Going into Orbit: Massively Parallelizing Episodic Reinforcement Learning
作者: Jan Oberst, Johann Bonneau
分类: cs.RO
发布日期: 2024-05-19
💡 一句话要点
利用Orbit框架,大规模并行化Episodic强化学习,提升机器人控制效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人控制 并行计算 GPU加速 Orbit框架
📋 核心要点
- 深度强化学习在机器人控制中面临安全性和采样效率的挑战,仿真环境和并行化是关键解决方案。
- 本文利用NVIDIA Orbit框架,通过GPU并行化加速强化学习训练,提升采样效率。
- 在箱子推任务中,实验表明Orbit框架能够显著提升样本生成速度,验证了其并行化优势。
📝 摘要(中文)
深度强化学习在机器人控制领域展现出巨大潜力。为了解决安全性和采样效率问题,通常在仿真环境中训练深度强化学习模型,以加快迭代速度。通过使用GPU并行化训练过程,可以进一步提升效率。NVIDIA的开源机器人学习框架Orbit,通过封装基于张量的强化学习库以实现高并行性,并以Isaac Sim为基础进行仿真,充分利用了这一潜力。本文详细描述了使用Orbit实现基准强化学习任务(即箱子推)的过程。此外,我们对该实现与基于CPU的实现进行了性能基准测试,并报告了性能指标。最后,我们调整了实现的超参数,表明使用Orbit可以在相同时间内生成明显更多的样本。
🔬 方法详解
问题定义:现有深度强化学习方法在机器人控制领域面临安全性和采样效率的挑战。在真实机器人上直接训练成本高昂且存在安全风险,而传统的CPU训练方式难以满足大规模数据需求,限制了迭代速度。
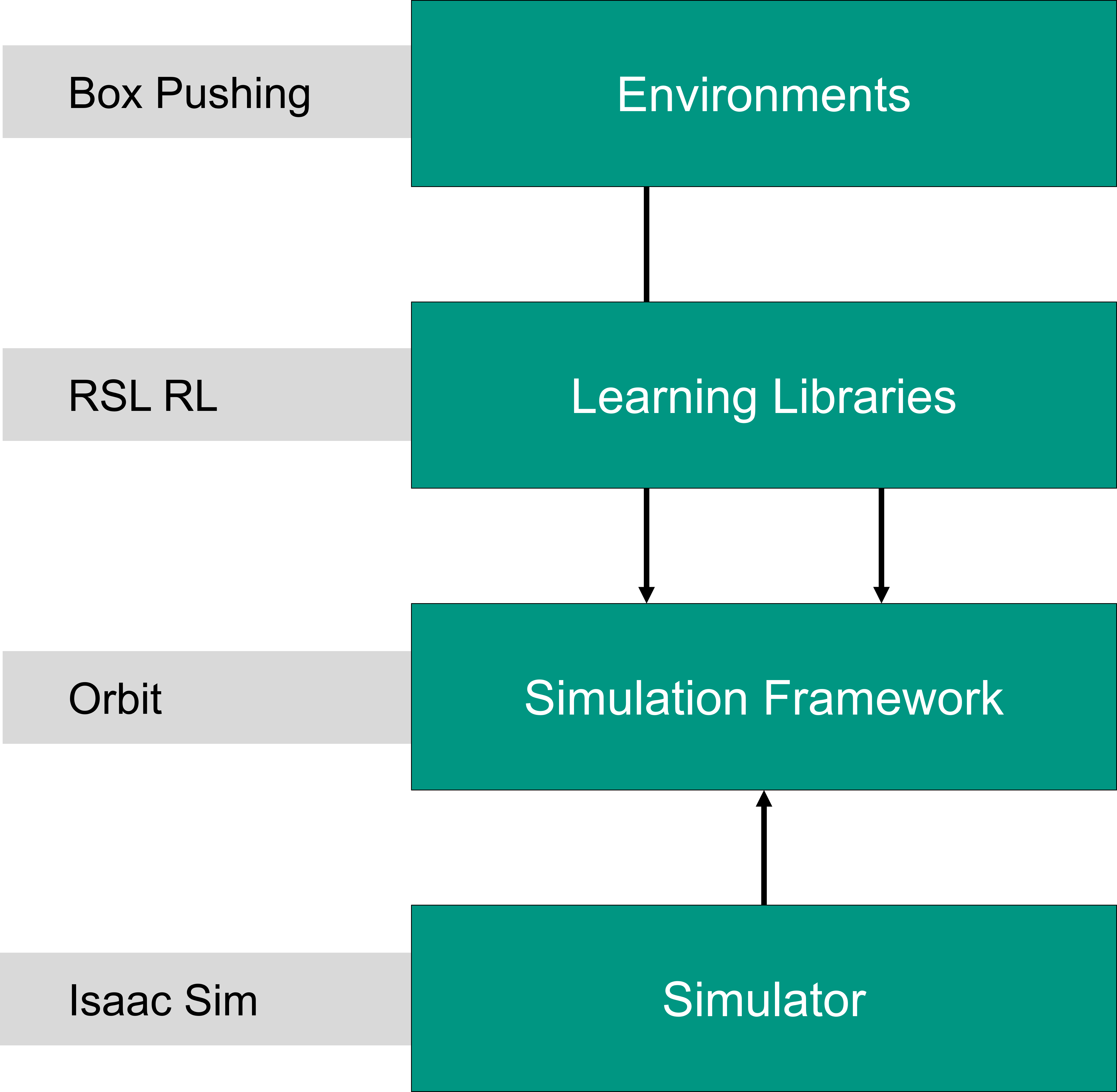
核心思路:利用GPU强大的并行计算能力,通过NVIDIA Orbit框架加速强化学习训练过程。Orbit框架封装了基于张量的强化学习库,并构建于Isaac Sim仿真平台之上,能够高效地进行大规模并行仿真和数据生成。
技术框架:该研究使用Orbit框架构建了一个箱子推任务的强化学习训练环境。整体流程包括:1) 在Isaac Sim中搭建仿真环境;2) 使用Orbit提供的接口定义强化学习任务和奖励函数;3) 利用GPU并行运行多个仿真实例,生成大量训练数据;4) 使用基于张量的强化学习算法(具体算法未知)进行模型训练;5) 评估训练好的模型在仿真环境中的性能。
关键创新:该研究的关键创新在于利用Orbit框架实现了大规模并行化的强化学习训练。与传统的CPU训练方式相比,Orbit框架能够充分利用GPU的计算资源,显著提升样本生成速度和训练效率。这使得研究人员能够更快地迭代和优化强化学习模型,从而加速机器人控制算法的开发。
关键设计:论文中提到对超参数进行了调整,但没有给出具体的参数设置。损失函数和网络结构等技术细节也未在摘要中提及,因此这些信息未知。关键设计可能包括:并行仿真实例的数量、强化学习算法的选择和参数设置、奖励函数的具体设计等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Orbit框架可以显著提升样本生成速度,从而加速强化学习模型的训练。具体性能数据和提升幅度在摘要中未明确给出,但强调了Orbit框架在相同时间内能够生成明显更多的样本,表明其并行化优势显著。
🎯 应用场景
该研究成果可应用于各种机器人控制任务,例如自动驾驶、工业自动化、物流仓储等。通过大规模并行化强化学习训练,可以加速机器人控制算法的开发和部署,提高机器人的智能化水平和工作效率。未来,该方法有望应用于更复杂的机器人任务,例如多机器人协同、复杂环境导航等。
📄 摘要(原文)
The possibilities of robot control have multiplied across various domains through the application of deep reinforcement learning. To overcome safety and sampling efficiency issues, deep reinforcement learning models can be trained in a simulation environment, allowing for faster iteration cycles. This can be enhanced further by parallelizing the training process using GPUs. NVIDIA's open-source robot learning framework Orbit leverages this potential by wrapping tensor-based reinforcement learning libraries for high parallelism and building upon Isaac Sim for its simulations. We contribute a detailed description of the implementation of a benchmark reinforcement learning task, namely box pushing, using Orbit. Additionally, we benchmark the performance of our implementation in comparison to a CPU-based implementation and report the performance metrics. Finally, we tune the hyper parameters of our implementation and show that we can generate significantly more samples in the same amount of time by using Orbit.