Language-Guided Object-Centric Diffusion Policy for Generalizable and Collision-Aware Robotic Manipulation
作者: Hang Li, Qian Feng, Zhi Zheng, Jianxiang Feng, Zhaopeng Chen, Alois Knoll
分类: cs.RO
发布日期: 2024-06-29 (更新: 2025-03-16)
备注: ICRA 2025
💡 一句话要点
提出Lan-o3dp:一种语言引导的、面向对象的扩散策略,用于可泛化和防碰撞的机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 扩散模型 语言引导 碰撞避免 泛化学习
📋 核心要点
- 现有方法在从演示中学习时,泛化能力不足,难以适应训练数据之外的场景,并且缺乏碰撞意识。
- Lan-o3dp框架利用语言引导和面向对象的扩散策略,通过3D点云条件下的扩散模型预测轨迹,并结合代价优化实现碰撞避免。
- 实验结果表明,Lan-o3dp在模拟和真实环境中均表现出优异的泛化能力和碰撞避免效果,成功率显著高于基线方法。
📝 摘要(中文)
本文提出了一种语言引导的、面向对象的扩散策略框架Lan-o3dp,该框架能够适应未见过的场景,如杂乱的场景、变化的相机视角和模糊的相似对象,同时提供免训练的碰撞避免,并以少量的演示实现高成功率。我们训练了一个以任务相关对象的3D点云为条件的扩散模型,以预测机器人的末端执行器轨迹,使其能够完成任务。在推理过程中,我们将代价优化纳入去噪步骤,以引导生成的轨迹无碰撞。我们利用开放集分割来获得相关对象的3D点云。我们使用大型语言模型通过解释用户的自然语言指令来识别目标对象和可能的障碍物。为了使用与时间无关的代价函数有效地引导条件扩散模型,我们提出了一种基于估计的干净轨迹的新型引导生成机制。在模拟中,我们表明,基于面向对象的3D表示的扩散策略,在21个具有挑战性的RLBench任务中,仅使用40个演示,与简单的2D(39.3%)和3D场景(43.6%)表示的基线相比,实现了更高的成功率(68.7%)。在真实世界的实验中,我们广泛评估了各种未见情况下的泛化能力,并验证了所提出的零样本代价引导碰撞避免的有效性。
🔬 方法详解
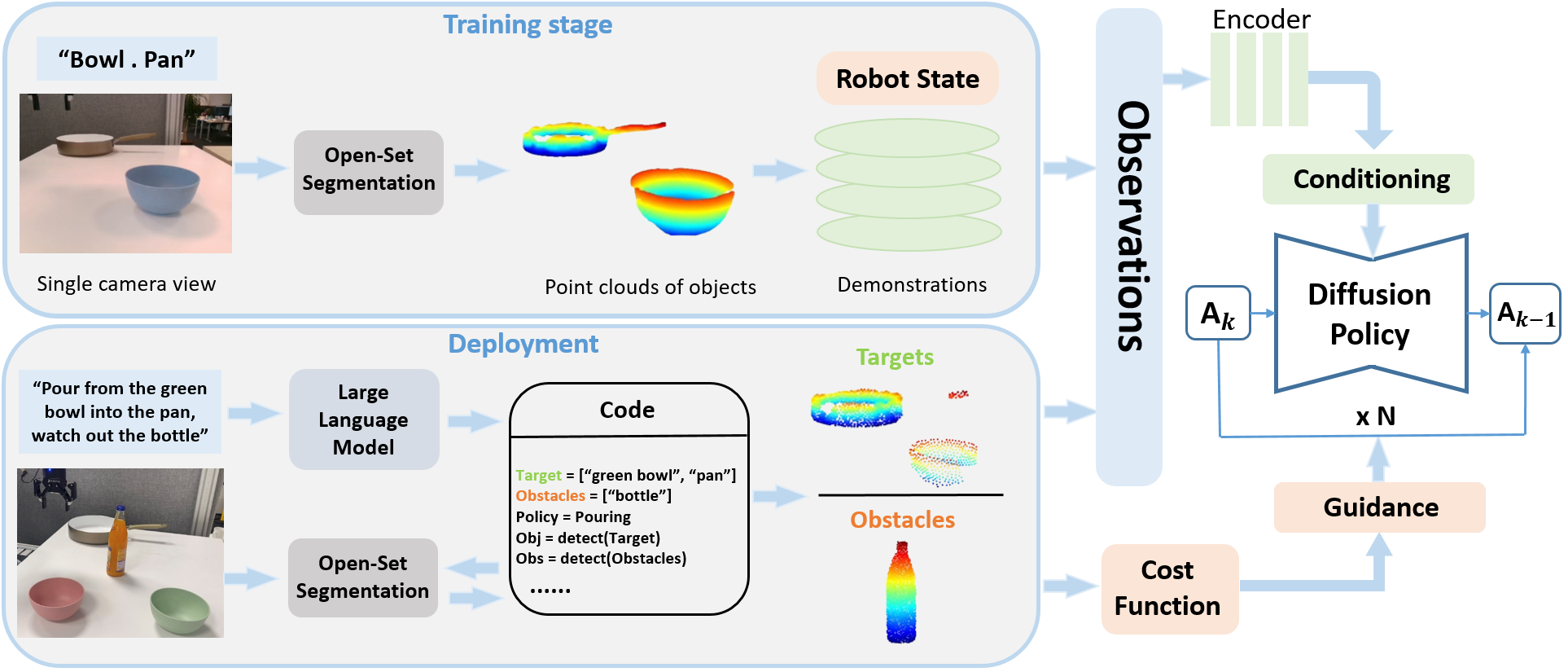
问题定义:论文旨在解决机器人操作任务中,从少量演示数据学习策略,并使其具备良好的泛化能力和碰撞避免能力的问题。现有方法通常难以泛化到新的场景,例如不同的物体排列、相机视角变化等,并且缺乏有效的碰撞避免机制,容易导致机器人与环境发生碰撞。
核心思路:论文的核心思路是利用扩散模型学习机器人末端执行器的轨迹,并以任务相关对象的3D点云作为条件,从而使策略能够理解场景中的物体关系,提高泛化能力。同时,在扩散模型的去噪过程中,引入代价优化,引导生成的轨迹避开障碍物,实现碰撞避免。利用大型语言模型理解用户指令,提取目标物体信息。
技术框架:Lan-o3dp框架主要包含以下几个模块:1) 开放集分割模块:用于从场景中分割出任务相关的对象,并生成3D点云表示。2) 语言理解模块:利用大型语言模型解析用户指令,识别目标对象和潜在障碍物。3) 扩散模型:以3D点云为条件,学习机器人末端执行器的轨迹分布。4) 代价优化模块:在扩散模型的去噪过程中,引入代价函数,引导生成的轨迹避开障碍物。
关键创新:论文的关键创新在于:1) 提出了一种语言引导的、面向对象的扩散策略框架,能够有效地利用场景中的物体信息,提高泛化能力。2) 将代价优化融入扩散模型的去噪过程,实现免训练的碰撞避免。3) 提出了一种基于估计的干净轨迹的新型引导生成机制,用于指导条件扩散模型。
关键设计:扩散模型使用U-Net结构,以3D点云作为条件输入。代价函数的设计考虑了机器人与障碍物之间的距离,距离越近,代价越高。在去噪过程中,通过梯度下降的方式,优化轨迹,使其代价最小化。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片
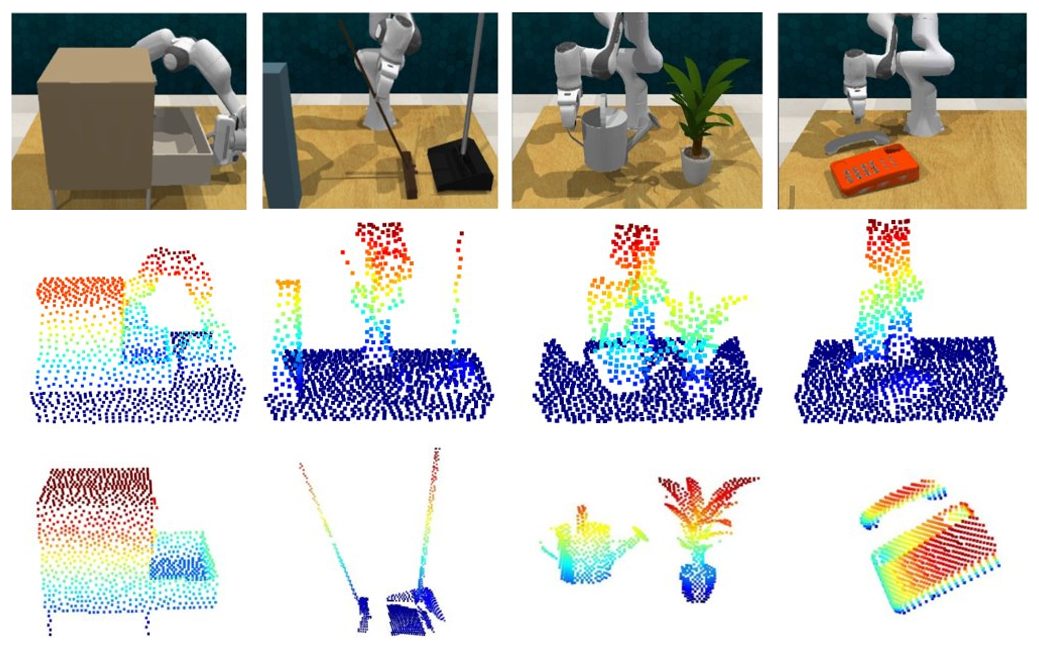

📊 实验亮点
在模拟实验中,Lan-o3dp在21个RLBench任务上,仅使用40个演示,就达到了68.7%的成功率,显著高于基于2D(39.3%)和3D场景(43.6%)表示的基线方法。在真实世界的实验中,Lan-o3dp展示了良好的泛化能力和碰撞避免效果,验证了其在复杂环境中的实用性。
🎯 应用场景
该研究成果可应用于各种需要机器人进行操作的场景,例如工业自动化、家庭服务、医疗辅助等。通过自然语言指令,用户可以方便地指导机器人完成复杂的任务,并且机器人能够自主地避开障碍物,保证安全。该技术有望降低机器人使用的门槛,并提高机器人的智能化水平。
📄 摘要(原文)
Learning from demonstrations faces challenges in generalizing beyond the training data and often lacks collision awareness. This paper introduces Lan-o3dp, a language-guided object-centric diffusion policy framework that can adapt to unseen situations such as cluttered scenes, shifting camera views, and ambiguous similar objects while offering training-free collision avoidance and achieving a high success rate with few demonstrations. We train a diffusion model conditioned on 3D point clouds of task-relevant objects to predict the robot's end-effector trajectories, enabling it to complete the tasks. During inference, we incorporate cost optimization into denoising steps to guide the generated trajectory to be collision-free. We leverage open-set segmentation to obtain the 3D point clouds of related objects. We use a large language model to identify the target objects and possible obstacles by interpreting the user's natural language instructions. To effectively guide the conditional diffusion model using a time-independent cost function, we proposed a novel guided generation mechanism based on the estimated clean trajectories. In the simulation, we showed that diffusion policy based on the object-centric 3D representation achieves a much higher success rate (68.7%) compared to baselines with simple 2D (39.3%) and 3D scene (43.6%) representations across 21 challenging RLBench tasks with only 40 demonstrations. In real-world experiments, we extensively evaluated the generalization in various unseen situations and validated the effectiveness of the proposed zero-shot cost-guided collision avoidance.