Reinforcement Learning to improve delta robot throws for sorting scrap metal
作者: Arthur Louette, Gaspard Lambrechts, Damien Ernst, Eric Pirard, Godefroid Dislaire
分类: cs.RO
发布日期: 2024-06-19 (更新: 2024-06-21)
💡 一句话要点
提出基于强化学习的Delta机器人抛掷分拣方法,提升废金属分拣效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Delta机器人 抓取-抛掷 废金属分拣 领域随机化
📋 核心要点
- 传统抓取-放置方法效率较低,需要精确移动到目标位置,限制了分拣速度。
- 利用强化学习学习最优的释放位置和速度,实现抓取-抛掷,缩短分拣时间。
- 在仿真环境中验证了该方法,准确率达到89%,吞吐量提升51%,并成功迁移到真实环境。
📝 摘要(中文)
本研究提出了一种基于强化学习(RL)的新方法,旨在提高Delta机器人在废金属分拣中的效率,该方法采用工业界广泛使用的抓取-放置(PaP)流程。我们使用三种经典无模型的强化学习算法(TD3、SAC和PPO)来减少金属废料的分拣时间。我们学习释放物体的位置和速度,以便将物体抛入料箱,而不是像传统的PaP技术那样移动到精确的料箱位置。我们的贡献有三方面:首先,我们为学习基于强化学习的并行夹爪抓取-抛掷(PaT)策略提供了一个新的仿真环境。其次,我们使用强化学习算法在该环境中学习此任务,在仿真中实现了89%的准确率,同时吞吐量提高了51%。第三,我们评估了强化学习算法的性能,并将其与仿真和现实中的PaP和最先进的PaT方法进行了比较,仅从具有领域随机化的仿真中学习,而无需在现实中进行微调来转移我们的策略。这项工作表明,与工业界使用的PaP或经典优化PaT技术相比,基于强化学习的PaT具有优势。
🔬 方法详解
问题定义:传统废金属分拣依赖于Delta机器人的抓取-放置(PaP)策略,该策略需要机器人精确移动到目标料箱上方才能释放物体,导致分拣速度受限。现有优化抛掷轨迹的PaT方法需要复杂的建模和优化过程,泛化能力较弱。因此,需要一种更高效、更具适应性的分拣方法。
核心思路:本研究的核心思路是利用强化学习(RL)直接学习Delta机器人的抓取-抛掷(PaT)策略。通过让机器人在仿真环境中不断试错,学习在不同状态下最优的释放位置和速度,从而实现快速、准确的分拣。这种方法避免了复杂的运动学建模和轨迹规划,提高了系统的鲁棒性和适应性。
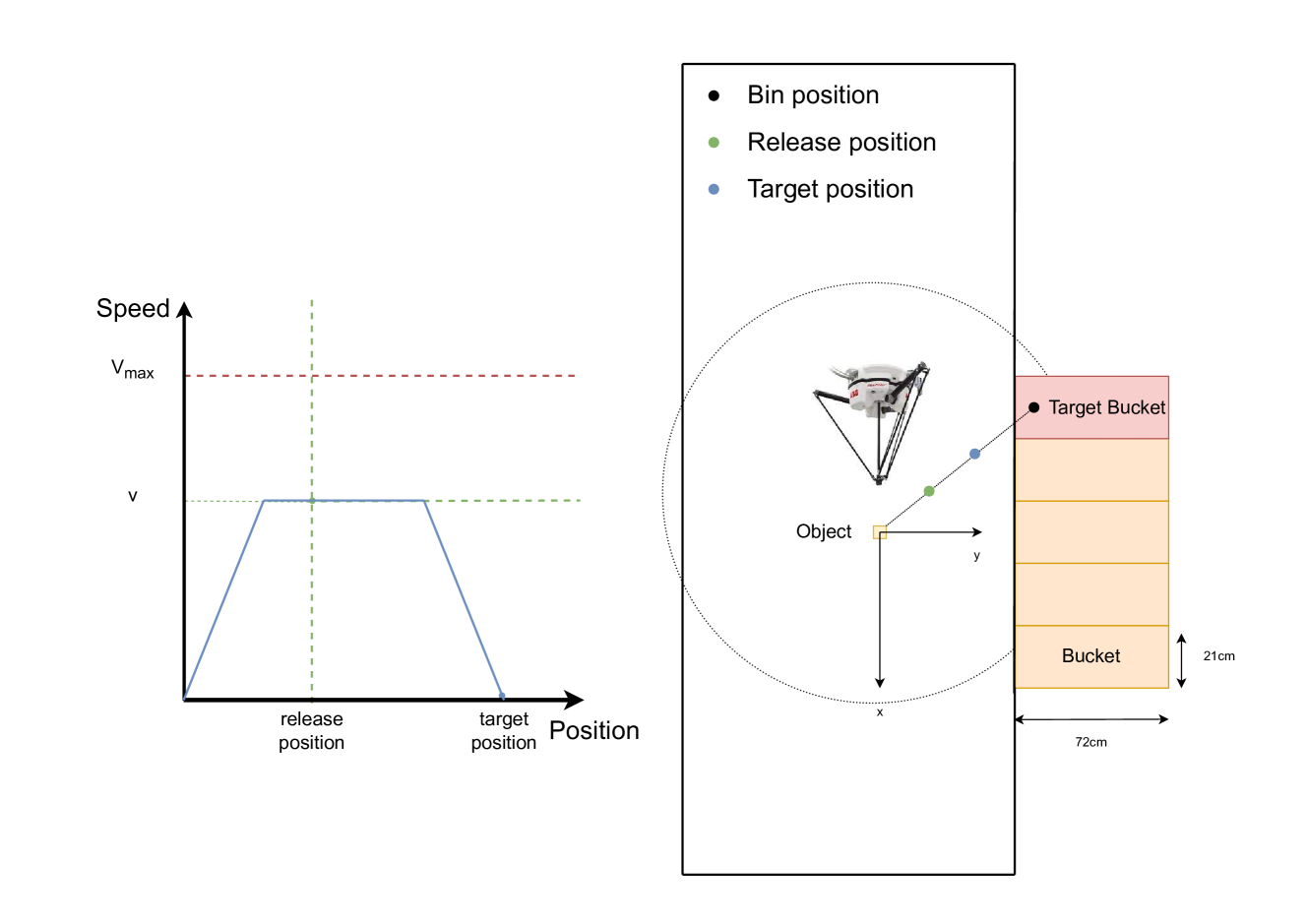
技术框架:该研究的技术框架主要包括以下几个部分:1) 基于PyBullet的仿真环境,用于训练RL智能体;2) 三种无模型强化学习算法(TD3、SAC和PPO),用于学习最优的抛掷策略;3) 领域随机化技术,用于提高策略从仿真到现实的迁移能力;4) Delta机器人平台,用于在真实环境中验证学习到的策略。整体流程是:在仿真环境中训练RL智能体,然后将训练好的策略部署到真实机器人上进行测试。
关键创新:该研究的关键创新在于将强化学习应用于Delta机器人的抓取-抛掷任务,并提出了一种基于领域随机化的仿真训练方法,实现了策略从仿真到现实的有效迁移。与传统的PaP方法相比,该方法能够显著提高分拣速度。与传统的优化PaT方法相比,该方法无需复杂的建模和优化过程,更具适应性和鲁棒性。
关键设计:在仿真环境中,状态空间包括物体的位置、速度和机器人的关节角度等信息。动作空间包括释放物体的位置和速度。奖励函数的设计旨在鼓励智能体将物体抛入正确的料箱,并惩罚抛掷失败的情况。领域随机化技术用于随机化仿真环境中的参数,如摩擦系数、物体质量等,以提高策略的泛化能力。三种RL算法(TD3、SAC和PPO)均采用默认参数设置,并通过实验选择性能最佳的算法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于强化学习的抓取-抛掷策略在仿真环境中实现了89%的准确率,同时吞吐量提高了51%,显著优于传统的抓取-放置方法。通过领域随机化,该策略能够成功迁移到真实机器人上,无需额外的微调,验证了该方法的有效性和实用性。与最先进的PaT方法相比,该方法也展现出更强的适应性和鲁棒性。
🎯 应用场景
该研究成果可应用于自动化废金属分拣、物料处理、以及其他需要高速、高精度分拣的工业场景。通过强化学习优化机器人操作,可以显著提高生产效率,降低人工成本,并提升资源回收利用率。未来,该技术有望扩展到更复杂的机器人操作任务中。
📄 摘要(原文)
This study proposes a novel approach based on reinforcement learning (RL) to enhance the sorting efficiency of scrap metal using delta robots and a Pick-and-Place (PaP) process, widely used in the industry. We use three classical model-free RL algorithms (TD3, SAC and PPO) to reduce the time to sort metal scraps. We learn the release position and speed needed to throw an object in a bin instead of moving to the exact bin location, as with the classical PaP technique. Our contribution is threefold. First, we provide a new simulation environment for learning RL-based Pick-and-Throw (PaT) strategies for parallel grippers. Second, we use RL algorithms for learning this task in this environment resulting in 89% accuracy while speeding up the throughput by 51% in simulation. Third, we evaluate the performances of RL algorithms and compare them to a PaP and a state-of-the-art PaT method both in simulation and reality, learning only from simulation with domain randomisation and without fine tuning in reality to transfer our policies. This work shows the benefits of RL-based PaT compared to PaP or classical optimization PaT techniques used in the industry.