Visual-Inertial SLAM as Simple as A, B, VINS
作者: Nathaniel Merrill, Guoquan Huang
分类: cs.RO
发布日期: 2024-06-10 (更新: 2024-09-22)
备注: Submitted to T-RO
💡 一句话要点
AB-VINS:一种利用深度学习简化视觉惯性SLAM的方案
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉惯性SLAM 深度学习 单目深度估计 回环检测 记忆树 机器人导航 稠密深度
📋 核心要点
- 传统VINS方法依赖手工特征,计算复杂度高,难以兼顾效率与稠密深度。
- AB-VINS利用深度学习估计单目深度图的尺度和偏差,压缩特征状态,提升前端效率。
- 通过记忆树结构,AB-VINS在回环检测中仅需调整少量变量,提高了鲁棒性。
📝 摘要(中文)
本文提出了一种新型的视觉惯性SLAM系统AB-VINS。与大多数流行的VINS方法仅使用手工设计的技术不同,AB-VINS利用了三个不同的深度神经网络。AB-VINS不估计稀疏特征点的位置,而是仅估计单目深度图的尺度和偏差参数(a和b),以及使用多视图信息校正深度的其他项,从而实现压缩的特征状态。尽管AB-VINS是一个基于优化的系统,但其前端运动跟踪线程的效率超过了最先进的基于滤波的方法,同时还提供了稠密深度。在执行回环检测时,标准的基于关键帧的SLAM系统需要重新线性化大量变量,其数量与关键帧的数量成线性关系。相比之下,所提出的AB-VINS可以在仅影响常量数量的变量的情况下合并回环检测。这归功于一种名为记忆树的新型数据结构,其中关键帧姿态是相对于彼此定义的,而不是全部在一个全局坐标系中,从而允许固定除少数状态之外的所有状态。虽然AB-VINS可能不如最先进的VINS算法准确,但它被证明更具鲁棒性。
🔬 方法详解
问题定义:现有VINS系统通常依赖手工设计的特征提取和匹配方法,计算量大,难以实现高效的稠密深度估计。同时,在回环检测中,需要重新线性化大量变量,导致计算复杂度随关键帧数量线性增长,影响系统的实时性和鲁棒性。
核心思路:AB-VINS的核心思路是利用深度学习来简化视觉惯性SLAM流程。通过神经网络直接估计单目深度图的尺度和偏差参数,从而避免了传统特征提取和匹配的复杂计算。此外,引入记忆树数据结构,将关键帧姿态定义为相对关系,从而在回环检测中仅需调整少量变量。
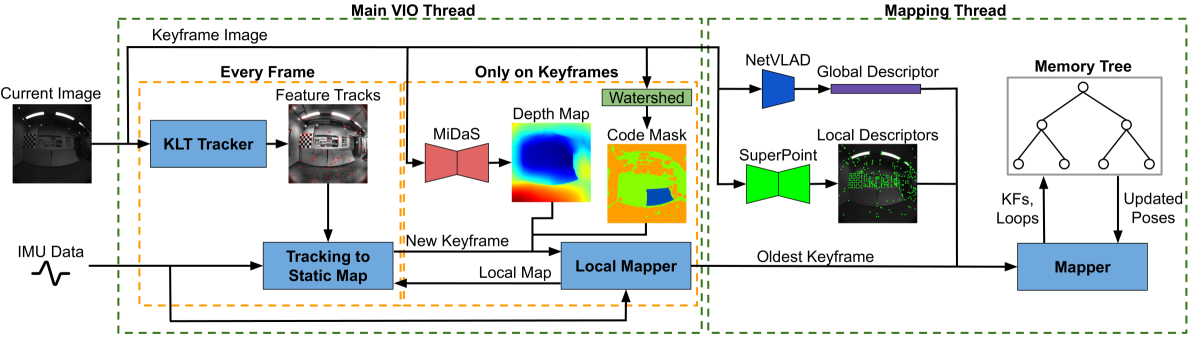
技术框架:AB-VINS系统主要包含三个部分:基于深度学习的前端运动跟踪、后端优化和基于记忆树的回环检测。前端使用三个深度神经网络来估计深度图的尺度和偏差参数,并利用多视图信息进行深度校正。后端采用优化方法,融合视觉和惯性信息,优化位姿和地图。回环检测模块使用记忆树结构,实现高效的回环约束。
关键创新:AB-VINS的关键创新在于以下两点:一是利用深度学习直接估计深度图参数,简化了前端处理流程,提高了效率;二是引入记忆树数据结构,实现了常量时间复杂度的回环检测,提高了系统的鲁棒性。
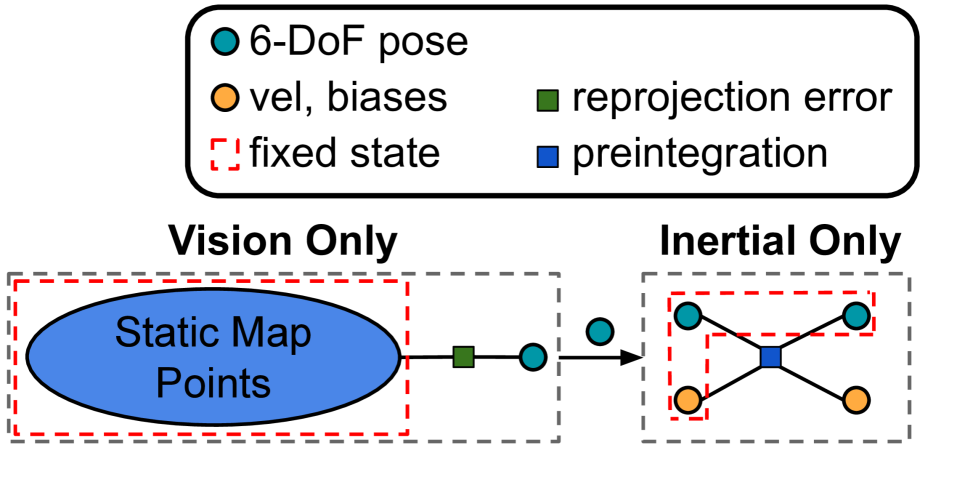
关键设计:AB-VINS使用三个深度神经网络:一个用于估计深度图的尺度参数a,一个用于估计偏差参数b,还有一个用于深度校正。记忆树是一种树状数据结构,其中每个节点代表一个关键帧,节点之间的边表示关键帧之间的相对位姿关系。在回环检测时,只需要调整回环路径上的节点位姿,而其他节点的位姿保持不变。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AB-VINS的前端运动跟踪效率超过了最先进的基于滤波的方法,同时提供了稠密深度。在回环检测中,AB-VINS仅需调整常量数量的变量,而传统的基于关键帧的SLAM系统需要调整线性数量的变量。虽然AB-VINS的精度可能略低于最先进的VINS算法,但其鲁棒性更强。
🎯 应用场景
AB-VINS具有广泛的应用前景,例如增强现实、虚拟现实、机器人导航、无人机自主飞行等。其高效的稠密深度估计能力使其能够应用于需要精确环境感知的场景。此外,其鲁棒的回环检测机制使其能够适应复杂的环境变化。
📄 摘要(原文)
We present AB-VINS, a different kind of visual-inertial SLAM system. Unlike most popular VINS methods which only use hand-crafted techniques, AB-VINS makes use of three different deep neural networks. Instead of estimating sparse feature positions, AB-VINS only estimates the scale and bias parameters (a and b) of monocular depth maps, as well as other terms to correct the depth using multi-view information, which results in a compressed feature state. Despite being an optimization-based system, the front-end motion tracking thread of AB-VINS surpasses the efficiency of a state-of-the-art filtering-based method while also providing dense depth. When performing loop closures, standard keyframe-based SLAM systems need to relinearize a number of variables which is linear with respect to the number of keyframes. In contrast, the proposed AB-VINS can incorporate loop closures while only affecting a constant number of variables. This is thanks to a novel data structure called the memory tree, where keyframe poses are defined relative to each other rather than all in one global frame, allowing for all but a few states to be fixed. While AB-VINS might not be as accurate as state-of-the-art VINS algorithms, it is shown to be more robust.