的运动控制策略。
🖼️ 关键图片

📊 实验亮点
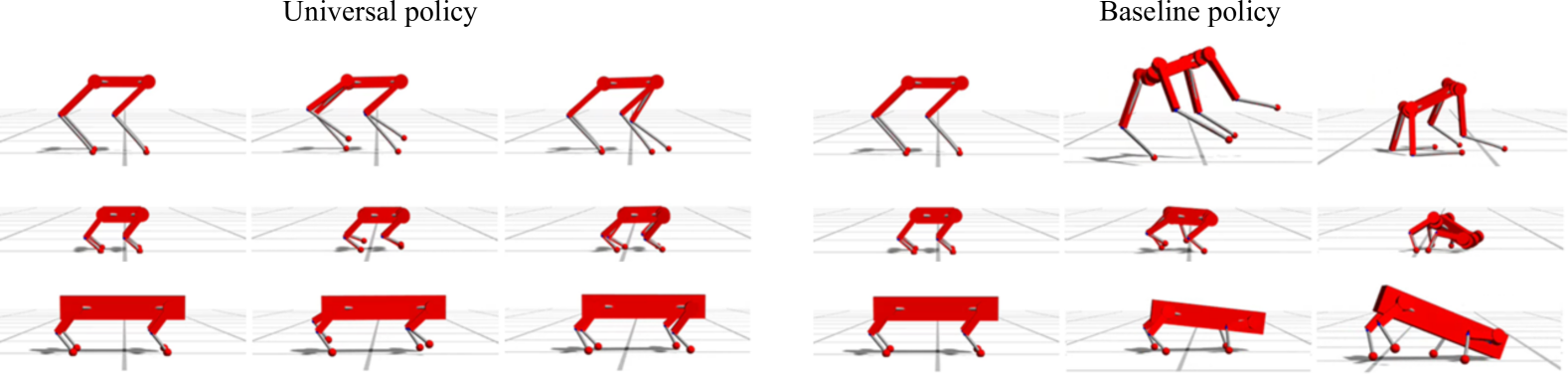
MetaLoco在仿真和真实硬件实验中都取得了显著的成果。在仿真实验中,MetaLoco能够在多种程序生成的四足机器人上实现有效的运动控制,而无需针对特定机器人进行微调。在真实硬件实验中,MetaLoco成功地控制了ANYmal和Aliengo两款不同的四足机器人,并实现了零样本泛化。实验结果表明,MetaLoco能够显著提高四足机器人的运动控制性能和泛化能力。
🎯 应用场景
MetaLoco具有广泛的应用前景,可用于各种四足机器人的运动控制,例如搜救机器人、物流机器人和家庭服务机器人。该方法可以降低开发和部署成本,并提高机器人在各种环境中的适应性。未来,MetaLoco可以扩展到其他类型的机器人,例如双足机器人和多足机器人,并应用于更复杂的任务,例如导航和操作。
📄 摘要(原文)
This work presents a meta-reinforcement learning approach to develop a universal locomotion control policy capable of zero-shot generalization across diverse quadrupedal platforms. The proposed method trains an RL agent equipped with a memory unit to imitate reference motions using a small set of procedurally generated quadruped robots. Through comprehensive simulation and real-world hardware experiments, we demonstrate the efficacy of our approach in achieving locomotion across various robots without requiring robot-specific fine-tuning. Furthermore, we highlight the critical role of the memory unit in enabling generalization, facilitating rapid adaptation to changes in the robot properties, and improving sample efficiency.