Gaussian Splatting to Real World Flight Navigation Transfer with Liquid Networks
作者: Alex Quach, Makram Chahine, Alexander Amini, Ramin Hasani, Daniela Rus
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-06-21 (更新: 2024-10-16)
💡 一句话要点
利用高斯溅射和Liquid网络实现视觉四旋翼无人机真实环境导航迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 高斯溅射 Liquid网络 Sim-to-Real 视觉导航 四旋翼无人机 模仿学习 机器人学习
📋 核心要点
- 现有方法在模拟器中学习的机器人行为难以迁移到真实世界,通常需要大量的计算资源进行领域随机化或模型微调。
- 本文提出了一种基于高斯溅射和Liquid神经网络的模仿学习方法,旨在提高sim-to-real视觉四旋翼无人机导航的泛化性和鲁棒性。
- 实验结果表明,该方法在单个模拟场景中学习的导航技能可以直接迁移到真实世界,并在环境变化下保持性能。
📝 摘要(中文)
本文提出了一种方法,旨在提高模拟到真实世界(sim-to-real)视觉四旋翼无人机导航任务中的泛化能力和对分布偏移的鲁棒性。该方法首先通过将高斯溅射与四旋翼飞行动力学相结合来构建模拟器,然后使用Liquid神经网络训练鲁棒的导航策略。由此,我们获得了一个完整的模仿学习协议,该协议结合了3D高斯溅射辐射场渲染、专家演示训练数据的巧妙编程以及Liquid网络的任务理解能力。通过一系列定量飞行测试,我们证明了在单个模拟场景中学习的导航技能可以直接鲁棒地迁移到真实世界。我们进一步展示了在剧烈的分布和物理环境变化下,保持超出训练环境性能的能力。我们学习到的Liquid策略,仅在逼真的模拟室内飞行中精心策划的单目标机动上进行训练,可以推广到真实硬件平台上的户外多步飞行。
🔬 方法详解
问题定义:现有的sim-to-real方法在视觉导航任务中,通常需要大量的计算资源进行领域随机化或模型微调,以弥合模拟环境和真实环境之间的差距。这些方法难以保证在真实世界中具有足够的泛化性和鲁棒性,尤其是在面对未知的环境变化时。
核心思路:本文的核心思路是利用高斯溅射(Gaussian Splatting)构建逼真的模拟环境,并结合Liquid神经网络训练鲁棒的导航策略。高斯溅射能够高效地渲染高质量的3D场景,而Liquid神经网络具有动态拓扑结构,能够更好地适应环境变化,从而提高sim-to-real的迁移效果。
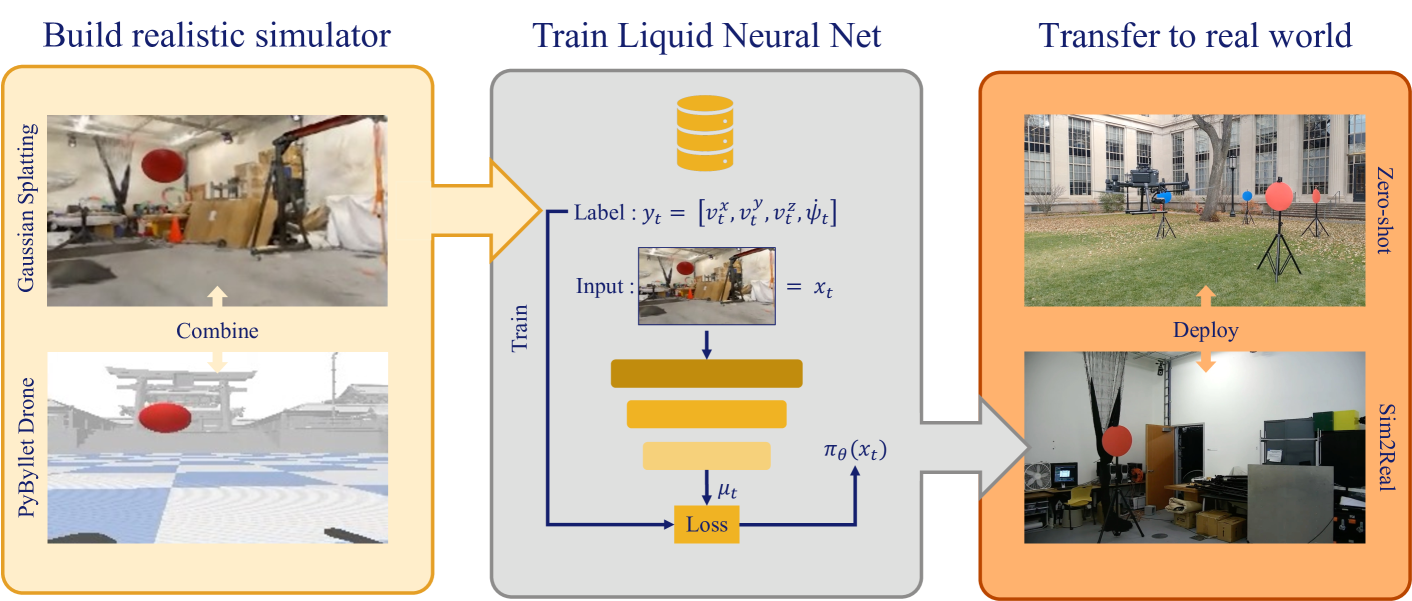
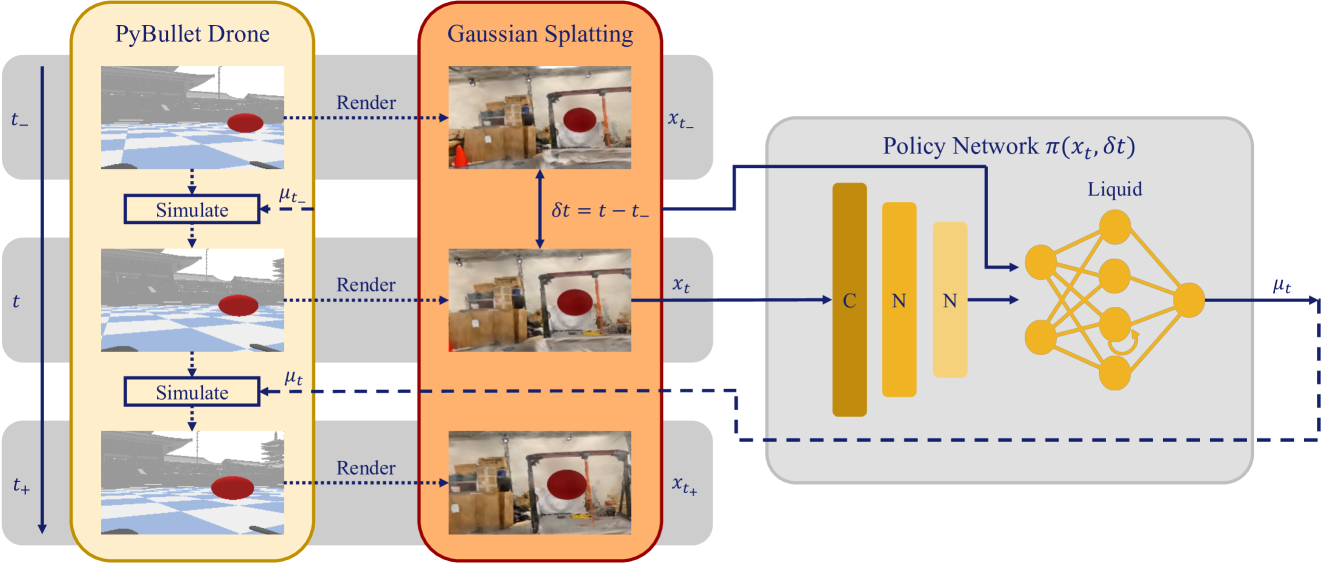
技术框架:该方法包含以下几个主要步骤:1) 使用高斯溅射构建模拟环境,该环境能够逼真地模拟真实世界的视觉特征。2) 通过专家演示生成训练数据,这些数据包含了四旋翼无人机在模拟环境中的导航轨迹。3) 使用Liquid神经网络训练导航策略,该策略能够根据视觉输入控制无人机的飞行。4) 在真实世界中进行飞行测试,验证导航策略的泛化性和鲁棒性。
关键创新:该方法的关键创新在于将高斯溅射和Liquid神经网络相结合,用于解决sim-to-real视觉导航问题。高斯溅射提供了一种高效且逼真的模拟环境构建方法,而Liquid神经网络则提供了一种具有良好泛化能力的控制策略学习方法。这种结合能够显著提高sim-to-real的迁移效果,并降低对大量计算资源的需求。
关键设计:在模拟环境构建方面,使用了高斯溅射来表示3D场景,并将其与四旋翼飞行动力学相结合。在导航策略学习方面,使用了Liquid神经网络,并设计了合适的损失函数来优化网络参数。具体而言,损失函数可能包括位置误差、速度误差和姿态误差等。此外,还可能采用了一些数据增强技术来提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
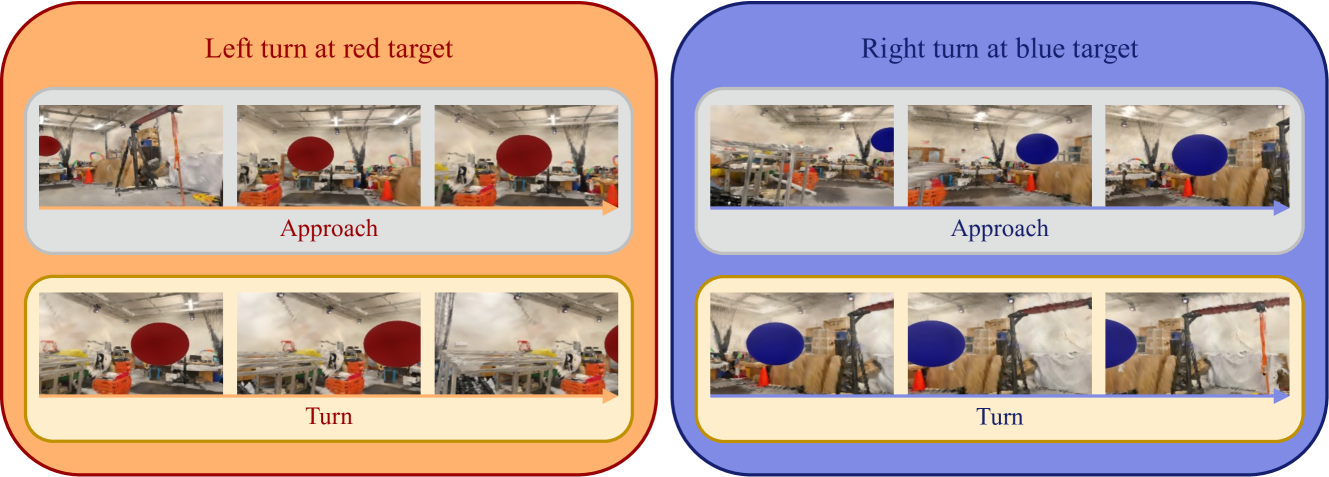
实验结果表明,该方法在单个模拟场景中学习的导航技能可以直接迁移到真实世界,并在环境变化下保持性能。具体而言,仅在模拟室内飞行中训练的Liquid策略,可以推广到真实硬件平台上的户外多步飞行。这表明该方法具有良好的泛化能力和鲁棒性,能够有效地解决sim-to-real迁移问题。
🎯 应用场景
该研究成果可应用于各种需要视觉导航的机器人系统,例如无人机巡检、自动驾驶、室内导航等。通过在模拟环境中训练导航策略,可以降低开发成本和风险,并提高机器人在真实世界中的适应能力。该方法还有潜力应用于其他sim-to-real迁移学习任务,例如机器人操作和强化学习。
📄 摘要(原文)
Simulators are powerful tools for autonomous robot learning as they offer scalable data generation, flexible design, and optimization of trajectories. However, transferring behavior learned from simulation data into the real world proves to be difficult, usually mitigated with compute-heavy domain randomization methods or further model fine-tuning. We present a method to improve generalization and robustness to distribution shifts in sim-to-real visual quadrotor navigation tasks. To this end, we first build a simulator by integrating Gaussian Splatting with quadrotor flight dynamics, and then, train robust navigation policies using Liquid neural networks. In this way, we obtain a full-stack imitation learning protocol that combines advances in 3D Gaussian splatting radiance field rendering, crafty programming of expert demonstration training data, and the task understanding capabilities of Liquid networks. Through a series of quantitative flight tests, we demonstrate the robust transfer of navigation skills learned in a single simulation scene directly to the real world. We further show the ability to maintain performance beyond the training environment under drastic distribution and physical environment changes. Our learned Liquid policies, trained on single target manoeuvres curated from a photorealistic simulated indoor flight only, generalize to multi-step hikes onboard a real hardware platform outdoors.