Commonsense Reasoning for Legged Robot Adaptation with Vision-Language Models
作者: Annie S. Chen, Alec M. Lessing, Andy Tang, Govind Chada, Laura Smith, Sergey Levine, Chelsea Finn
分类: cs.RO, cs.AI
发布日期: 2024-07-02
备注: 27 pages
💡 一句话要点
提出VLM-PC,利用视觉-语言模型常识推理提升腿足机器人复杂环境适应性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 腿足机器人 视觉-语言模型 常识推理 环境适应性 预测控制
📋 核心要点
- 现有腿足机器人学习方法难以泛化到长尾分布的复杂、未预见环境,需要大量人工干预。
- 提出VLM-PC,利用视觉-语言模型的常识推理能力,结合上下文学习和多技能规划,提升机器人适应性。
- 在真实世界障碍赛道上,VLM-PC使Go1四足机器人能够自主应对死胡同、攀爬等复杂场景。
📝 摘要(中文)
腿足机器人有能力在各种环境中导航并克服各种障碍。例如,在搜救任务中,腿足机器人可以爬过碎片、爬过缝隙并走出死胡同。然而,机器人的控制器需要智能地响应这些不同的障碍,这就需要成功处理意外和不寻常的情况。这对当前的学习方法提出了一个公开的挑战,这些方法通常难以推广到没有大量人工监督的意外情况的长尾。为了解决这个问题,我们研究了如何利用视觉-语言模型(VLM)关于世界结构的广泛知识和常识推理能力来帮助腿足机器人在困难、模糊的情况下。我们提出了一个系统,VLM-Predictive Control (VLM-PC),它结合了两个关键组件,我们发现这两个组件对于利用VLM引发即时、自适应的行为选择至关重要:(1)基于先前机器人交互的上下文适应,以及(2)将多个技能规划到未来并重新规划。我们在Go1四足机器人的几个具有挑战性的真实世界障碍赛道上评估了VLM-PC,包括死胡同、攀爬和爬行。我们的实验表明,通过推理交互历史和未来计划,VLM使机器人能够在各种复杂的场景中自主感知、导航和行动,否则这些场景需要特定于环境的工程或人工指导。
🔬 方法详解
问题定义:论文旨在解决腿足机器人在复杂、未知的真实环境中导航和适应的问题。现有方法,尤其是基于学习的方法,通常需要大量特定环境的训练数据或人工指导,难以泛化到新的、未曾见过的场景。这些方法在处理诸如死胡同、需要攀爬或爬行的环境时表现不佳,因为这些情况属于长尾分布,难以通过传统监督学习覆盖。
核心思路:论文的核心思路是利用视觉-语言模型(VLM)所蕴含的关于世界的常识知识和推理能力,来指导腿足机器人的行为选择。VLM能够理解视觉输入和语言描述之间的关系,从而帮助机器人理解环境的语义信息,并根据常识做出合理的决策。通过结合VLM的推理能力和机器人的运动控制,可以实现更强的环境适应性。
技术框架:VLM-PC系统包含两个关键组件:(1) 上下文适应模块,该模块利用机器人与环境的交互历史,通过in-context learning的方式,让VLM更好地理解当前环境的特点;(2) 多技能预测控制模块,该模块将多个技能规划到未来,并根据VLM的推理结果进行重新规划,从而实现更长远的规划和更灵活的适应性。整体流程是:机器人首先通过视觉传感器获取环境信息,然后将视觉信息输入到VLM中,VLM根据上下文信息和未来规划,输出对环境的理解和对机器人行为的建议,最后机器人根据VLM的建议执行相应的动作。
关键创新:最重要的技术创新点在于将视觉-语言模型的常识推理能力与腿足机器人的运动控制相结合。与传统的基于学习的方法不同,VLM-PC不需要大量特定环境的训练数据,而是通过利用VLM的通用知识来实现环境适应性。此外,上下文适应和多技能预测控制模块的设计,使得VLM-PC能够更好地理解环境的语义信息,并做出更合理的决策。
关键设计:论文中没有明确给出关键参数设置、损失函数或网络结构的具体细节。VLM的选择和prompt的设计是关键,需要根据具体的任务和环境进行调整。上下文适应模块需要维护一个交互历史的缓冲区,并选择合适的历史交互样本来构建prompt。多技能预测控制模块需要定义一组可供选择的技能,并设计一个合适的规划算法来选择最佳的技能序列。
🖼️ 关键图片

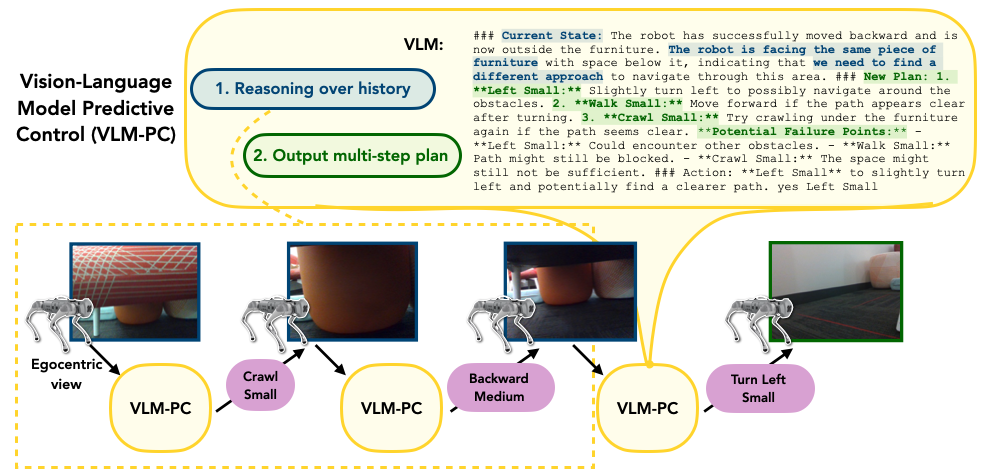

📊 实验亮点
实验结果表明,VLM-PC能够使Go1四足机器人在包含死胡同、攀爬和爬行等复杂障碍的真实环境中自主导航。通过推理交互历史和未来计划,VLM-PC能够使机器人在各种复杂的场景中自主感知、导航和行动,而无需特定于环境的工程或人工指导。具体性能数据和对比基线未在摘要中明确给出,但强调了VLM-PC在复杂环境适应性方面的显著提升。
🎯 应用场景
该研究成果可应用于搜救、勘探、巡检等复杂环境下的机器人自主导航任务。例如,在灾后搜救中,机器人可以利用VLM-PC自主识别瓦砾堆、狭窄通道等障碍,并选择合适的行动策略进行导航。该技术还可以应用于工业巡检,使机器人能够自主识别异常情况并采取相应措施。未来,该技术有望进一步提升机器人在未知环境下的自主性和适应性。
📄 摘要(原文)
Legged robots are physically capable of navigating a diverse variety of environments and overcoming a wide range of obstructions. For example, in a search and rescue mission, a legged robot could climb over debris, crawl through gaps, and navigate out of dead ends. However, the robot's controller needs to respond intelligently to such varied obstacles, and this requires handling unexpected and unusual scenarios successfully. This presents an open challenge to current learning methods, which often struggle with generalization to the long tail of unexpected situations without heavy human supervision. To address this issue, we investigate how to leverage the broad knowledge about the structure of the world and commonsense reasoning capabilities of vision-language models (VLMs) to aid legged robots in handling difficult, ambiguous situations. We propose a system, VLM-Predictive Control (VLM-PC), combining two key components that we find to be crucial for eliciting on-the-fly, adaptive behavior selection with VLMs: (1) in-context adaptation over previous robot interactions and (2) planning multiple skills into the future and replanning. We evaluate VLM-PC on several challenging real-world obstacle courses, involving dead ends and climbing and crawling, on a Go1 quadruped robot. Our experiments show that by reasoning over the history of interactions and future plans, VLMs enable the robot to autonomously perceive, navigate, and act in a wide range of complex scenarios that would otherwise require environment-specific engineering or human guidance.