I2EDL: Interactive Instruction Error Detection and Localization
作者: Francesco Taioli, Stefano Rosa, Alberto Castellini, Lorenzo Natale, Alessio Del Bue, Alessandro Farinelli, Marco Cristani, Yiming Wang
分类: cs.RO, cs.AI, cs.CL
发布日期: 2024-06-07 (更新: 2024-06-23)
备注: Accepted at IEEE RO-MAN 2024
期刊: 33rd IEEE International Conference on Robot and Human Interactive Communication (ROMAN), 2024
DOI: 10.1109/RO-MAN60168.2024.10731349
💡 一句话要点
提出I2EDL,解决交互式VLN-CE任务中指令错误检测与定位问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 指令错误检测 人机交互 交互式学习 机器人导航
📋 核心要点
- 现有VLN-CE方法忽略了用户可能在指令中犯错的情况,导致导航失败。
- I2EDL通过检测和定位指令错误,使智能体能够与用户交互以获得更正,从而提高导航成功率。
- 实验证明,I2EDL能有效定位错误并减少交互次数,显著提升了导航性能。
📝 摘要(中文)
本文针对连续环境下的视觉-语言导航(VLN-CE)任务,提出了一种新的交互式VLN-CE(IVLN-CE)任务,该任务允许智能体在导航过程中与用户交互,以验证指令错误。为此,我们提出了一个交互式指令错误检测器和定位器(I2EDL),它在导航过程中检测到指令错误时触发用户-智能体交互。I2EDL利用预训练模块检测指令错误,并通过交叉引用文本输入和过去的观察来精确定位指令中的错误。通过这种方式,智能体能够及时向用户请求更正,而不会增加用户的认知负担,因为我们将可能的错误定位到指令的精确部分。我们在包含错误的指令数据集上评估了所提出的I2EDL,并进一步设计了一种新的指标,即交互次数加权成功率(SIN),以反映导航性能和交互有效性。实验表明,该方法可以向用户提出有针对性的更正请求,从而提高导航成功率,同时最大限度地减少交互次数。
🔬 方法详解
问题定义:现有的视觉-语言导航(VLN)方法通常假设用户提供的指令是完全正确的。然而,在实际应用中,用户可能会犯错,例如给出错误的转向指令。这些错误会导致导航失败。因此,该论文旨在解决在连续环境下的交互式视觉-语言导航(IVLN-CE)任务中,如何检测和定位用户指令中的错误,并与用户交互以获得更正的问题。
核心思路:该论文的核心思路是构建一个能够检测指令错误并精确定位错误位置的模块,即交互式指令错误检测器和定位器(I2EDL)。当I2EDL检测到指令可能存在错误时,它会主动与用户交互,请求用户对指令进行更正。通过这种交互,智能体可以避免因错误的指令而导致的导航失败。
技术框架:I2EDL的整体框架包含以下几个主要模块:1) 预训练的指令错误检测模块:用于检测当前指令是否可能包含错误。2) 指令错误定位模块:用于精确定位指令中可能存在错误的部分。该模块通过交叉引用文本输入和过去的观察来实现。3) 交互模块:当检测到指令错误时,该模块负责与用户进行交互,请求用户对指令进行更正。整个流程是,智能体在导航过程中不断接收用户的指令,I2EDL实时检测指令错误,如果检测到错误,则定位错误位置并向用户请求更正,用户更正后,智能体继续导航。
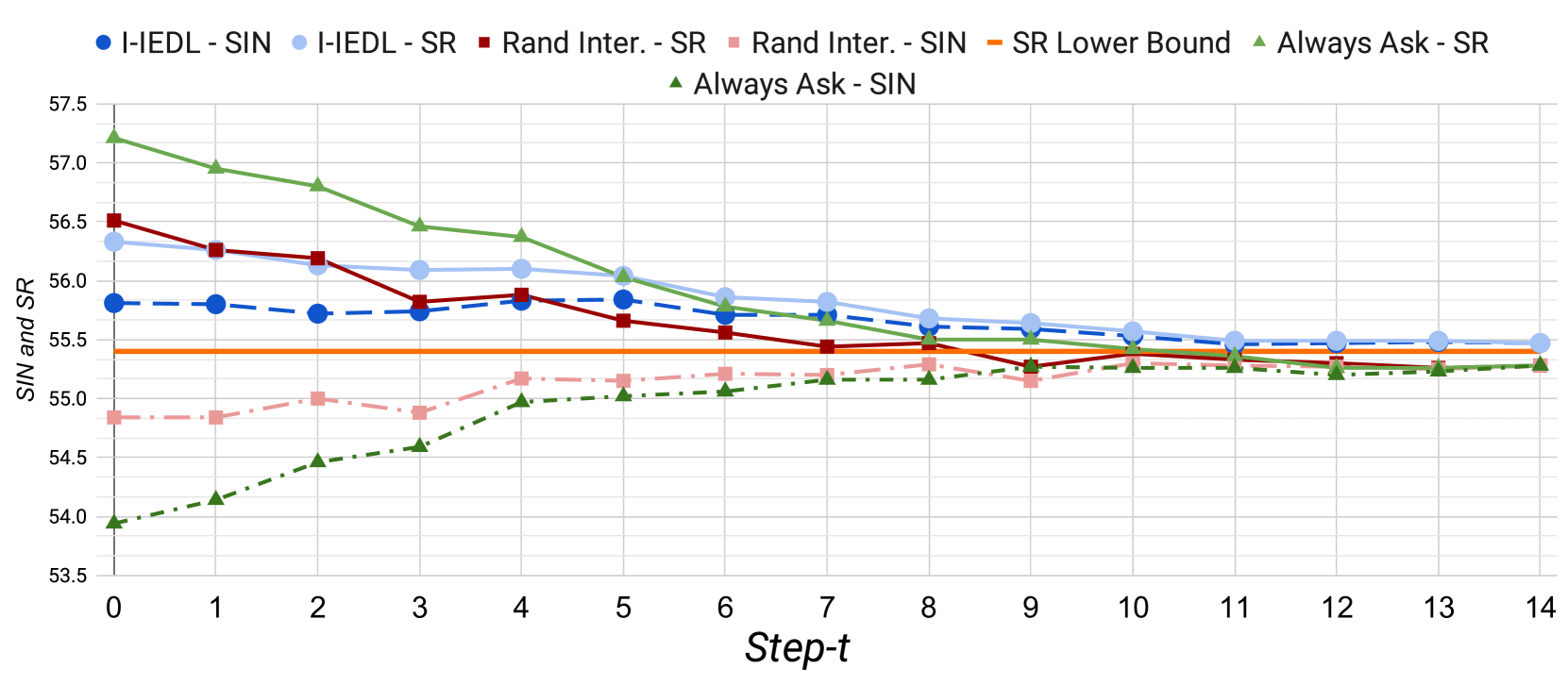
关键创新:该论文的关键创新在于提出了一个能够进行指令错误检测和定位的交互式框架I2EDL。与现有方法相比,I2EDL能够主动检测和纠正用户指令中的错误,从而提高了导航的鲁棒性和成功率。此外,该论文还提出了一个新的评估指标,即交互次数加权成功率(SIN),用于综合评估导航性能和交互有效性。
关键设计:I2EDL的关键设计包括:1) 使用预训练模型来提高指令错误检测的准确性。具体使用的预训练模型类型未知。2) 设计了一种交叉引用文本输入和过去观察的方法来精确定位指令中的错误。具体实现细节未知。3) 设计了一种有效的交互策略,以最小化交互次数,同时最大化导航成功率。具体策略细节未知。论文中还提出了一个新的评估指标SIN,用于衡量导航成功率和交互次数的平衡。
🖼️ 关键图片
📊 实验亮点
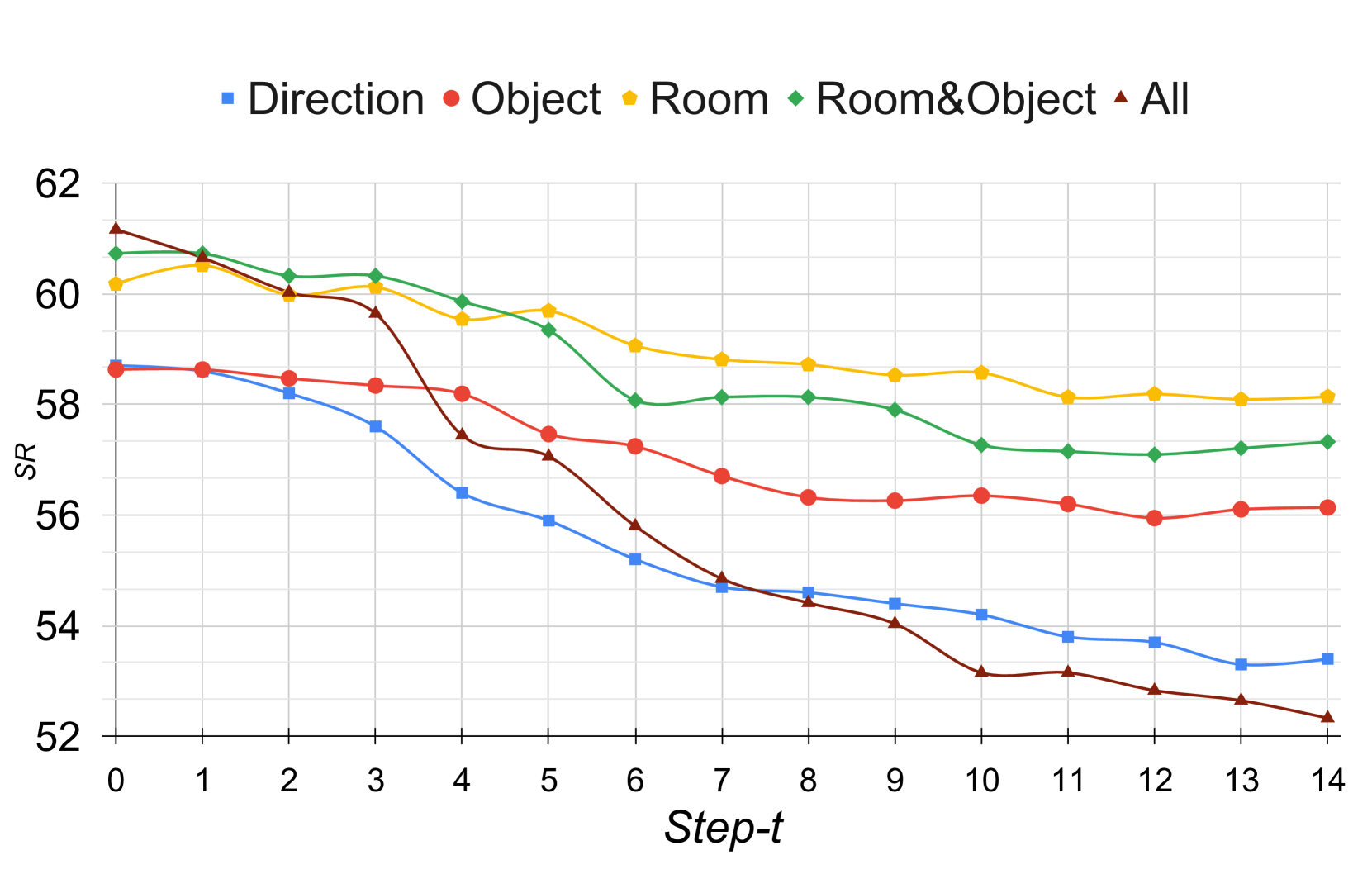
实验结果表明,提出的I2EDL能够有效地检测和定位指令错误,并通过与用户交互进行纠正,从而显著提高了导航成功率。此外,I2EDL还能够最小化交互次数,减少用户的认知负担。具体性能提升数据未知,与哪些基线方法进行了对比也未知。
🎯 应用场景
该研究成果可应用于各种需要人机协作的导航场景,例如辅助驾驶、智能家居、机器人导游等。通过检测和纠正用户指令中的错误,可以提高系统的可靠性和用户体验,降低操作风险,并最终实现更智能、更高效的人机交互。
📄 摘要(原文)
In the Vision-and-Language Navigation in Continuous Environments (VLN-CE) task, the human user guides an autonomous agent to reach a target goal via a series of low-level actions following a textual instruction in natural language. However, most existing methods do not address the likely case where users may make mistakes when providing such instruction (e.g. "turn left" instead of "turn right"). In this work, we address a novel task of Interactive VLN in Continuous Environments (IVLN-CE), which allows the agent to interact with the user during the VLN-CE navigation to verify any doubts regarding the instruction errors. We propose an Interactive Instruction Error Detector and Localizer (I2EDL) that triggers the user-agent interaction upon the detection of instruction errors during the navigation. We leverage a pre-trained module to detect instruction errors and pinpoint them in the instruction by cross-referencing the textual input and past observations. In such way, the agent is able to query the user for a timely correction, without demanding the user's cognitive load, as we locate the probable errors to a precise part of the instruction. We evaluate the proposed I2EDL on a dataset of instructions containing errors, and further devise a novel metric, the Success weighted by Interaction Number (SIN), to reflect both the navigation performance and the interaction effectiveness. We show how the proposed method can ask focused requests for corrections to the user, which in turn increases the navigation success, while minimizing the interactions.