LIT: Large Language Model Driven Intention Tracking for Proactive Human-Robot Collaboration -- A Robot Sous-Chef Application
作者: Zhe Huang, John Pohovey, Ananya Yammanuru, Katherine Driggs-Campbell
分类: cs.RO, cs.CV
发布日期: 2024-06-19
备注: Spotlight Presentation at the 3rd Workshop on Computer Vision in the Wild at CVPR 2024. Also accepted by the 5th Annual Embodied AI Workshop at CVPR 2024
💡 一句话要点
提出LIT:基于大语言模型的意图跟踪,用于主动人机协作,应用于机器人厨师
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机协作 意图跟踪 大型语言模型 视觉语言模型 机器人厨师 主动机器人 长时程任务
📋 核心要点
- 现有方法在长时程人机协作中,需要频繁提示机器人,效率低下且不够自然。
- LIT利用LLM和VLM预测人类意图,使机器人能够主动配合,减少人为干预。
- 实验表明,LIT能够使机器人在协作烹饪任务中与人类用户实现更流畅的配合。
📝 摘要(中文)
本文提出了一种名为“语言驱动的意图跟踪”(LIT)的方法,该方法利用大型语言模型(LLM)和视觉语言模型(VLM)来建模人类用户的长期行为,并预测下一个人类意图,从而指导机器人进行主动协作。与现有方法在长时程协作任务中需要频繁提示机器人不同,LIT能够实现人机之间的流畅协调。论文通过协作烹饪任务验证了基于LIT的协作机器人在实际应用中的有效性。
🔬 方法详解
问题定义:现有的人机协作方法,尤其是在长时程任务中,通常需要用户在每一步都明确地指示或澄清机器人的行为。这导致了过多的提示,降低了协作效率,并且不够自然。论文旨在解决如何在长时程协作任务中,减少人为干预,使机器人能够主动理解并配合人类意图的问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)和视觉语言模型(VLM)来建模人类用户的长期行为,并预测其下一步的意图。通过预测人类意图,机器人可以主动地执行相应的动作,而无需用户显式地发出指令。这种方法使得人机协作更加流畅和自然。
技术框架:LIT框架包含以下几个主要模块:1) 感知模块:利用VLM感知环境状态,例如识别物体、动作等。2) 意图预测模块:利用LLM根据历史交互信息和当前环境状态,预测人类的下一步意图。3) 行为规划模块:根据预测的人类意图,规划机器人的行为。4) 执行模块:执行规划好的机器人行为。整个流程是一个循环迭代的过程,机器人不断感知环境、预测意图、规划行为和执行动作,从而实现与人类的协同。
关键创新:LIT的关键创新在于将LLM和VLM结合起来,用于建模和预测人类的长期意图。与传统的基于规则或有限状态机的方法相比,LIT能够处理更复杂的场景和更灵活的人类行为。此外,LIT通过预测意图,实现了机器人从被动执行到主动配合的转变。
关键设计:论文中,LLM被用于维护一个人类行为的长期记忆,并根据这个记忆来预测下一步的意图。VLM则负责感知环境状态,并将感知结果输入到LLM中。具体的LLM和VLM的选择以及训练方式,论文中可能没有详细说明,属于未知信息。损失函数的设计也未知,但推测会包含意图预测的准确性以及协作效率等方面的考虑。
🖼️ 关键图片

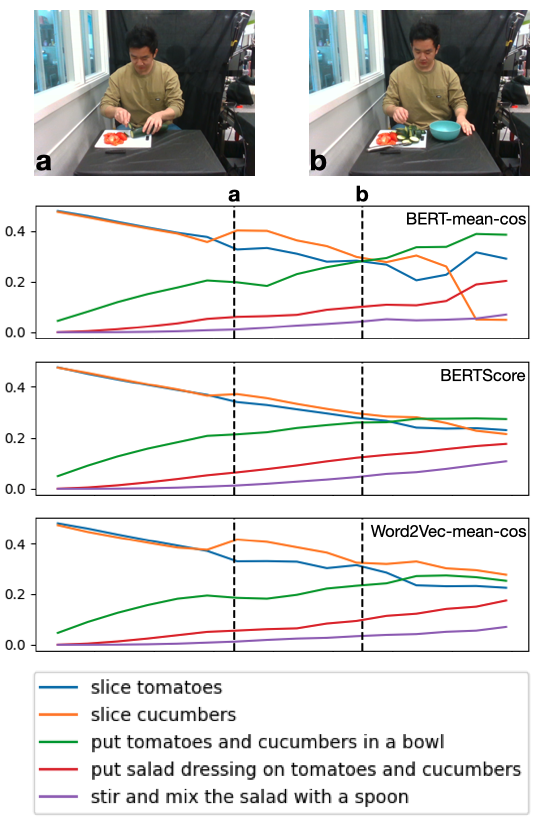
📊 实验亮点
论文通过协作烹饪任务验证了LIT的有效性。实验结果表明,基于LIT的协作机器人能够更准确地预测人类意图,并更流畅地与人类用户进行协作。具体的性能数据(例如意图预测准确率、协作完成时间等)在摘要中未提及,属于未知信息。与没有意图跟踪的基线方法相比,LIT能够显著减少人为干预,提高协作效率。
🎯 应用场景
LIT方法具有广泛的应用前景,例如智能家居、辅助机器人、工业自动化等领域。在智能家居中,机器人可以根据用户的日常习惯和当前行为,预测用户的需求并主动提供服务。在辅助机器人领域,机器人可以帮助残疾人或老年人完成各种任务,提高他们的生活质量。在工业自动化领域,机器人可以与工人协同完成生产任务,提高生产效率和安全性。
📄 摘要(原文)
Large Language Models (LLM) and Vision Language Models (VLM) enable robots to ground natural language prompts into control actions to achieve tasks in an open world. However, when applied to a long-horizon collaborative task, this formulation results in excessive prompting for initiating or clarifying robot actions at every step of the task. We propose Language-driven Intention Tracking (LIT), leveraging LLMs and VLMs to model the human user's long-term behavior and to predict the next human intention to guide the robot for proactive collaboration. We demonstrate smooth coordination between a LIT-based collaborative robot and the human user in collaborative cooking tasks.