VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation
作者: I-Chun Arthur Liu, Sicheng He, Daniel Seita, Gaurav Sukhatme
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2024-07-04 (更新: 2024-10-06)
备注: Accepted to the Conference on Robot Learning (CoRL) 2024
💡 一句话要点
提出VoxAct-B,利用体素化和视觉语言模型解决双臂操作中的动作规划与稳定问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双臂操作 机器人操作 视觉语言模型 体素表示 强化学习
📋 核心要点
- 双臂操作因其高维动作空间而极具挑战,现有方法依赖大量数据和原始动作,导致样本效率低且泛化能力受限。
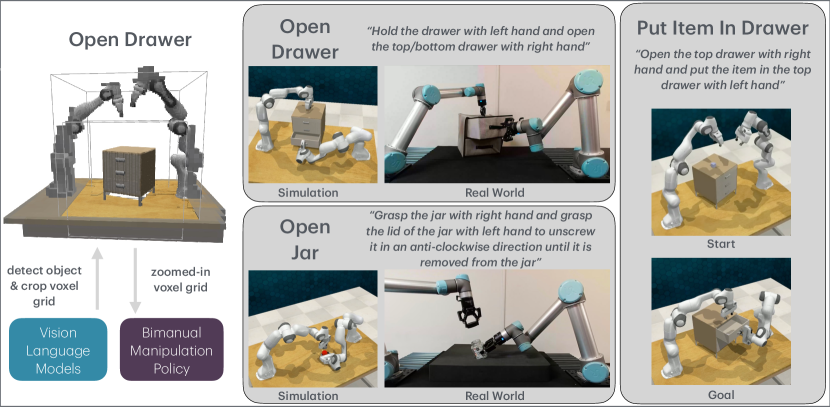
- VoxAct-B利用视觉语言模型优先处理场景关键区域,并重建体素网格,从而指导双臂操作策略学习动作和稳定动作。
- 实验表明,VoxAct-B在模拟环境中优于现有基线,并在真实世界的开抽屉和开罐子任务中成功应用。
📝 摘要(中文)
双臂操作在许多机器人应用中至关重要。与单臂操作相比,双臂操作任务由于更高维度的动作空间而更具挑战性。先前的工作利用大量数据和原始动作来解决这个问题,但可能存在样本效率低和跨各种任务泛化能力有限的问题。为此,我们提出了VoxAct-B,一种基于语言条件、基于体素的方法,它利用视觉语言模型(VLMs)来优先考虑场景中的关键区域并重建体素网格。我们为双臂操作策略提供此体素网格,以学习动作和稳定动作。这种方法能够从体素中更有效地学习策略,并且可以推广到不同的任务。在模拟中,我们表明VoxAct-B在精细的双臂操作任务上优于强大的基线。此外,我们使用两个UR5在真实世界的$ exttt{Open Drawer}$和$ exttt{Open Jar}$任务上演示了VoxAct-B。代码、数据和视频可在https://voxact-b.github.io获得。
🔬 方法详解
问题定义:论文旨在解决双臂操作任务中动作空间维度高、样本效率低以及泛化能力差的问题。现有方法通常依赖大量数据和预定义的原始动作,这限制了它们在复杂和多样化任务中的应用。这些方法难以有效地探索高维动作空间,并且难以适应新的环境和任务。
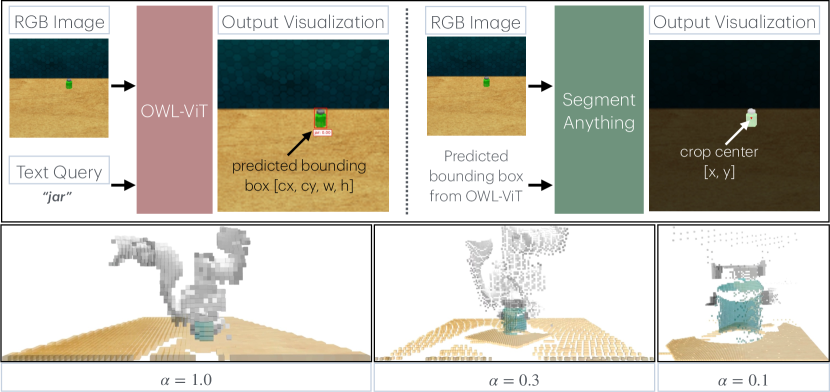
核心思路:论文的核心思路是利用视觉语言模型(VLM)来理解场景,并提取关键信息,然后将这些信息编码成体素网格。这个体素网格作为双臂操作策略的输入,指导策略学习动作和稳定动作。通过这种方式,策略可以专注于场景中的重要区域,从而提高样本效率和泛化能力。
技术框架:VoxAct-B的技术框架主要包括三个阶段:1)视觉语言理解阶段:利用VLM处理场景图像和语言指令,提取关键区域信息。2)体素重建阶段:根据VLM提取的信息,重建场景的体素网格,表示场景的几何结构和语义信息。3)双臂操作策略学习阶段:将体素网格作为输入,训练一个双臂操作策略,学习执行动作和稳定操作。
关键创新:该方法最重要的创新在于将视觉语言模型与体素表示相结合,用于指导双臂操作策略的学习。这种方法能够有效地利用视觉和语言信息,减少动作空间的搜索范围,提高样本效率和泛化能力。与现有方法相比,VoxAct-B不需要预定义的原始动作,可以直接从原始图像和语言指令中学习策略。
关键设计:VLM采用预训练的CLIP模型,用于提取图像和文本特征。体素网格的分辨率为32x32x32。双臂操作策略采用Actor-Critic架构,Actor网络输出动作,Critic网络评估动作的价值。损失函数包括动作损失、稳定损失和语言对齐损失。动作损失鼓励策略执行正确的动作,稳定损失鼓励策略保持操作的稳定性,语言对齐损失鼓励策略与语言指令保持一致。
🖼️ 关键图片

📊 实验亮点
VoxAct-B在模拟环境中,在多个双臂操作任务上超越了现有基线方法。在真实世界的开抽屉和开罐子任务中,VoxAct-B也取得了成功,验证了该方法在实际应用中的可行性。具体性能数据和提升幅度在论文中有详细展示,表明VoxAct-B在样本效率和泛化能力方面具有显著优势。
🎯 应用场景
VoxAct-B具有广泛的应用前景,例如在智能家居中,机器人可以利用该方法完成开抽屉、开罐子等日常任务。在工业自动化领域,机器人可以利用该方法进行装配、搬运等复杂操作。此外,该方法还可以应用于医疗机器人、救援机器人等领域,帮助机器人完成更加精细和复杂的任务。
📄 摘要(原文)
Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world $\texttt{Open Drawer}$ and $\texttt{Open Jar}$ tasks using two UR5s. Code, data, and videos are available at https://voxact-b.github.io.