Deep Reinforcement Learning for Sim-to-Real Policy Transfer of VTOL-UAVs Offshore Docking Operations
作者: Ali M. Ali, Aryaman Gupta, Hashim A. Hashim
分类: cs.RO
发布日期: 2024-06-02 (更新: 2024-07-31)
💡 一句话要点
提出一种基于深度强化学习的VTOL-UAV海上平台着陆策略,实现从仿真到真实的策略迁移。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 无人机 自主着陆 海上平台 策略迁移
📋 核心要点
- 现有深度强化学习方法在无人机自主着陆任务中存在训练时间长、成功率不高等问题。
- 将着陆过程分解为接近和着陆两个阶段,结合模型控制和深度强化学习,提升策略学习效率。
- 利用JONSWAP谱模型生成波浪环境,增强策略在不同环境下的泛化能力,提高sim-to-real迁移的成功率。
📝 摘要(中文)
本文提出了一种新颖的强化学习(RL)方法,用于垂直起降无人机(VTOL-UAV)的仿真到真实策略迁移。该方法专为VTOL-UAV在海上作业中于海上停靠平台着陆而设计。海上作业中的VTOL-UAV面临着操作范围的限制,这主要源于电池容量的约束。自主着陆在充电平台上的概念为缓解这些限制提供了一个有趣的前景,因为它有助于电池充电和数据传输。然而,当前的深度强化学习(DRL)方法存在缺点,包括训练时间长和成功率适中。在本文中,我们通过将着陆过程分解为一系列更易于管理但相似的任务(即接近阶段和着陆阶段)来全面解决这些问题。所提出的架构在接近阶段采用基于模型的控制方案,其中VTOL-UAV接近海上停靠平台。在着陆阶段,离线训练DRL智能体以学习在海上平台停靠的最佳策略。采用联合北海波浪项目(JONSWAP)谱模型为每个episode创建波浪模型,从而增强了策略对sim2real迁移的泛化能力。通过数值模拟测试了一组DRL算法,包括基于价值的智能体和基于策略的智能体,例如深度Q网络(DQN)和近端策略优化(PPO)。数值实验表明,PPO智能体可以学习复杂而有效的策略,以便在不确定的环境中着陆,从而提高了成功进行sim-to-real迁移的可能性。
🔬 方法详解
问题定义:论文旨在解决VTOL-UAV在海上平台自主着陆的问题。现有方法,特别是直接应用深度强化学习,存在训练时间过长、对环境变化敏感、难以实现从仿真到真实环境的策略迁移等痛点。这些问题限制了无人机在海上作业中的应用,例如电池续航和数据传输。
核心思路:论文的核心思路是将复杂的着陆任务分解为两个阶段:接近阶段和着陆阶段。接近阶段采用基于模型的控制,利用已知的环境信息和无人机动力学模型,引导无人机接近目标平台。着陆阶段则采用深度强化学习,学习在复杂环境下的精细控制策略。这种分解降低了学习难度,提高了策略的泛化能力。
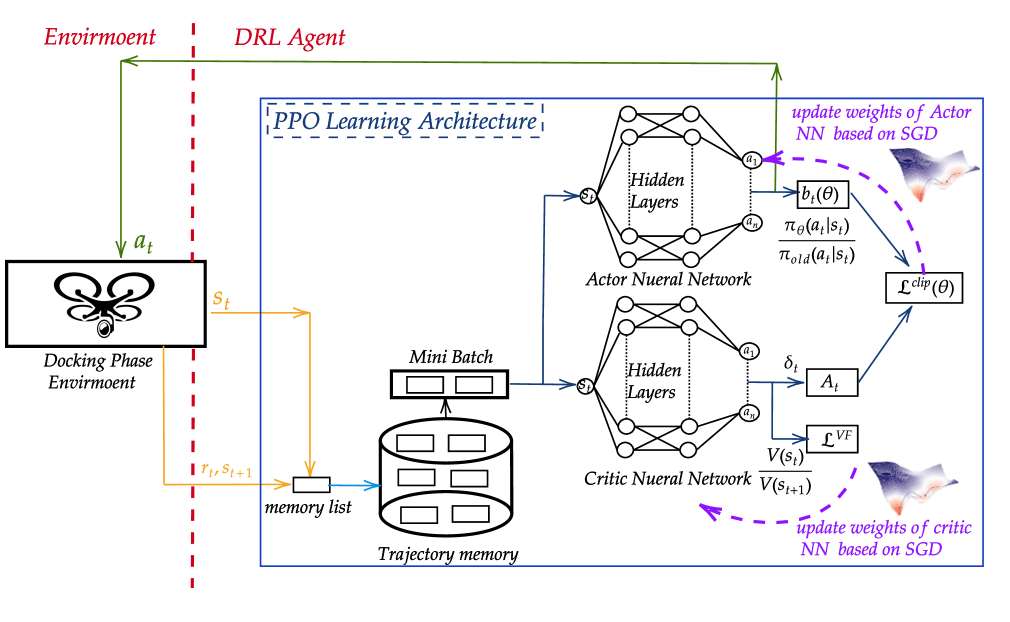
技术框架:整体框架包含两个主要阶段:接近阶段和着陆阶段。在接近阶段,使用基于模型的控制算法,如PID控制,引导无人机接近海上平台。在着陆阶段,使用深度强化学习算法训练智能体,使其学习如何在波浪等干扰下安全着陆。JONSWAP谱模型用于生成逼真的波浪环境,用于训练和评估智能体。
关键创新:最重要的创新点在于将基于模型的控制和深度强化学习相结合,并针对海上环境的特点进行优化。通过分解任务,降低了强化学习的难度,提高了训练效率和策略的鲁棒性。此外,使用JONSWAP谱模型模拟真实的海浪环境,增强了策略的泛化能力,有利于sim-to-real迁移。
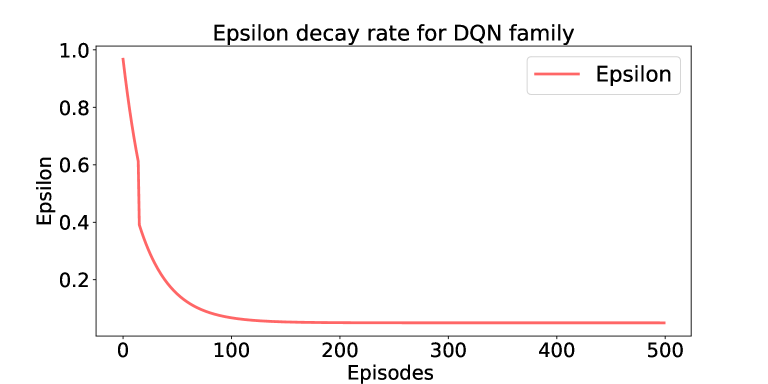
关键设计:论文测试了多种深度强化学习算法,包括DQN和PPO。PPO算法表现出更好的性能,能够学习到复杂且高效的着陆策略。JONSWAP谱模型的参数根据实际海况进行调整,以生成逼真的波浪环境。奖励函数的设计也至关重要,需要平衡着陆精度、安全性和效率。
🖼️ 关键图片
📊 实验亮点
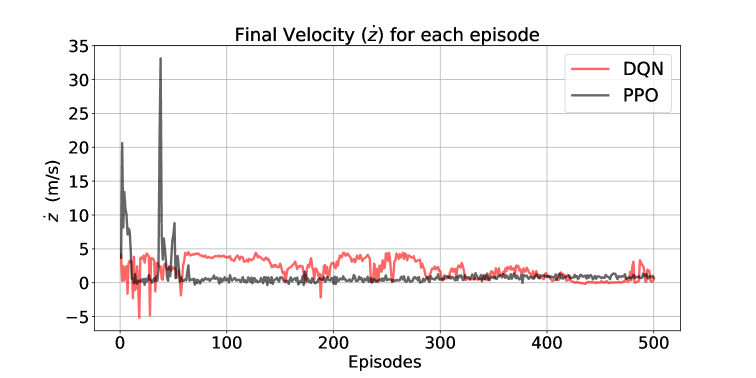
数值实验结果表明,采用PPO算法训练的智能体能够学习到复杂且有效的着陆策略,在不确定的波浪环境中实现安全着陆。相较于其他算法,PPO算法表现出更好的性能和鲁棒性,提高了成功进行sim-to-real迁移的可能性。具体性能数据未知。
🎯 应用场景
该研究成果可应用于海上石油平台巡检、海上风电场维护、海上搜救等领域。通过自主着陆充电,延长无人机在海上作业的续航时间,提高作业效率和安全性。未来,该技术可进一步扩展到其他复杂环境下的无人机自主着陆任务,例如移动平台着陆。
📄 摘要(原文)
This paper proposes a novel Reinforcement Learning (RL) approach for sim-to-real policy transfer of Vertical Take-Off and Landing Unmanned Aerial Vehicle (VTOL-UAV). The proposed approach is designed for VTOL-UAV landing on offshore docking stations in maritime operations. VTOL-UAVs in maritime operations encounter limitations in their operational range, primarily stemming from constraints imposed by their battery capacity. The concept of autonomous landing on a charging platform presents an intriguing prospect for mitigating these limitations by facilitating battery charging and data transfer. However, current Deep Reinforcement Learning (DRL) methods exhibit drawbacks, including lengthy training times, and modest success rates. In this paper, we tackle these concerns comprehensively by decomposing the landing procedure into a sequence of more manageable but analogous tasks in terms of an approach phase and a landing phase. The proposed architecture utilizes a model-based control scheme for the approach phase, where the VTOL-UAV is approaching the offshore docking station. In the Landing phase, DRL agents were trained offline to learn the optimal policy to dock on the offshore station. The Joint North Sea Wave Project (JONSWAP) spectrum model has been employed to create a wave model for each episode, enhancing policy generalization for sim2real transfer. A set of DRL algorithms have been tested through numerical simulations including value-based agents and policy-based agents such as Deep \textit{Q} Networks (DQN) and Proximal Policy Optimization (PPO) respectively. The numerical experiments show that the PPO agent can learn complicated and efficient policies to land in uncertain environments, which in turn enhances the likelihood of successful sim-to-real transfer.