RVT-2: Learning Precise Manipulation from Few Demonstrations
作者: Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, Dieter Fox
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-06-12
备注: Accepted to RSS 2024
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RVT-2:从少量演示中学习精确操作,提升机器人操作精度与效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 3D操作 少量演示学习 Transformer 高精度操作
📋 核心要点
- 现有机器人操作模型在处理需要高精度的3D操作任务时存在困难,限制了其在工业和家庭领域的应用。
- RVT-2通过架构和系统层面的改进,旨在提升机器人操作的效率和精度,使其能够从少量演示中学习新任务。
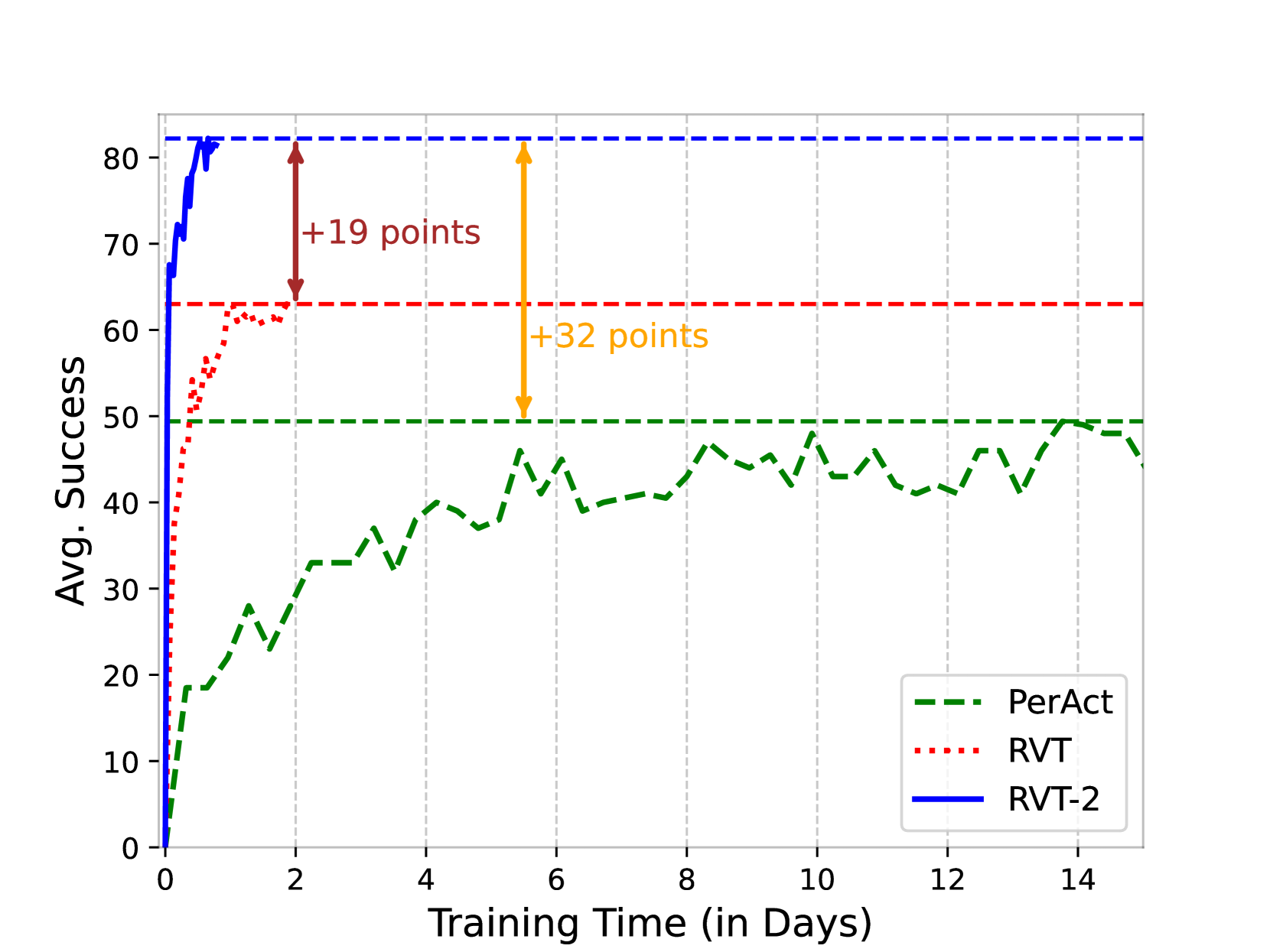
- RVT-2在RLBench上取得了显著的性能提升,成功率达到82%,并且在真实世界任务中仅需少量演示即可完成高精度操作。
📝 摘要(中文)
本文研究如何构建一个能够根据语言指令解决多个3D操作任务的机器人系统。为了在工业和家庭领域发挥作用,该系统应该能够通过少量演示学习新任务并精确地解决它们。先前的工作,如PerAct和RVT,已经研究过这个问题,但是它们通常难以处理需要高精度的任务。本文研究如何使它们更有效、更精确和更快。通过架构和系统层面的改进,我们提出了RVT-2,一个多任务3D操作模型,其训练速度比其前身RVT快6倍,推理速度快2倍。RVT-2在RLBench上实现了新的state-of-the-art,将成功率从65%提高到82%。RVT-2在现实世界中也很有效,只需10次演示即可学习需要高精度的任务,例如拾取和插入插头。视觉结果、代码和训练好的模型可在https://robotic-view-transformer-2.github.io/上找到。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务中,现有方法在高精度要求下的性能瓶颈问题。具体来说,现有方法如PerAct和RVT在处理需要精确操作的任务时,成功率较低,且训练和推理速度较慢,难以满足实际应用需求。
核心思路:RVT-2的核心思路是通过架构和系统层面的优化,提升模型的表达能力和学习效率,从而实现从少量演示中学习高精度操作。这种优化旨在提高模型对细微动作的感知和控制能力,使其能够更准确地完成任务。
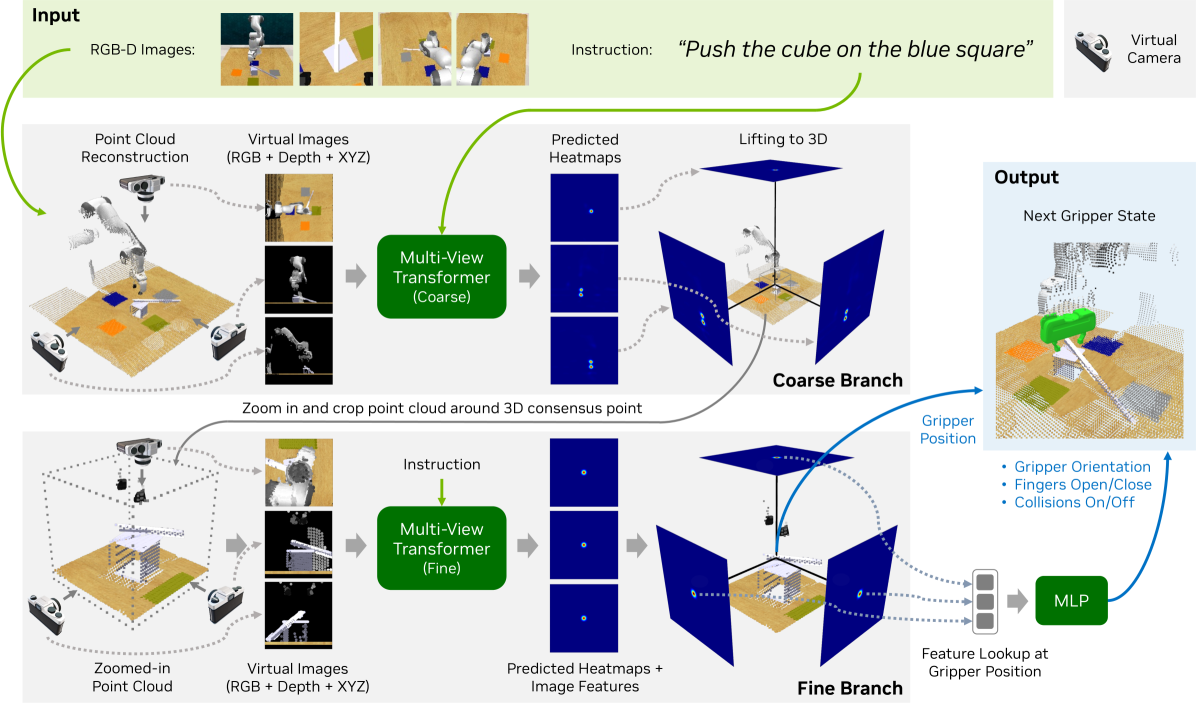
技术框架:RVT-2是一个多任务3D操作模型,其整体架构基于Transformer。具体流程包括:首先,模型接收语言指令和视觉输入(例如,RGB图像或深度图像);然后,通过Transformer编码器提取特征;接着,利用解码器生成动作序列,控制机器人执行操作。模型采用端到端的方式进行训练,直接从演示数据中学习。
关键创新:RVT-2的关键创新在于其架构和系统层面的改进,这些改进使得模型在训练和推理速度上都得到了显著提升,同时提高了操作精度。具体的创新点可能包括:更有效的注意力机制、优化的网络结构、以及更高效的训练策略。
关键设计:论文中可能涉及的关键设计包括:注意力机制的具体实现方式(例如,稀疏注意力或局部注意力),损失函数的设计(例如,动作预测损失、状态预测损失),以及训练数据的增强策略。此外,网络结构的细节,如Transformer层数、隐藏层维度等,也可能对性能产生重要影响。具体的参数设置和超参数选择需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
RVT-2在RLBench基准测试中取得了显著的性能提升,成功率从65%提高到82%,达到了新的state-of-the-art。此外,RVT-2的训练速度比其前身RVT快6倍,推理速度快2倍。在真实世界任务中,RVT-2仅需10次演示即可学习需要高精度的任务,例如拾取和插入插头,展示了其强大的泛化能力和实用性。
🎯 应用场景
RVT-2具有广泛的应用前景,包括工业自动化、家庭服务机器人、医疗机器人等领域。它可以用于执行各种需要高精度操作的任务,例如装配、抓取、放置、插入等。通过少量演示学习新任务的能力,使得RVT-2能够快速适应不同的应用场景,降低部署成本,提高生产效率。
📄 摘要(原文)
In this work, we study how to build a robotic system that can solve multiple 3D manipulation tasks given language instructions. To be useful in industrial and household domains, such a system should be capable of learning new tasks with few demonstrations and solving them precisely. Prior works, like PerAct and RVT, have studied this problem, however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench, improving the success rate from 65% to 82%. RVT-2 is also effective in the real world, where it can learn tasks requiring high precision, like picking up and inserting plugs, with just 10 demonstrations. Visual results, code, and trained model are provided at: https://robotic-view-transformer-2.github.io/.