Scaling Manipulation Learning with Visual Kinematic Chain Prediction
作者: Xinyu Zhang, Yuhan Liu, Haonan Chang, Abdeslam Boularias
分类: cs.RO, cs.AI
发布日期: 2024-06-12 (更新: 2024-10-14)
备注: CoRL 2024
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于视觉运动链预测的VKT模型,扩展机器人操作学习至多样化环境
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人学习 视觉运动链 Transformer 多任务学习 通用机器人 运动学预测 机器人操作
📋 核心要点
- 现有机器人多任务学习方法受限于单一机器人和工作空间,难以泛化到多样化环境。
- 提出视觉运动链作为动作的通用表示,并设计视觉运动学Transformer (VKT) 进行运动学结构预测。
- 实验证明VKT在多个机器人操作数据集和真实机器人任务上,性能优于现有方法。
📝 摘要(中文)
本文提出了一种基于视觉运动链的机器人学习方法,旨在解决多任务学习中现有方法受限于单一机器人和工作空间的问题。现有方法如RT-X需要手动进行动作归一化,以弥合不同环境中动作空间之间的差距。本文提出的视觉运动链是一种精确且通用的准静态动作表示,适用于多样化环境下的机器人学习,无需手动调整,因为视觉运动链可以从机器人的模型和相机参数中自动获得。本文提出了视觉运动学Transformer(VKT),一种无卷积架构,支持任意数量的相机视角,并通过最优点集匹配训练,以预测运动学结构。实验表明,VKT作为通用代理在Calvin、RLBench、Open-X和真实机器人操作任务上优于BC Transformer。
🔬 方法详解
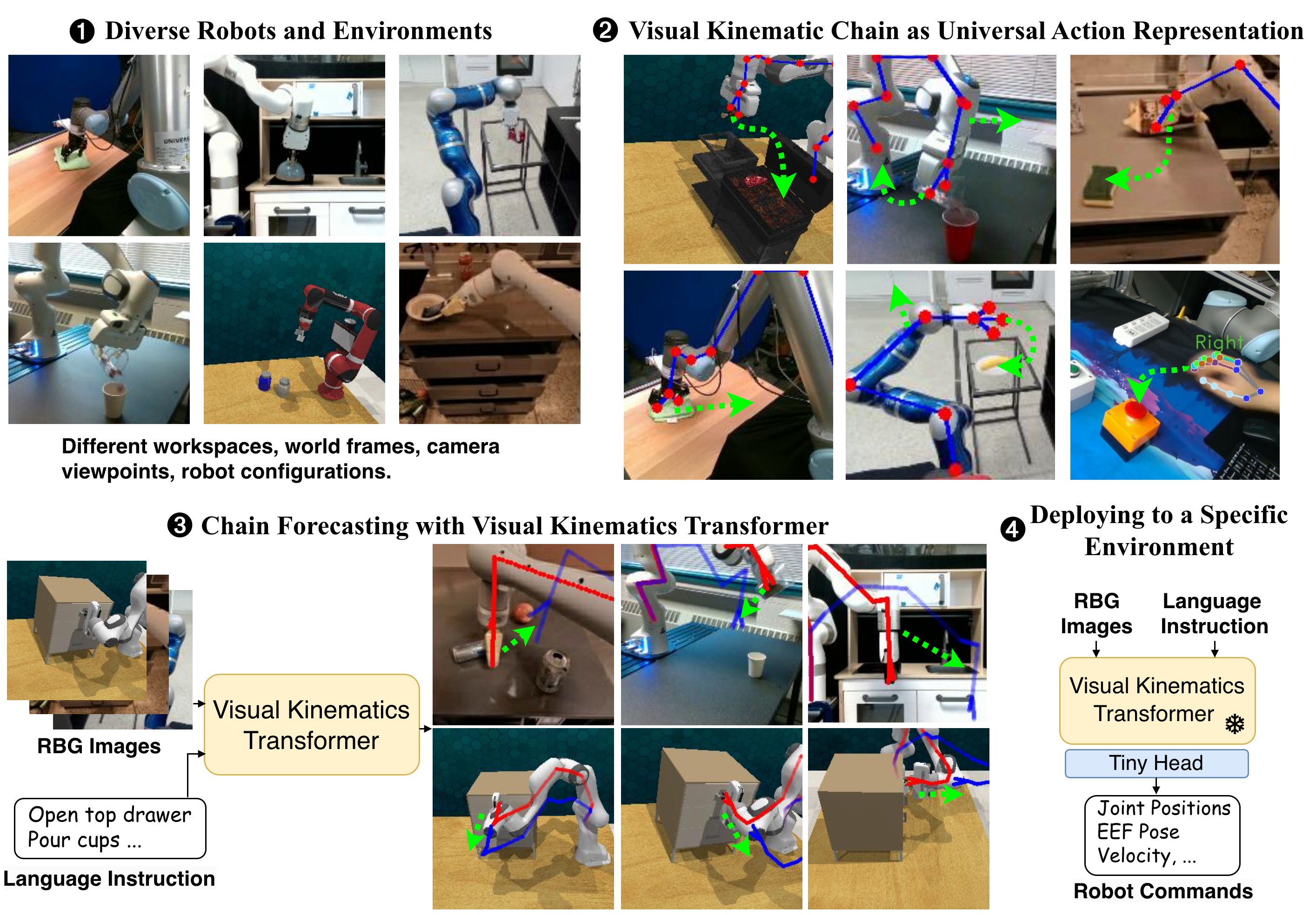
问题定义:现有机器人学习方法,尤其是在多任务学习中,通常受限于单一机器人和工作空间。即使像RT-X这样的方法,也需要手动进行动作归一化,以解决不同环境和机器人之间动作空间差异的问题。这限制了模型在多样化环境下的泛化能力,增加了部署的复杂性。
核心思路:本文的核心思路是利用视觉运动链作为机器人动作的通用表示。视觉运动链能够精确描述机器人的准静态动作,并且可以从机器人模型和相机参数中自动获得,无需手动调整。通过预测视觉运动链,模型可以学习到与具体机器人和环境无关的通用操作策略。
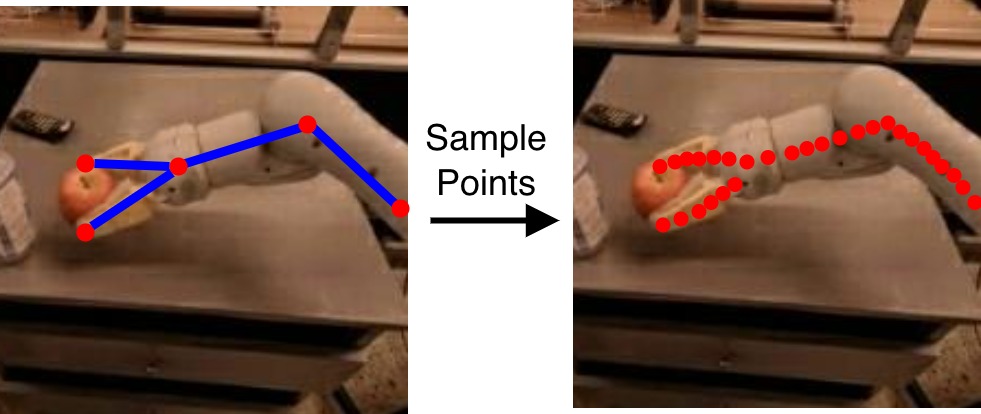
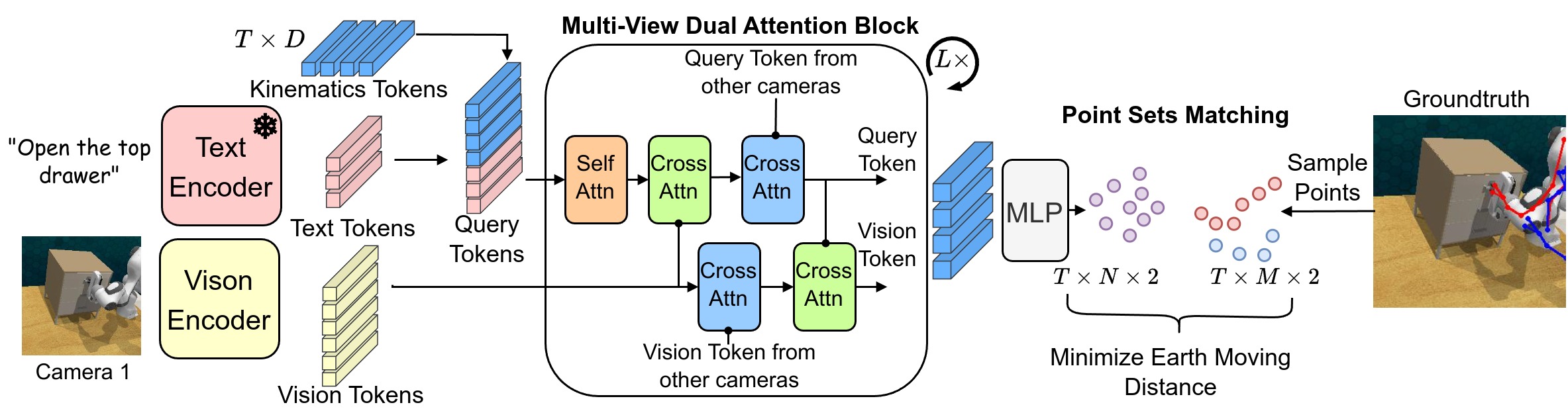
技术框架:论文提出了Visual Kinematics Transformer (VKT) 模型。VKT是一个无卷积的Transformer架构,它可以处理来自任意数量相机视角的输入。模型的训练目标是预测运动学结构,具体来说,是通过最优点集匹配的方式,预测下一时刻的视觉运动链。整个框架包括视觉特征提取模块、Transformer编码器和运动学结构预测模块。
关键创新:最重要的创新点在于使用视觉运动链作为机器人动作的通用表示。与直接预测动作空间不同,视觉运动链提供了一种与机器人和环境无关的中间表示,从而实现了跨机器人和环境的泛化。此外,VKT的无卷积架构使其能够灵活地处理来自不同数量和位置的相机输入。
关键设计:VKT的关键设计包括:1) 无卷积的Transformer架构,避免了卷积操作对图像尺寸的限制;2) 使用最优点集匹配(Optimal Point-set Matching)作为损失函数,鼓励模型准确预测运动学结构;3) 支持任意数量的相机视角,提高了模型的鲁棒性和适应性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VKT在Calvin、RLBench、Open-X和真实机器人操作任务上均优于BC Transformer。例如,在Calvin数据集上,VKT的成功率显著高于BC Transformer,并且在真实机器人实验中也表现出更好的泛化能力。这些结果验证了视觉运动链作为通用动作表示的有效性,以及VKT模型的优越性。
🎯 应用场景
该研究成果可应用于工业自动化、家庭服务机器人、医疗机器人等领域。通过学习通用的操作策略,机器人可以更灵活地适应不同的任务和环境,降低部署成本,提高工作效率。未来,该方法有望扩展到更复杂的动态操作任务中。
📄 摘要(原文)
Learning general-purpose models from diverse datasets has achieved great success in machine learning. In robotics, however, existing methods in multi-task learning are typically constrained to a single robot and workspace, while recent work such as RT-X requires a non-trivial action normalization procedure to manually bridge the gap between different action spaces in diverse environments. In this paper, we propose the visual kinematics chain as a precise and universal representation of quasi-static actions for robot learning over diverse environments, which requires no manual adjustment since the visual kinematic chains can be automatically obtained from the robot's model and camera parameters. We propose the Visual Kinematics Transformer (VKT), a convolution-free architecture that supports an arbitrary number of camera viewpoints, and that is trained with a single objective of forecasting kinematic structures through optimal point-set matching. We demonstrate the superior performance of VKT over BC transformers as a general agent on Calvin, RLBench, Open-X, and real robot manipulation tasks. Video demonstrations can be found at https://mlzxy.github.io/visual-kinetic-chain.