Hierarchical Reinforcement Learning for Swarm Confrontation with High Uncertainty
作者: Qizhen Wu, Kexin Liu, Lei Chen, Jinhu Lü
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-06-12 (更新: 2024-10-25)
💡 一句话要点
提出一种分层强化学习方法,解决高不确定性下集群对抗问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 集群机器人 对抗博弈 不确定性量化 多智能体系统
📋 核心要点
- 现有端到端深度强化学习方法难以处理集群对抗中由未知策略和动态环境带来的混合决策过程。
- 提出一种分层强化学习框架,将混合决策过程分解为离散目标分配和连续路径规划,并量化不确定性。
- 设计集成训练方法,包含预训练和交叉训练,提升训练效率和稳定性,实验表明胜率达到90%左右。
📝 摘要(中文)
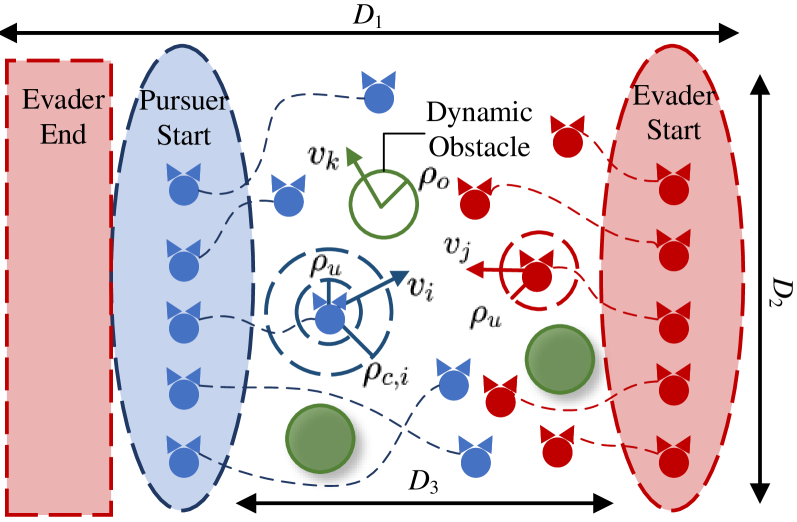
在集群机器人领域,对抗(包括追逐-逃避游戏)是一个关键场景。未知对手策略、动态障碍物和训练不足导致的高不确定性,使得动作空间复杂化为混合决策过程。尽管深度强化学习方法在集群对抗中具有重要意义,因为它能够处理各种规模,但作为一种端到端实现,它无法处理混合过程。本文提出了一种新的分层强化学习方法,包括目标分配层、路径规划层以及两层之间的动态交互机制,该机制指示量化的不确定性。它将混合过程解耦为离散分配和连续规划层,并使用概率集成模型来量化不确定性并自适应地调节交互频率。此外,为了克服两层引入的不稳定训练过程,我们设计了一种包括预训练和交叉训练的集成训练方法,从而提高了训练效率和稳定性。比较、消融和真实机器人研究的实验结果验证了我们提出的方法的有效性和泛化性能。在我们定义的包含20到40个智能体的实验中,所提出方法的胜率达到90%左右,优于其他传统方法。
🔬 方法详解
问题定义:论文旨在解决高不确定性环境下,集群机器人对抗场景中的混合决策问题。现有端到端深度强化学习方法难以有效处理由于对手策略未知、环境动态变化以及训练数据不足所带来的复杂动作空间,导致决策效率和对抗性能下降。
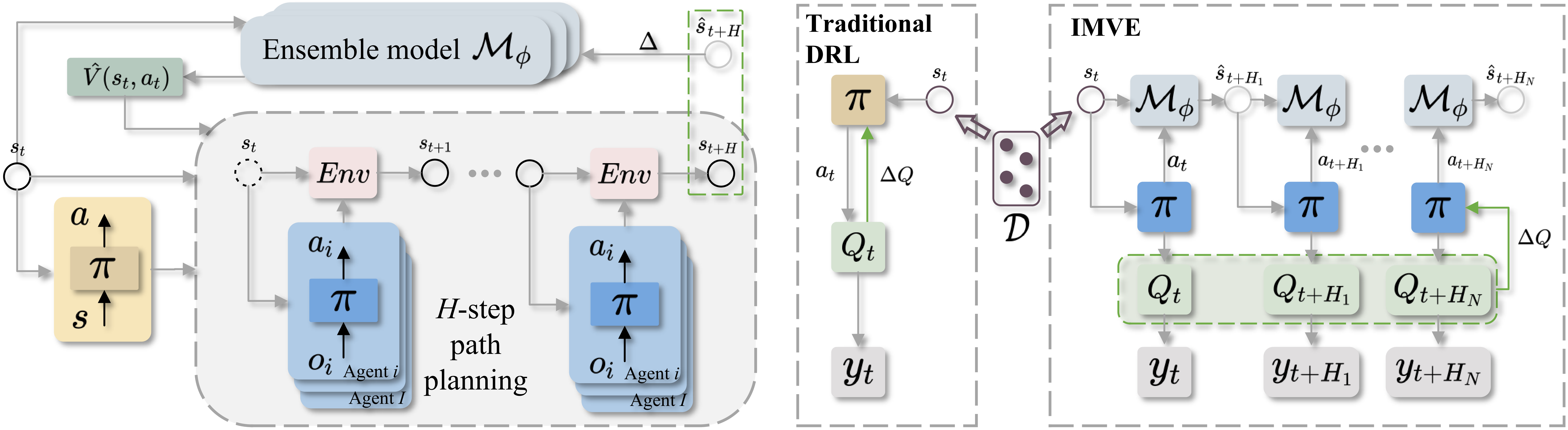
核心思路:论文的核心思路是将复杂的混合决策过程解耦为两个层次:离散的目标分配层和连续的路径规划层。通过分层结构,降低了决策的复杂性,使得每个层次可以专注于解决特定类型的问题。同时,引入概率集成模型来量化不确定性,并根据不确定性自适应地调节两个层次之间的交互频率。
技术框架:整体框架包含三个主要模块:目标分配层、路径规划层和动态交互机制。目标分配层负责为每个智能体分配目标,这是一个离散决策过程。路径规划层负责规划智能体到达目标的具体路径,这是一个连续决策过程。动态交互机制则负责在两个层次之间传递信息,并根据不确定性调整交互频率。
关键创新:论文的关键创新在于分层强化学习框架和概率集成模型。分层框架将复杂的决策问题分解为更易于处理的子问题,概率集成模型则能够有效地量化环境的不确定性,并指导智能体的决策。此外,集成的训练方法也提高了训练的效率和稳定性。
关键设计:目标分配层和路径规划层分别使用不同的强化学习算法进行训练。概率集成模型可能采用例如贝叶斯神经网络或高斯过程等方法来估计不确定性。动态交互机制可能基于不确定性阈值或信息增益等指标来调整交互频率。损失函数的设计需要考虑两个层次之间的协调,以及不确定性对决策的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在包含20到40个智能体的对抗环境中,所提出的分层强化学习方法胜率达到90%左右,显著优于其他传统方法。消融实验验证了目标分配层、路径规划层和动态交互机制的有效性。真实机器人实验进一步验证了该方法在实际环境中的泛化性能。
🎯 应用场景
该研究成果可应用于无人机集群对抗、机器人足球、多智能体搜索与救援等领域。通过分层决策和不确定性量化,可以提高集群机器人在复杂动态环境中的适应性和协同能力,具有重要的实际应用价值和潜在的军事应用价值。未来可进一步探索在更复杂环境和更大规模集群中的应用。
📄 摘要(原文)
In swarm robotics, confrontation including the pursuit-evasion game is a key scenario. High uncertainty caused by unknown opponents' strategies, dynamic obstacles, and insufficient training complicates the action space into a hybrid decision process. Although the deep reinforcement learning method is significant for swarm confrontation since it can handle various sizes, as an end-to-end implementation, it cannot deal with the hybrid process. Here, we propose a novel hierarchical reinforcement learning approach consisting of a target allocation layer, a path planning layer, and the underlying dynamic interaction mechanism between the two layers, which indicates the quantified uncertainty. It decouples the hybrid process into discrete allocation and continuous planning layers, with a probabilistic ensemble model to quantify the uncertainty and regulate the interaction frequency adaptively. Furthermore, to overcome the unstable training process introduced by the two layers, we design an integration training method including pre-training and cross-training, which enhances the training efficiency and stability. Experiment results in both comparison, ablation, and real-robot studies validate the effectiveness and generalization performance of our proposed approach. In our defined experiments with twenty to forty agents, the win rate of the proposed method reaches around ninety percent, outperforming other traditional methods.