Improving Generalization in Aerial and Terrestrial Mobile Robots Control Through Delayed Policy Learning
作者: Ricardo B. Grando, Raul Steinmetz, Victor A. Kich, Alisson H. Kolling, Pablo M. Furik, Junior C. de Jesus, Bruna V. Guterres, Daniel T. Gamarra, Rodrigo S. Guerra, Paulo L. J. Drews-Jr
分类: cs.RO, cs.AI
发布日期: 2024-06-04
备注: IEEE 20th International Conference on Automation Science and Engineering (CASE)
💡 一句话要点
提出基于延迟策略学习的DRL方法,提升移动机器人在未知环境中的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 延迟策略更新 移动机器人 自主导航 泛化能力
📋 核心要点
- 现有DRL方法在移动机器人自主导航中面临泛化性挑战,难以适应未知环境和任务。
- 论文采用延迟策略更新(DPU)技术,旨在提升DRL智能体在未知环境中的泛化能力和学习效率。
- 实验结果表明,DPU能有效减少泛化性不足,加速学习过程,提升智能体在多样化场景下的性能。
📝 摘要(中文)
深度强化学习(DRL)已成为增强机器人运动控制和决策的有效方法。虽然之前的研究表明DRL算法能够促进空中和地面移动机器人的自主无地图导航,但这些方法在面对未知任务和环境时,泛化能力往往较差。本文探讨了延迟策略更新(DPU)技术对促进泛化到新情况以及增强智能体整体性能的影响。我们对空中和地面移动机器人中DPU的分析表明,该技术显著减少了泛化能力的不足,并加速了智能体的学习过程,从而提高了它们在各种任务和未知场景中的效率。
🔬 方法详解
问题定义:现有基于DRL的移动机器人控制方法在面对未知环境和任务时,泛化能力不足,导致性能下降。这是因为DRL算法通常在特定训练环境中过度拟合,难以适应新的场景。因此,需要一种方法来提高DRL智能体在不同环境和任务中的适应性。
核心思路:论文的核心思路是引入延迟策略更新(DPU)技术。DPU通过延迟策略的更新,使得智能体在学习过程中能够更加稳定,避免过早地陷入局部最优解。这种延迟更新机制鼓励智能体探索更广泛的状态空间,从而提高其泛化能力。
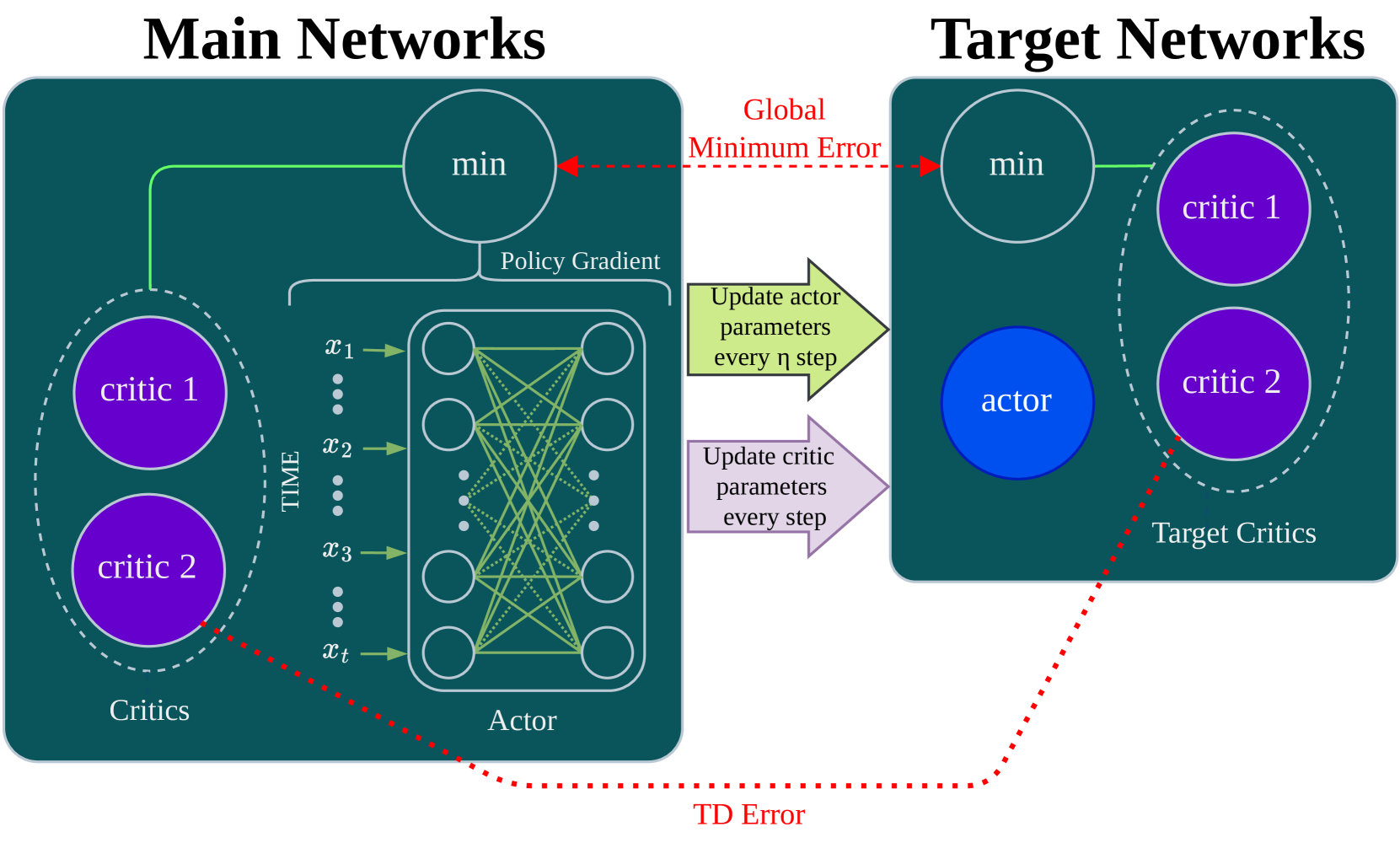
技术框架:整体框架包括环境交互模块、经验回放模块、策略网络和价值网络。智能体与环境交互,收集经验数据,并存储在经验回放缓冲区中。策略网络负责生成动作,价值网络评估状态的价值。DPU的关键在于,策略网络的更新频率低于价值网络,从而实现策略的延迟更新。
关键创新:最重要的技术创新点是DPU策略更新机制。与传统的同步更新方法不同,DPU通过延迟策略更新,避免了策略的快速变化,从而提高了学习的稳定性,并促进了智能体对环境的探索。这种延迟更新机制使得智能体能够更好地泛化到新的环境和任务中。
关键设计:论文中,策略网络和价值网络通常采用深度神经网络结构,例如多层感知机或卷积神经网络。损失函数通常采用时序差分误差或策略梯度损失。延迟更新的程度通过一个超参数控制,该参数决定了策略网络更新的频率。经验回放缓冲区的大小也是一个重要的参数,它影响了智能体学习的稳定性和效率。
🖼️ 关键图片


📊 实验亮点
论文通过在空中和地面移动机器人上的实验验证了DPU的有效性。实验结果表明,与传统的DRL方法相比,采用DPU的智能体在未知环境中的泛化能力显著提高,学习速度更快,性能更优。具体的性能提升数据在论文中进行了详细的展示和分析,证明了DPU在提升移动机器人自主导航能力方面的潜力。
🎯 应用场景
该研究成果可应用于多种移动机器人场景,包括无人机自主巡检、地面机器人自主导航、仓储物流等。通过提高机器人在未知环境中的泛化能力,可以降低人工干预的需求,提高机器人的自主性和适应性,从而降低运营成本,提升工作效率。未来,该技术有望在更复杂的机器人应用中发挥重要作用。
📄 摘要(原文)
Deep Reinforcement Learning (DRL) has emerged as a promising approach to enhancing motion control and decision-making through a wide range of robotic applications. While prior research has demonstrated the efficacy of DRL algorithms in facilitating autonomous mapless navigation for aerial and terrestrial mobile robots, these methods often grapple with poor generalization when faced with unknown tasks and environments. This paper explores the impact of the Delayed Policy Updates (DPU) technique on fostering generalization to new situations, and bolstering the overall performance of agents. Our analysis of DPU in aerial and terrestrial mobile robots reveals that this technique significantly curtails the lack of generalization and accelerates the learning process for agents, enhancing their efficiency across diverse tasks and unknown scenarios.