A Survey on Vision-Language-Action Models for Embodied AI
作者: Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
分类: cs.RO, cs.CL, cs.CV
发布日期: 2024-05-23 (更新: 2026-02-04)
备注: Project page: https://github.com/yueen-ma/Awesome-VLA
🔗 代码/项目: GITHUB
💡 一句话要点
对具身智能中视觉-语言-动作模型(VLA)的全面综述
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言-动作模型 机器人 多模态学习 任务规划
📋 核心要点
- 现有具身智能方法在处理复杂、长时程任务时面临挑战,难以有效利用语言指令进行任务分解和动作规划。
- 本文对视觉-语言-动作模型(VLA)进行了系统性综述,旨在梳理VLA的研究脉络,并为未来的研究提供指导。
- 论文总结了VLA的三个主要研究方向,并提供了相关资源,包括数据集、模拟器和基准,为研究人员提供了便利。
📝 摘要(中文)
具身智能被广泛认为是通用人工智能的基石,因为它涉及控制具身智能体在物理世界中执行任务。 借助大型语言模型和视觉-语言模型的成功,一种新的多模态模型——视觉-语言-动作模型(VLA)——已经出现,通过利用其独特的生成动作能力来解决具身智能中语言条件下的机器人任务。 近期VLA的迅速普及需要一个全面的综述来捕捉快速发展的格局。 为此,我们提出了第一个关于具身智能VLA的综述。 这项工作提供了VLA的详细分类,分为三个主要研究方向。 第一个方向侧重于VLA的各个组成部分。 第二个方向致力于开发基于VLA的控制策略,擅长预测低级动作。 第三个方向包括高级任务规划器,能够将长时程任务分解为一系列子任务,从而指导VLA遵循更通用的用户指令。 此外,我们还提供了相关资源的广泛总结,包括数据集、模拟器和基准。 最后,我们讨论了VLA面临的挑战,并概述了具身智能领域有希望的未来方向。 与本调查相关的精选存储库可在以下网址获得:https://github.com/yueen-ma/Awesome-VLA。
🔬 方法详解
问题定义:论文旨在解决具身智能领域中,如何利用视觉、语言信息指导智能体执行复杂任务的问题。现有方法通常难以处理长时程任务,并且对语言指令的理解和利用不够充分。这导致智能体在复杂环境中难以有效地完成任务。
核心思路:论文的核心思路是对现有的视觉-语言-动作模型(VLA)进行全面的梳理和分类,从而为研究人员提供一个清晰的VLA研究框架。通过分析VLA的不同组成部分、控制策略和任务规划方法,论文旨在揭示VLA在具身智能中的应用潜力,并为未来的研究方向提供指导。
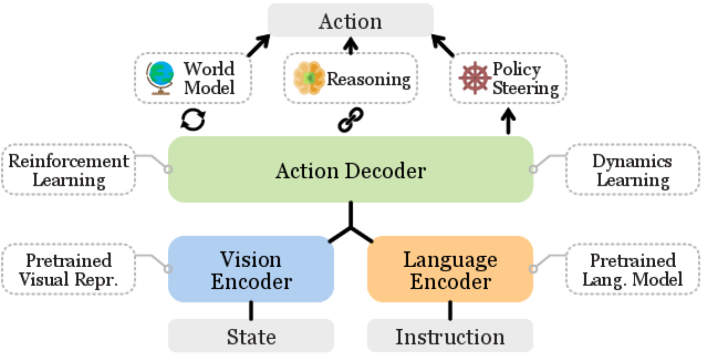
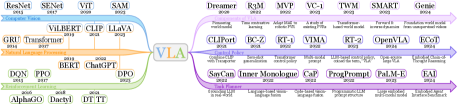
技术框架:论文将VLA的研究分为三个主要方向:1) VLA的各个组成部分的研究,例如视觉编码器、语言模型和动作解码器;2) 基于VLA的控制策略的研究,侧重于预测低级动作,例如机器人关节控制;3) 高级任务规划器的研究,旨在将长时程任务分解为子任务,并指导VLA完成任务。论文还总结了相关的数据集、模拟器和基准。
关键创新:该论文是首个针对具身智能中视觉-语言-动作模型(VLA)的全面综述。它系统地整理了VLA的研究进展,并提出了一个清晰的VLA分类框架。与以往的综述相比,该论文更加关注VLA在具身智能中的应用,并对未来的研究方向进行了展望。
关键设计:论文的关键设计在于其VLA分类框架,该框架将VLA的研究分为三个主要方向,并对每个方向的研究进展进行了详细的分析。此外,论文还对相关的数据集、模拟器和基准进行了总结,为研究人员提供了便利。论文没有涉及具体的参数设置、损失函数或网络结构,因为其重点在于综述和分类。
🖼️ 关键图片
📊 实验亮点
该综述论文系统地整理了视觉-语言-动作模型(VLA)在具身智能领域的应用,并对未来的研究方向进行了展望。虽然没有提供具体的性能数据,但它为研究人员提供了一个全面的VLA研究框架,并指出了VLA在解决复杂具身智能任务方面的潜力。
🎯 应用场景
该研究对具身智能领域具有重要意义,可应用于机器人导航、物体操作、人机协作等多种场景。通过VLA模型,机器人可以更好地理解人类指令,并在复杂环境中自主完成任务,从而提高生产效率和生活质量。未来,VLA有望在智能家居、自动驾驶、医疗健康等领域发挥更大的作用。
📄 摘要(原文)
Embodied AI is widely recognized as a cornerstone of artificial general intelligence because it involves controlling embodied agents to perform tasks in the physical world. Building on the success of large language models and vision-language models, a new category of multimodal models -- referred to as vision-language-action models (VLAs) -- has emerged to address language-conditioned robotic tasks in embodied AI by leveraging their distinct ability to generate actions. The recent proliferation of VLAs necessitates a comprehensive survey to capture the rapidly evolving landscape. To this end, we present the first survey on VLAs for embodied AI. This work provides a detailed taxonomy of VLAs, organized into three major lines of research. The first line focuses on individual components of VLAs. The second line is dedicated to developing VLA-based control policies adept at predicting low-level actions. The third line comprises high-level task planners capable of decomposing long-horizon tasks into a sequence of subtasks, thereby guiding VLAs to follow more general user instructions. Furthermore, we provide an extensive summary of relevant resources, including datasets, simulators, and benchmarks. Finally, we discuss the challenges facing VLAs and outline promising future directions in embodied AI. A curated repository associated with this survey is available at: https://github.com/yueen-ma/Awesome-VLA.