Embodied Instruction Following in Unknown Environments
作者: Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Hang Yin, Yinan Liang, Angyuan Ma, Jiwen Lu, Haibin Yan
分类: cs.RO, cs.AI
发布日期: 2024-06-17 (更新: 2025-07-02)
备注: Project Page: https://gary3410.github.io/eif_unknown/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于多模态大语言模型的具身智能指令跟随方法,解决未知环境下的复杂任务规划问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 指令跟随 未知环境 多模态大语言模型 任务规划 环境探索 动态区域注意力
📋 核心要点
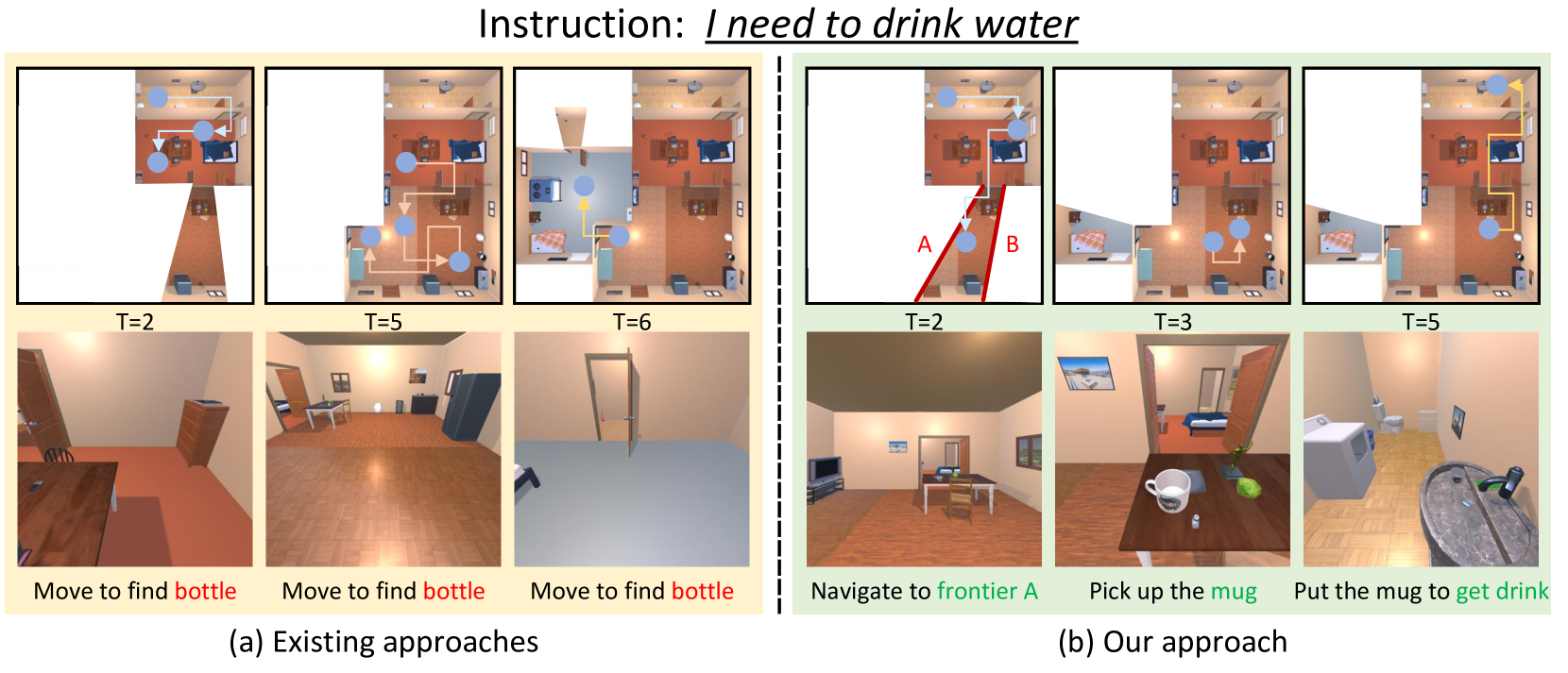
- 现有具身智能方法难以在未知环境中执行复杂指令,主要挑战在于无法处理环境中不存在的目标对象。
- 该方法构建分层框架,利用多模态大语言模型进行任务规划和探索控制,并构建动态区域注意力语义地图。
- 实验结果表明,该方法在复杂指令跟随任务中取得了显著的成功率,验证了其在未知环境中的有效性。
📝 摘要(中文)
本文提出了一种用于未知环境中复杂任务的具身智能指令跟随(EIF)方法。现有方法通常只能在已知环境中完成指令,而在未知环境中直接应用会导致生成操纵不存在对象的不可行计划。本文方法通过高效探索未知环境,并利用现有对象生成可行的计划来完成抽象指令。具体而言,构建了一个分层EIF框架,包含高级任务规划器和低级探索控制器,并结合多模态大语言模型。同时,构建了一个具有动态区域注意力的场景语义表示图,以展示已知的视觉线索,从而对齐任务规划和场景探索的目标。任务规划器根据任务完成过程和已知的视觉线索,生成逐步可行的计划。探索控制器基于生成的逐步计划和已知的视觉线索,预测最优的导航或对象交互策略。实验结果表明,该方法在大型住宅场景中,对于诸如制作早餐和整理房间等204个复杂的人工指令,成功率达到了45.09%。
🔬 方法详解
问题定义:现有具身智能指令跟随方法主要针对已知环境,依赖于预先提供的交互对象。在未知环境中,由于缺乏对环境的先验知识,智能体难以找到或识别目标对象,导致生成的任务计划不可行,无法完成用户指令。因此,如何在未知环境中让具身智能体理解并执行复杂指令是一个关键问题。
核心思路:本文的核心思路是利用多模态大语言模型(MLLM)的强大推理和规划能力,结合环境探索,逐步构建对未知环境的认知,并根据已知的视觉线索生成可行的任务计划。通过动态区域注意力机制,聚焦于与任务相关的区域,提高探索效率和任务完成的成功率。
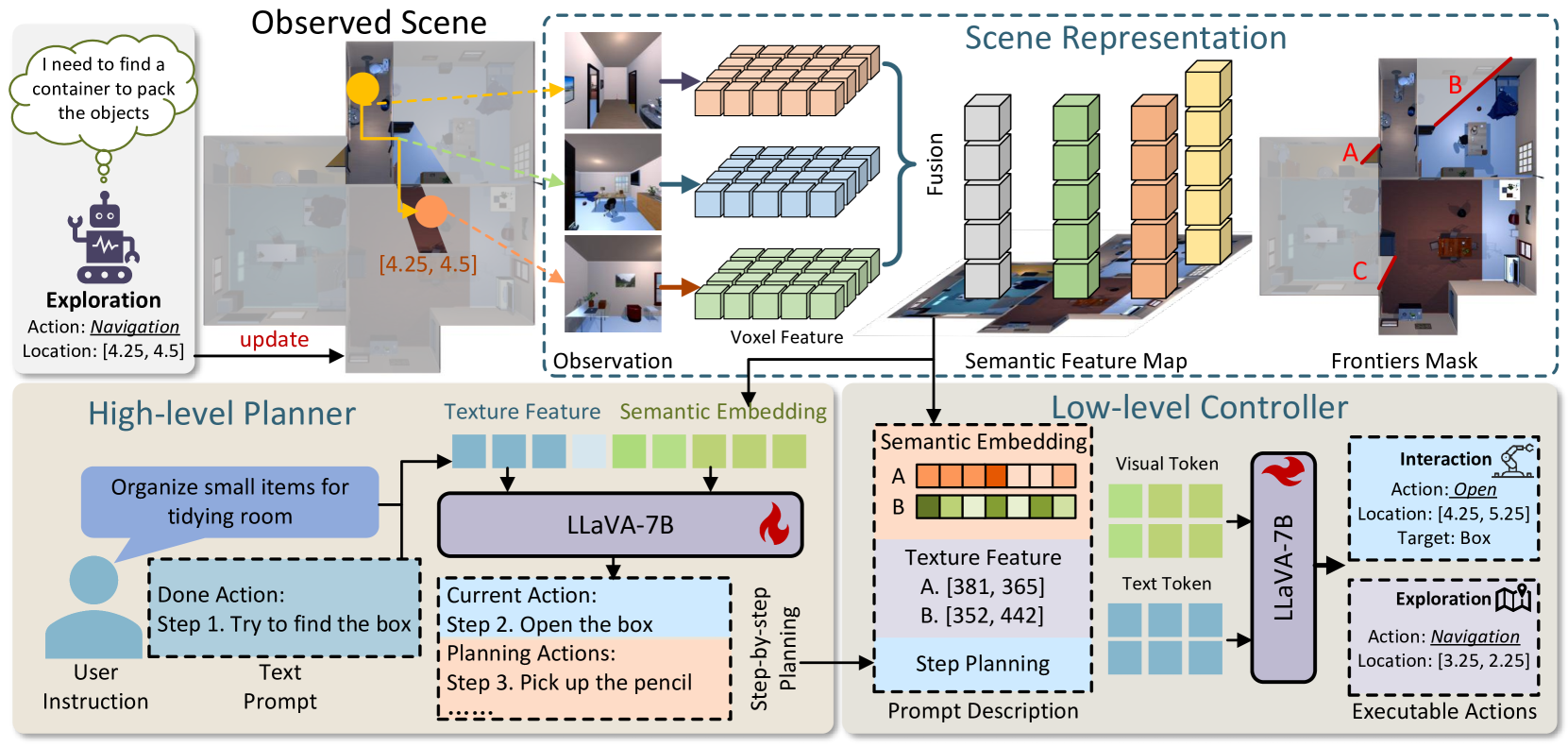
技术框架:该方法采用分层框架,包含两个主要模块:高级任务规划器和低级探索控制器。高级任务规划器利用MLLM根据用户指令和已知的环境信息生成逐步的任务计划。低级探索控制器根据任务计划和环境信息,预测智能体的导航或对象交互策略。同时,构建一个动态区域注意力的语义表示图,用于表示已知的视觉线索,并指导任务规划和场景探索。
关键创新:该方法最重要的创新点在于将多模态大语言模型应用于未知环境下的具身智能指令跟随任务,并结合动态区域注意力机制,实现了高效的环境探索和任务规划。与现有方法相比,该方法不需要预先提供环境信息,能够更好地适应真实世界的复杂场景。
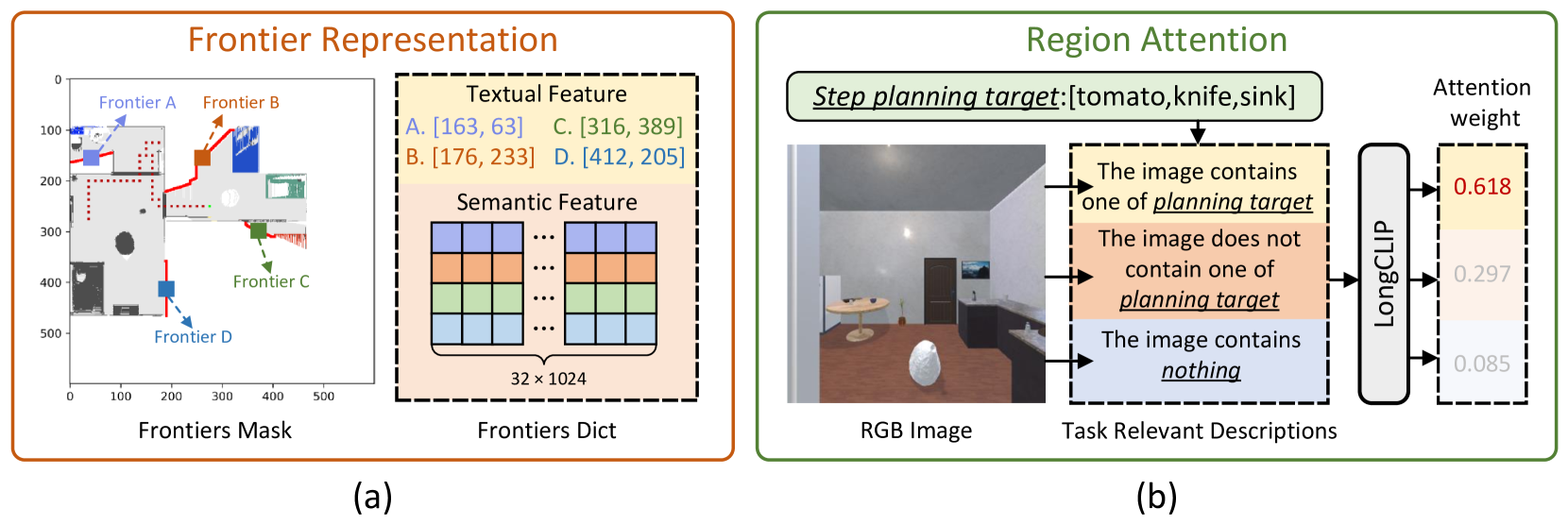
关键设计:动态区域注意力机制通过学习不同区域与任务的相关性,动态调整注意力权重,使智能体能够更加关注与任务相关的区域。任务规划器利用MLLM生成逐步的任务计划,并根据环境反馈进行调整。探索控制器采用强化学习方法,学习最优的导航或对象交互策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在大型住宅场景中,对于204个复杂的人工指令(如制作早餐和整理房间),成功率达到了45.09%。这一结果显著优于现有方法,验证了该方法在未知环境下执行复杂指令的有效性。该方法能够有效地探索未知环境,并生成可行的任务计划,从而提高任务完成的成功率。
🎯 应用场景
该研究成果可应用于家庭服务机器人、智能助手等领域,例如帮助用户完成家务、提供导航指引等。在未知或动态变化的环境中,该方法能够使机器人更好地理解用户指令,并自主完成任务,具有广阔的应用前景和实际价值。未来,可以进一步扩展到更复杂的任务和更广泛的应用场景。
📄 摘要(原文)
Enabling embodied agents to complete complex human instructions from natural language is crucial to autonomous systems in household services. Conventional methods can only accomplish human instructions in the known environment where all interactive objects are provided to the embodied agent, and directly deploying the existing approaches for the unknown environment usually generates infeasible plans that manipulate non-existing objects. On the contrary, we propose an embodied instruction following (EIF) method for complex tasks in the unknown environment, where the agent efficiently explores the unknown environment to generate feasible plans with existing objects to accomplish abstract instructions. Specifically, we build a hierarchical embodied instruction following framework including the high-level task planner and the low-level exploration controller with multimodal large language models. We then construct a semantic representation map of the scene with dynamic region attention to demonstrate the known visual clues, where the goal of task planning and scene exploration is aligned for human instruction. For the task planner, we generate the feasible step-by-step plans for human goal accomplishment according to the task completion process and the known visual clues. For the exploration controller, the optimal navigation or object interaction policy is predicted based on the generated step-wise plans and the known visual clues. The experimental results demonstrate that our method can achieve 45.09% success rate in 204 complex human instructions such as making breakfast and tidying rooms in large house-level scenes. Code and supplementary are available at https://gary3410.github.io/eif_unknown.