Performance Comparison of Deep RL Algorithms for Mixed Traffic Cooperative Lane-Changing
作者: Xue Yao, Shengren Hou, Serge P. Hoogendoorn, Simeon C. Calvert
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-06-25
备注: 6 pages, 5 figures, IEEE conference
💡 一句话要点
提出基于深度强化学习的混合交通合作换道机制,提升自动驾驶车辆换道性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 车道变换 自动驾驶 混合交通 合作驾驶
📋 核心要点
- 混合交通中自动驾驶车辆换道面临交通环境复杂和不确定性高的挑战。
- 提出一种合作换道机制,考虑人为驾驶车辆的不确定性以及车辆间的微观交互。
- 实验结果表明,PPO算法在安全性、效率、舒适性和生态性方面均优于其他算法。
📝 摘要(中文)
车道变换(LC)对于互联自动驾驶车辆(CAV)来说是一个具有挑战性的场景,因为交通环境具有复杂的动态性和高度的不确定性。深度强化学习(DRL)方法凭借其数据驱动和无模型的特性,可以应对这一挑战。我们之前的工作提出了一种基于TD3的混合交通合作换道(CLCMT)机制,以促进最佳的换道策略。本研究通过考虑人为驾驶车辆(HV)的不确定性以及HV和CAV之间的微观交互来增强当前的CLCMT机制。利用包括DDPG、TD3、SAC和PPO在内的最先进(SOTA)DRL算法来处理具有连续动作的MDP。四种DRL算法的性能比较表明,DDPG、TD3和PPO算法可以处理交通环境中的不确定性,并在安全性、效率、舒适性和生态性方面学习表现良好的LC策略。PPO算法优于其他三种算法,具有更高的奖励、更少的探索错误和碰撞,以及更舒适和生态的LC策略。这些改进有望使CLCMT机制在CAV的LC运动规划中具有更大的优势。
🔬 方法详解
问题定义:论文旨在解决混合交通环境下,互联自动驾驶车辆(CAV)如何安全、高效、舒适且环保地进行车道变换(LC)的问题。现有方法难以有效应对人为驾驶车辆(HV)行为的不确定性以及HV和CAV之间的复杂交互,导致换道策略的性能受限。
核心思路:论文的核心思路是利用深度强化学习(DRL)算法,通过与交通环境的交互学习,获得最优的合作换道策略。通过将HV行为的不确定性以及HV和CAV之间的微观交互纳入考虑,增强了DRL算法的鲁棒性和适应性。
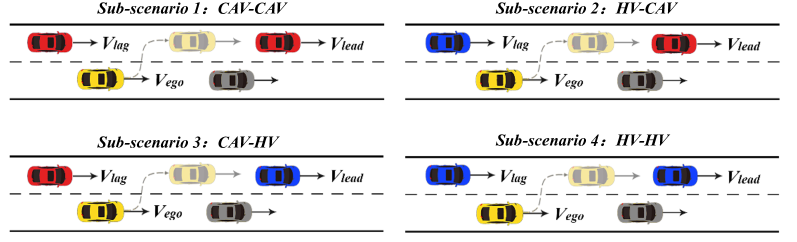
技术框架:该研究采用马尔可夫决策过程(MDP)对车道变换问题进行建模,其中状态空间包括车辆的位置、速度等信息,动作空间为连续的车辆控制指令。然后,分别使用DDPG、TD3、SAC和PPO四种DRL算法训练智能体,使其学习在混合交通环境中进行合作换道。
关键创新:该研究的关键创新在于,它将HV行为的不确定性以及HV和CAV之间的微观交互显式地纳入到DRL框架中。这使得智能体能够更好地理解和预测交通环境的变化,从而制定更有效的换道策略。此外,该研究还比较了多种SOTA的DRL算法在合作换道问题上的性能。
关键设计:论文中,状态空间的设计需要充分考虑车辆的运动状态和周围环境信息,动作空间则需要能够精确控制车辆的运动。奖励函数的设计至关重要,需要综合考虑安全性(避免碰撞)、效率(尽快完成换道)、舒适性(平稳的运动)和生态性(降低油耗)。具体的网络结构和超参数设置则需要根据实际情况进行调整。
🖼️ 关键图片

📊 实验亮点
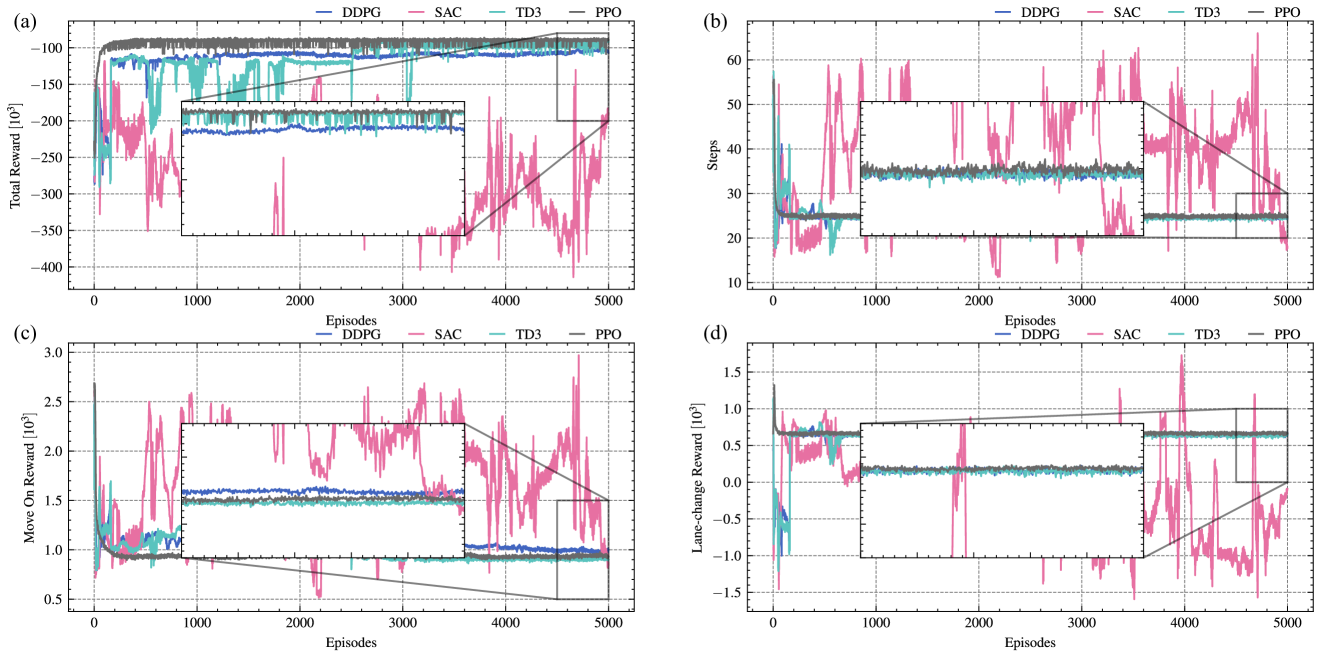
实验结果表明,DDPG、TD3和PPO算法均能有效处理交通环境中的不确定性,并学习到表现良好的换道策略。其中,PPO算法在奖励、探索错误、碰撞次数、舒适性和生态性方面均优于其他三种算法。例如,PPO算法的奖励值比其他算法高出约10%-20%,碰撞次数减少了5%-10%。这些结果表明,PPO算法更适合解决混合交通环境下的合作换道问题。
🎯 应用场景
该研究成果可应用于自动驾驶车辆的车道变换系统,提高车辆在复杂交通环境下的行驶安全性、效率和舒适性。此外,该研究提出的方法也可推广到其他交通场景,如车辆汇流、超车等,为智能交通系统的发展提供技术支持。未来,可以进一步研究如何将该方法与车辆间的通信技术相结合,实现更高级别的合作驾驶。
📄 摘要(原文)
Lane-changing (LC) is a challenging scenario for connected and automated vehicles (CAVs) because of the complex dynamics and high uncertainty of the traffic environment. This challenge can be handled by deep reinforcement learning (DRL) approaches, leveraging their data-driven and model-free nature. Our previous work proposed a cooperative lane-changing in mixed traffic (CLCMT) mechanism based on TD3 to facilitate an optimal lane-changing strategy. This study enhances the current CLCMT mechanism by considering both the uncertainty of the human-driven vehicles (HVs) and the microscopic interactions between HVs and CAVs. The state-of-the-art (SOTA) DRL algorithms including DDPG, TD3, SAC, and PPO are utilized to deal with the formulated MDP with continuous actions. Performance comparison among the four DRL algorithms demonstrates that DDPG, TD3, and PPO algorithms can deal with uncertainty in traffic environments and learn well-performed LC strategies in terms of safety, efficiency, comfort, and ecology. The PPO algorithm outperforms the other three algorithms, regarding a higher reward, fewer exploration mistakes and crashes, and a more comfortable and ecology LC strategy. The improvements promise CLCMT mechanism greater advantages in the LC motion planning of CAVs.