Online Pareto-Optimal Decision-Making for Complex Tasks using Active Inference
作者: Peter Amorese, Shohei Wakayama, Nisar Ahmed, Morteza Lahijanian
分类: cs.RO, cs.AI
发布日期: 2024-06-17
备注: 17 pages, 10 figures, submitted to IEEE Transactions on Robotics journal
💡 一句话要点
提出基于主动推理的在线帕累托最优决策框架,用于复杂任务中的多目标优化。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标强化学习 主动推理 帕累托最优 机器人决策 用户偏好
📋 核心要点
- 复杂任务中,机器人需在不确定环境中平衡多个目标并保证安全,现有方法难以兼顾。
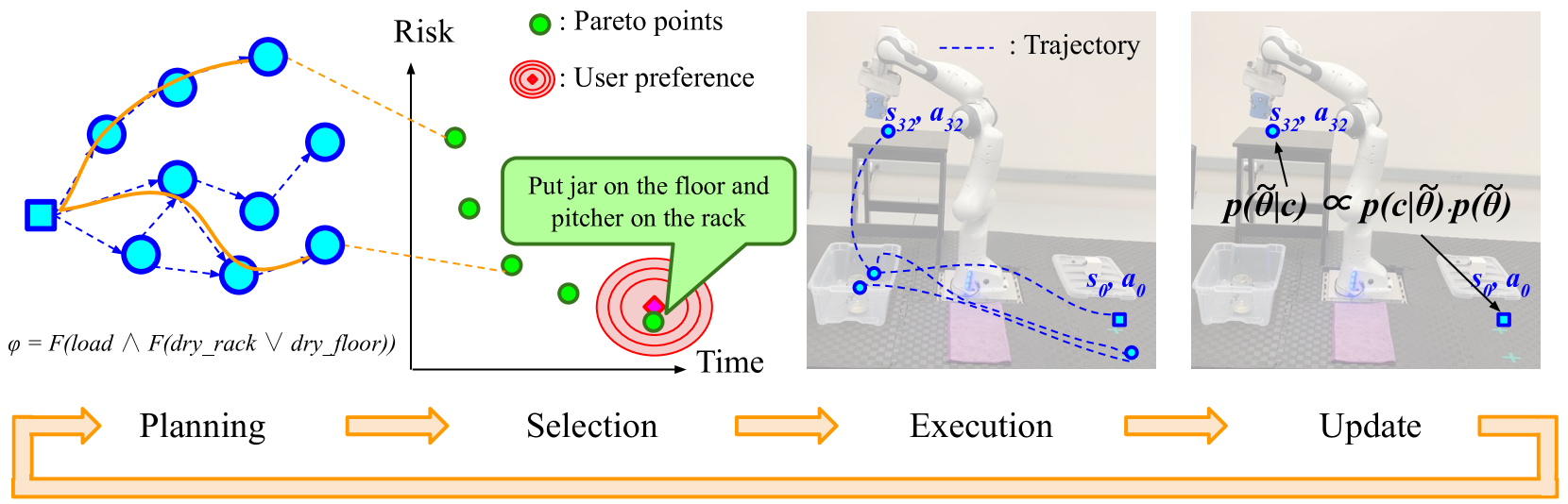
- 提出双层框架:规划层生成满足时序逻辑任务的帕累托最优方案,选择层利用主动推理选择符合用户偏好的方案。
- 实验表明,该框架优于其他方法,能学习多个最优权衡,遵守用户偏好,并允许用户调整目标与偏好间的平衡。
📝 摘要(中文)
本文提出了一种用于多目标强化学习的新框架,该框架旨在确保安全地执行任务,优化目标之间的权衡,并遵循用户偏好。该框架包含两个主要层:多目标任务规划器和高层选择器。规划层生成一组保证满足时序逻辑任务的最优权衡方案。选择器使用主动推理来决定哪个生成的方案最符合用户偏好并辅助学习。该框架以迭代方式运行,并根据收集的数据更新参数化的学习模型。在操作和移动机器人上的案例研究和基准测试表明,我们的框架优于其他方法,并且(i)学习多个最优权衡,(ii)遵守用户偏好,以及(iii)允许用户调整(i)和(ii)之间的平衡。
🔬 方法详解
问题定义:现有方法在复杂任务中难以同时兼顾多个相互竞争的目标、保证安全性,以及满足用户偏好。尤其是在不确定性环境中,如何在线学习并做出帕累托最优决策是一个挑战。传统的强化学习方法通常难以处理多目标优化问题,且缺乏对用户偏好的有效整合。
核心思路:该论文的核心思路是将多目标优化问题分解为两个层次:首先,通过多目标任务规划器生成一组帕累托最优的方案,这些方案代表了不同目标之间的权衡。然后,利用一个高层选择器,基于主动推理,从这些方案中选择最符合用户偏好的方案。这种分层结构使得系统能够有效地探索不同的权衡方案,并根据用户反馈进行学习和调整。
技术框架:该框架包含两个主要模块:多目标任务规划器和高层选择器。多目标任务规划器负责生成一组满足时序逻辑任务的帕累托最优方案。高层选择器使用主动推理来选择最符合用户偏好的方案,并利用收集到的数据更新参数化的学习模型。整个框架以迭代方式运行,不断优化方案选择和用户偏好学习。
关键创新:该论文的关键创新在于将主动推理引入到多目标强化学习的选择器中。主动推理允许系统主动探索不同的方案,并根据用户反馈进行学习,从而更有效地找到符合用户偏好的最优解。此外,该框架能够在线学习并适应用户偏好的变化,使其更具灵活性和适应性。
关键设计:多目标任务规划器使用时序逻辑来描述任务约束,并生成满足这些约束的帕累托最优方案。高层选择器使用主动推理模型,该模型包含一个预测模型和一个控制策略。预测模型用于预测不同方案的执行结果,控制策略用于选择下一个要执行的方案。损失函数的设计旨在最大化用户偏好和任务目标的完成度,同时考虑安全性约束。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架在操作和移动机器人任务中均优于其他方法。具体来说,该框架能够学习多个最优权衡方案,遵守用户偏好,并允许用户调整目标与偏好之间的平衡。虽然论文中没有给出具体的性能数据和提升幅度,但实验结果表明该框架具有显著的优势。
🎯 应用场景
该研究成果可应用于各种需要平衡多个目标并考虑用户偏好的机器人任务中,例如自动驾驶、服务机器人、工业自动化等。通过学习用户偏好并进行在线优化,机器人可以更好地适应不同的应用场景,提高任务完成效率和用户满意度。未来,该框架有望扩展到更复杂的任务和更广泛的应用领域。
📄 摘要(原文)
When a robot autonomously performs a complex task, it frequently must balance competing objectives while maintaining safety. This becomes more difficult in uncertain environments with stochastic outcomes. Enhancing transparency in the robot's behavior and aligning with user preferences are also crucial. This paper introduces a novel framework for multi-objective reinforcement learning that ensures safe task execution, optimizes trade-offs between objectives, and adheres to user preferences. The framework has two main layers: a multi-objective task planner and a high-level selector. The planning layer generates a set of optimal trade-off plans that guarantee satisfaction of a temporal logic task. The selector uses active inference to decide which generated plan best complies with user preferences and aids learning. Operating iteratively, the framework updates a parameterized learning model based on collected data. Case studies and benchmarks on both manipulation and mobile robots show that our framework outperforms other methods and (i) learns multiple optimal trade-offs, (ii) adheres to a user preference, and (iii) allows the user to adjust the balance between (i) and (ii).