Video-Language Critic: Transferable Reward Functions for Language-Conditioned Robotics
作者: Minttu Alakuijala, Reginald McLean, Isaac Woungang, Nariman Farsad, Samuel Kaski, Pekka Marttinen, Kai Yuan
分类: cs.RO, cs.AI, cs.CL, cs.CV, cs.LG
发布日期: 2024-05-30 (更新: 2025-09-17)
备注: 14 pages in the main text, 22 pages including references and supplementary materials. 3 figures and 3 tables in the main text, 6 figures and 3 tables in supplementary materials
期刊: Transactions on Machine Learning Research (TMLR) (02/2025)
💡 一句话要点
提出Video-Language Critic,用于语言条件机器人任务的可迁移奖励函数学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言条件机器人 奖励函数学习 跨具身学习 对比学习 时间排序 视频语言模型 机器人学习
📋 核心要点
- 现有语言条件机器人学习方法依赖大量特定机器人的语言标注数据,成本高昂且泛化性差。
- Video-Language Critic通过对比学习和时间排序,利用跨具身视频数据学习可迁移的奖励函数,解耦任务目标与执行方式。
- 实验表明,该方法在Meta-World任务上显著提升了样本效率,并在泛化性方面优于现有语言条件奖励模型。
📝 摘要(中文)
本文提出Video-Language Critic,旨在解决机器人学习中语言指令泛化性问题。该方法将任务目标与执行方式解耦,利用大量跨具身观察数据学习奖励模型,从而避免了对特定机器人进行大量语言标注演示的需求。Video-Language Critic通过对比学习和时间排序目标函数,在易于获取的跨具身数据上进行训练,并用于评估来自独立Actor的行为轨迹。在Open X-Embodiment数据集上的实验表明,相比于稀疏奖励,该奖励模型在Meta-World任务上实现了2倍的样本效率提升。此外,在Meta-World任务的泛化设置下,该方法也优于其他基于二元分类、静态图像或未利用视频时序信息的语言条件奖励模型。
🔬 方法详解
问题定义:现有语言条件机器人学习方法需要大量特定机器人上的语言标注数据,这限制了其可扩展性和泛化能力。主要痛点在于,如何从有限的机器人交互数据中学习到能够泛化到不同机器人和环境的语言指令理解能力。
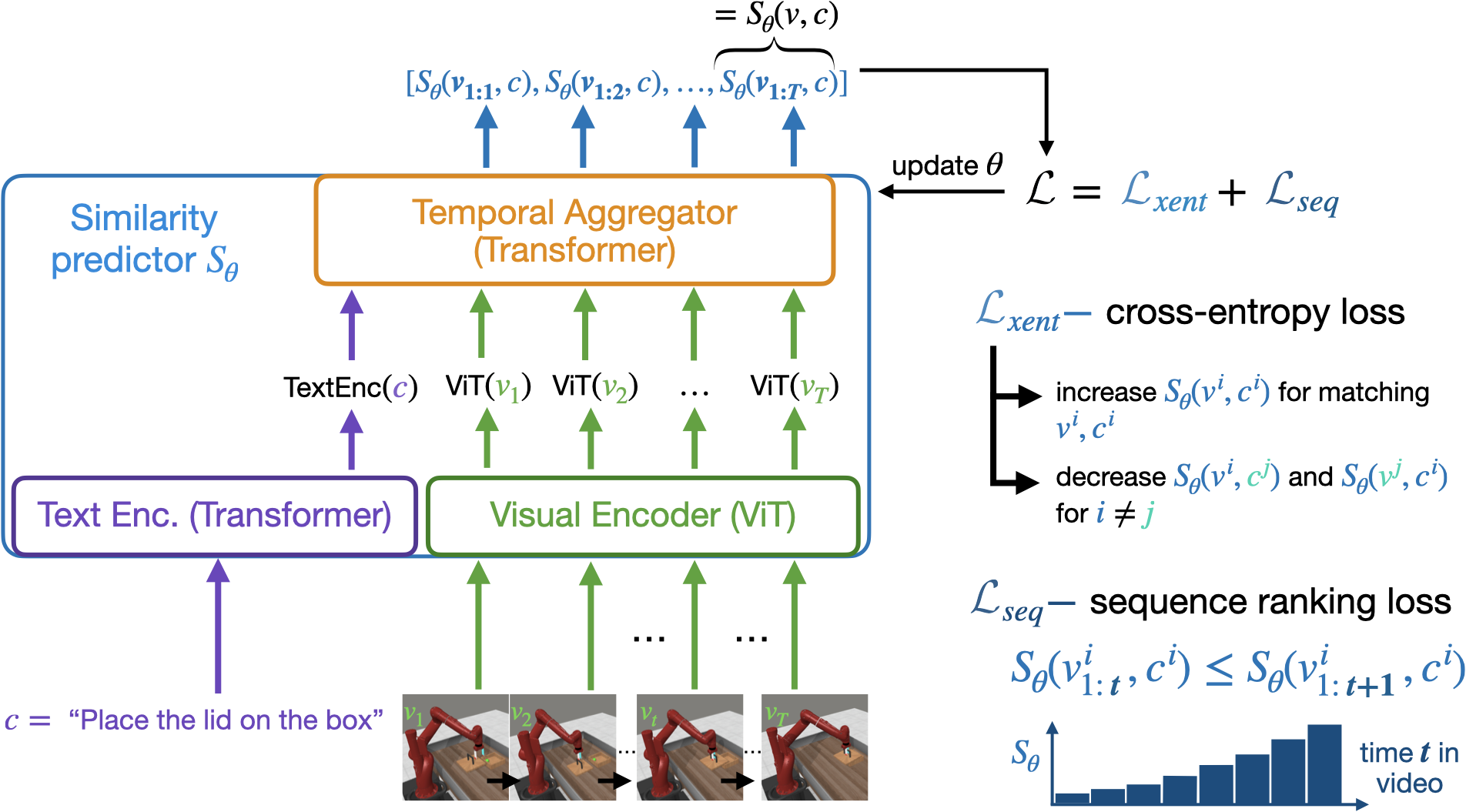
核心思路:本文的核心思路是将任务目标(what to accomplish)与执行方式(how to accomplish it)解耦。任务目标可以通过观察大量跨具身数据来学习,而执行方式则依赖于特定的机器人。通过学习一个能够评估行为轨迹与语言指令匹配程度的奖励函数,可以利用外部观察数据来指导机器人学习。
技术框架:Video-Language Critic的整体框架包含两个主要部分:奖励模型训练和策略学习。奖励模型使用对比学习和时间排序目标函数,在跨具身视频数据上进行训练。策略学习则使用训练好的奖励模型来评估Actor生成的行为轨迹,并使用强化学习算法优化策略。
关键创新:该方法最重要的创新点在于利用跨具身视频数据学习可迁移的奖励函数。与传统的基于二元分类或静态图像的奖励模型相比,Video-Language Critic能够更好地利用视频中的时序信息,并泛化到不同的机器人和环境。
关键设计:奖励模型采用对比学习框架,通过最大化正样本(匹配的视频和语言指令)的相似度,最小化负样本(不匹配的视频和语言指令)的相似度来学习。时间排序目标函数则鼓励模型对更接近目标的行为轨迹给予更高的奖励。具体的网络结构和参数设置在论文中有详细描述,例如使用了Transformer网络来编码视频和语言信息。
🖼️ 关键图片


📊 实验亮点
在Open X-Embodiment数据集上,Video-Language Critic在Meta-World任务上实现了2倍于稀疏奖励的样本效率提升。在Meta-World任务的泛化设置下,该方法也优于其他基于二元分类、静态图像或未利用视频时序信息的语言条件奖励模型,证明了其在泛化性和样本效率方面的优势。
🎯 应用场景
该研究成果可应用于各种语言条件机器人任务,例如家庭服务机器人、工业机器人等。通过利用大量的外部观察数据,可以降低机器人学习的成本,提高机器人的泛化能力和适应性。未来,该方法可以进一步扩展到更复杂的任务和环境,实现更智能、更灵活的机器人控制。
📄 摘要(原文)
Natural language is often the easiest and most convenient modality for humans to specify tasks for robots. However, learning to ground language to behavior typically requires impractical amounts of diverse, language-annotated demonstrations collected on each target robot. In this work, we aim to separate the problem of what to accomplish from how to accomplish it, as the former can benefit from substantial amounts of external observation-only data, and only the latter depends on a specific robot embodiment. To this end, we propose Video-Language Critic, a reward model that can be trained on readily available cross-embodiment data using contrastive learning and a temporal ranking objective, and use it to score behavior traces from a separate actor. When trained on Open X-Embodiment data, our reward model enables 2x more sample-efficient policy training on Meta-World tasks than a sparse reward only, despite a significant domain gap. Using in-domain data but in a challenging task generalization setting on Meta-World, we further demonstrate more sample-efficient training than is possible with prior language-conditioned reward models that are either trained with binary classification, use static images, or do not leverage the temporal information present in video data.