Deep Reinforcement Learning-based Quadcopter Controller: A Practical Approach and Experiments
作者: Truong-Dong Do, Nguyen Xuan Mung, Sung Kyung Hong
分类: cs.RO, eess.SY
发布日期: 2024-06-13 (更新: 2024-06-18)
备注: 6 pages, 5 figures, 3 tables
💡 一句话要点
提出基于深度强化学习的四旋翼控制器,实现安全、高效和免人工调参的实际应用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 四旋翼控制 无人机 Actor-Critic 仿真到现实
📋 核心要点
- 四旋翼飞行器面临动态非线性、执行器饱和以及传感器噪声等挑战,导致精确动态建模和控制性能提升困难。
- 论文提出一种端到端的深度强化学习控制器,直接将机器人状态映射到电机输出,无需人工干预,提升控制性能。
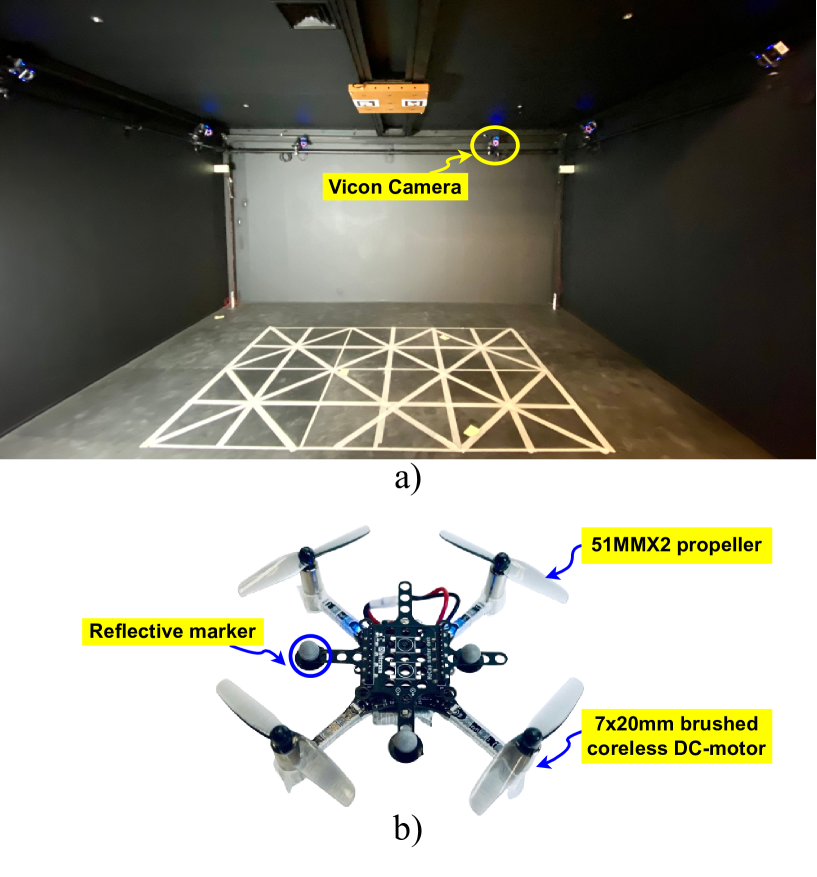
- 通过仿真训练的策略直接部署在真实四旋翼平台上,无需微调,实验结果验证了该方法在复杂轨迹跟踪中的有效性。
📝 摘要(中文)
本文提出了一种基于深度强化学习的端到端四旋翼控制器,该控制器安全可靠,适用于实际部署,具有数据高效性,且无需人工调整增益。首先,设计了一种新颖的基于Actor-Critic的架构,将机器人状态直接映射到电机输出。然后,设计了一个基于四旋翼动力学的仿真器,以促进控制器策略的训练。最后,将训练好的策略部署在真实的Crazyflie纳米四旋翼平台上,无需任何额外的微调过程。实验结果表明,该四旋翼在跟踪给定的复杂轨迹时表现出令人满意的性能,证明了该方法的有效性和可行性,并表明其有能力填补仿真到现实的差距。
🔬 方法详解
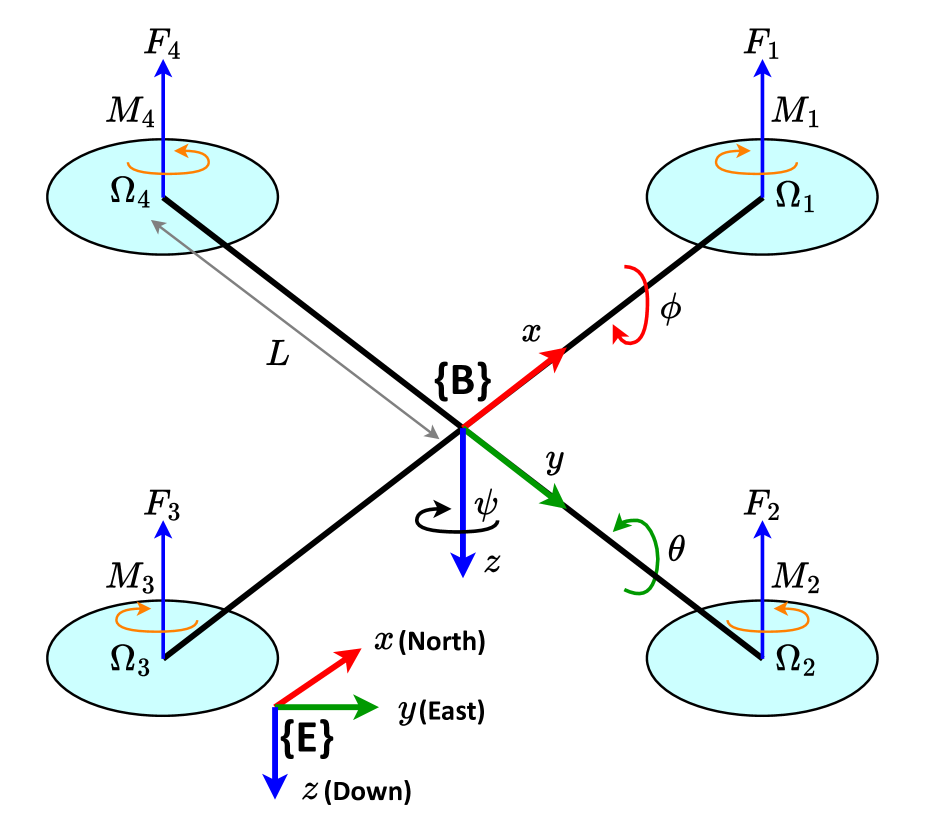
问题定义:四旋翼飞行器由于其非线性动力学、执行器饱和以及传感器噪声等问题,难以建立精确的动力学模型,从而导致难以获得令人满意的控制性能。传统控制方法需要耗费大量时间进行参数调整,且难以适应复杂环境。
核心思路:本文的核心思路是利用深度强化学习(DRL)直接学习四旋翼的控制策略,避免了传统方法中复杂的建模和参数调整过程。通过设计合适的奖励函数和网络结构,使智能体能够自主学习最优控制策略,从而实现对四旋翼的精确控制。
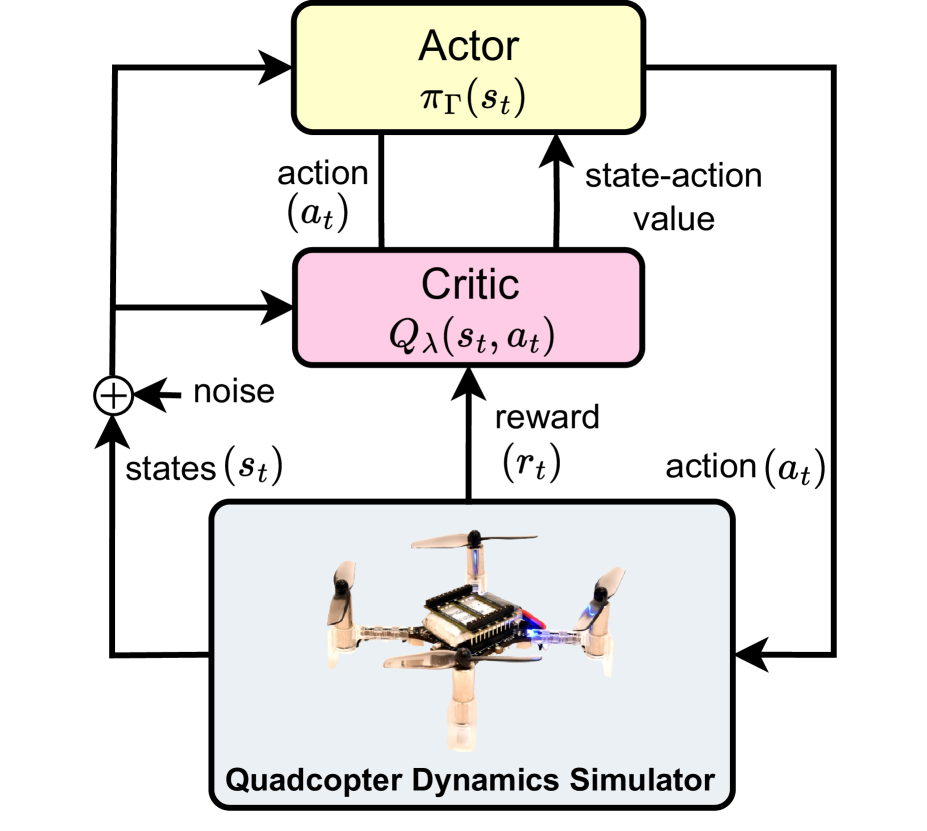
技术框架:整体框架包括三个主要部分:首先是基于Actor-Critic的深度强化学习算法,用于学习控制策略;其次是四旋翼动力学仿真器,用于提供训练数据;最后是将训练好的策略部署到真实的四旋翼飞行器上。Actor网络负责输出控制动作,Critic网络负责评估当前状态的价值。仿真器基于四旋翼的动力学模型,可以生成大量的训练数据。
关键创新:该方法的主要创新在于提出了一种端到端的深度强化学习控制方案,能够直接将机器人状态映射到电机输出,无需人工干预。此外,该方法具有较强的数据效率,能够在较短的时间内学习到有效的控制策略。最重要的是,训练好的策略可以直接部署到真实四旋翼平台上,无需额外的微调,从而有效解决了仿真到现实的迁移问题。
关键设计:Actor网络和Critic网络均采用深度神经网络结构。Actor网络输入为四旋翼的状态信息(如位置、速度、姿态等),输出为四个电机的控制信号。Critic网络输入为四旋翼的状态信息和Actor网络输出的控制信号,输出为当前状态的价值。奖励函数的设计至关重要,需要综合考虑位置误差、速度误差、姿态误差以及控制信号的平滑性等因素。训练过程中,采用合适的优化算法(如Adam)来更新网络参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的基于深度强化学习的四旋翼控制器能够在真实Crazyflie纳米四旋翼平台上实现令人满意的轨迹跟踪性能,无需任何额外的微调过程。该方法成功地填补了仿真到现实的差距,验证了其有效性和可行性。虽然论文中没有给出具体的性能数据和对比基线,但强调了在真实环境中的成功部署。
🎯 应用场景
该研究成果可应用于无人机自主导航、物流配送、环境监测、灾害救援等领域。通过深度强化学习,无人机能够更好地适应复杂环境,提高飞行稳定性和控制精度,降低对人工干预的依赖。未来,该技术有望推动无人机在更多领域的应用,并促进相关产业的发展。
📄 摘要(原文)
Quadcopters have been studied for decades thanks to their maneuverability and capability of operating in a variety of circumstances. However, quadcopters suffer from dynamical nonlinearity, actuator saturation, as well as sensor noise that make it challenging and time consuming to obtain accurate dynamic models and achieve satisfactory control performance. Fortunately, deep reinforcement learning came and has shown significant potential in system modelling and control of autonomous multirotor aerial vehicles, with recent advancements in deployment, performance enhancement, and generalization. In this paper, an end-to-end deep reinforcement learning-based controller for quadcopters is proposed that is secure for real-world implementation, data-efficient, and free of human gain adjustments. First, a novel actor-critic-based architecture is designed to map the robot states directly to the motor outputs. Then, a quadcopter dynamics-based simulator was devised to facilitate the training of the controller policy. Finally, the trained policy is deployed on a real Crazyflie nano quadrotor platform, without any additional fine-tuning process. Experimental results show that the quadcopter exhibits satisfactory performance as it tracks a given complicated trajectory, which demonstrates the effectiveness and feasibility of the proposed method and signifies its capability in filling the simulation-to-reality gap.