EXTRACT: Efficient Policy Learning by Extracting Transferable Robot Skills from Offline Data
作者: Jesse Zhang, Minho Heo, Zuxin Liu, Erdem Biyik, Joseph J Lim, Yao Liu, Rasool Fakoor
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-06-25 (更新: 2024-09-19)
备注: 25 pages, 16 figures
期刊: CoRL 2024
💡 一句话要点
EXTRACT:从离线数据中提取可迁移机器人技能以实现高效策略学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 强化学习 技能学习 离线学习 视觉语言模型 迁移学习 参数化技能
📋 核心要点
- 现有强化学习方法在迁移性方面存在不足,难以适应新任务。
- EXTRACT利用预训练视觉语言模型,从离线数据中无监督地提取参数化的、语义上有意义的技能。
- 实验表明,EXTRACT在样本效率和性能上优于先前的基于技能的强化学习方法,能更快地学习新任务。
📝 摘要(中文)
大多数强化学习(RL)方法侧重于在低级动作空间上学习最优策略。虽然这些方法在训练环境中表现良好,但缺乏迁移到新任务的灵活性。相比之下,能够基于有用的、时序扩展的技能而非低级动作进行行动的RL智能体,可以更容易地学习新任务。先前基于技能的RL工作要么需要专家监督来定义有用的技能(难以扩展),要么从离线数据中学习技能空间,但启发式方法限制了技能的适应性,使得它们在下游RL中难以迁移。我们的方法EXTRACT,利用预训练的视觉语言模型从离线数据中提取一组离散的、语义上有意义的技能,每个技能都由连续参数参数化,无需人工监督。这种技能参数化允许机器人仅需学习何时选择特定技能以及如何针对特定任务修改其参数即可学习新任务。通过在稀疏奖励、基于图像的机器人操作环境中的实验,我们证明EXTRACT比先前的工作更快地学习新任务,在样本效率和性能方面都优于先前的基于技能的RL方法。
🔬 方法详解
问题定义:现有基于技能的强化学习方法面临两个主要问题:一是需要专家知识来定义技能,这限制了其可扩展性;二是直接从离线数据学习技能空间,但由于启发式方法的限制,导致学习到的技能难以适应新的任务,迁移性较差。因此,如何自动、高效地从离线数据中提取可迁移的机器人技能是一个关键问题。
核心思路:EXTRACT的核心思路是利用预训练的视觉语言模型,从离线数据中提取一组离散的、语义上有意义的技能,并对这些技能进行参数化。通过这种方式,机器人可以通过学习何时选择哪个技能以及如何调整技能的参数来适应新的任务,从而提高学习效率和迁移能力。
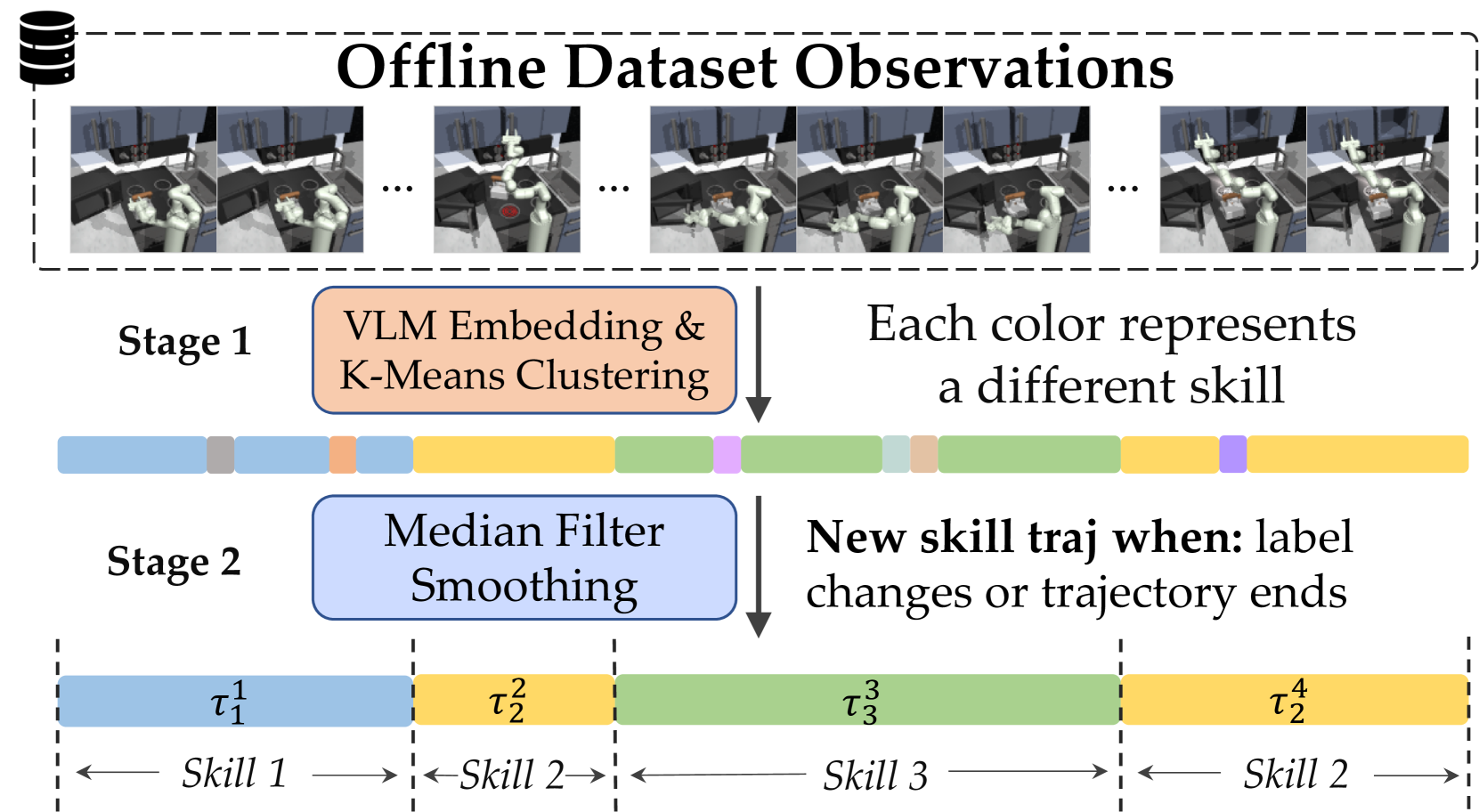
技术框架:EXTRACT的整体框架包括以下几个主要阶段:1) 离线数据收集:收集机器人执行各种任务的离线数据。2) 技能提取:利用预训练的视觉语言模型,从离线数据中提取一组离散的技能,每个技能对应一个语义上有意义的动作。3) 技能参数化:对每个技能进行参数化,使其可以通过连续的参数进行调整。4) 策略学习:使用强化学习算法,学习一个策略,该策略决定何时选择哪个技能以及如何调整其参数,以完成特定的任务。
关键创新:EXTRACT最重要的技术创新点在于利用预训练的视觉语言模型,实现了从离线数据中无监督地提取可迁移的机器人技能。与现有方法相比,EXTRACT无需专家知识,并且能够学习到更具适应性的技能,从而提高了学习效率和迁移能力。
关键设计:EXTRACT的关键设计包括:1) 使用预训练的视觉语言模型(例如CLIP)来提取技能,利用其强大的语义理解能力。2) 将技能参数化为连续的向量,允许对技能进行细粒度的调整。3) 使用Actor-Critic算法来学习策略,其中Actor网络选择技能和参数,Critic网络评估当前状态下选择的技能和参数的价值。
🖼️ 关键图片


📊 实验亮点
实验结果表明,EXTRACT在稀疏奖励、基于图像的机器人操作环境中,比先前的基于技能的RL方法更快地学习新任务。具体而言,EXTRACT在样本效率方面取得了显著提升,并且在最终性能方面也优于其他基线方法。论文展示了在多个不同任务上的实验结果,验证了EXTRACT的有效性和泛化能力。
🎯 应用场景
EXTRACT具有广泛的应用前景,可以应用于各种机器人操作任务,例如物体抓取、装配、导航等。该方法可以显著降低机器人学习新任务的成本,提高机器人的自主性和适应性。未来,可以将EXTRACT与其他技术(例如模仿学习、元学习)相结合,进一步提高机器人的学习能力和泛化能力。
📄 摘要(原文)
Most reinforcement learning (RL) methods focus on learning optimal policies over low-level action spaces. While these methods can perform well in their training environments, they lack the flexibility to transfer to new tasks. Instead, RL agents that can act over useful, temporally extended skills rather than low-level actions can learn new tasks more easily. Prior work in skill-based RL either requires expert supervision to define useful skills, which is hard to scale, or learns a skill-space from offline data with heuristics that limit the adaptability of the skills, making them difficult to transfer during downstream RL. Our approach, EXTRACT, instead utilizes pre-trained vision language models to extract a discrete set of semantically meaningful skills from offline data, each of which is parameterized by continuous arguments, without human supervision. This skill parameterization allows robots to learn new tasks by only needing to learn when to select a specific skill and how to modify its arguments for the specific task. We demonstrate through experiments in sparse-reward, image-based, robot manipulation environments that EXTRACT can more quickly learn new tasks than prior works, with major gains in sample efficiency and performance over prior skill-based RL. Website at https://www.jessezhang.net/projects/extract/.