Towards Consistent and Explainable Motion Prediction using Heterogeneous Graph Attention
作者: Tobias Demmler, Andreas Tamke, Thao Dang, Karsten Haug, Lars Mikelsons
分类: cs.RO, cs.AI
发布日期: 2024-05-16
💡 一句话要点
提出异构图注意力网络,用于自动驾驶中一致且可解释的运动预测。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 运动预测 自动驾驶 异构图注意力网络 轨迹预测 可解释性
📋 核心要点
- 现有运动预测方法在编码过程中可能丢失精确位置信息,导致预测轨迹偏离实际车道。
- 论文提出一种细化模块,将预测轨迹投影回实际地图,并设计异构图注意力网络编码场景关系。
- 该方法旨在提高运动预测的一致性和可解释性,并能方便地集成到多种现有架构中。
📝 摘要(中文)
在自动驾驶中,准确理解其他道路使用者的行为并预测其未来轨迹至关重要。通常,这通过整合地图数据和各种智能体的跟踪轨迹来实现。许多方法将这些信息组合成每个智能体的单一嵌入,然后用于预测未来的行为。然而,这些方法的一个显著缺点是,它们可能在编码过程中丢失精确的位置信息。虽然编码仍然包含一般的地图信息,但无法保证生成有效且一致的轨迹,这可能导致预测的轨迹偏离实际车道。本文介绍了一种新的细化模块,旨在将预测的轨迹投影回实际地图,纠正这些差异,从而实现更一致的预测。这种通用模块可以很容易地集成到各种架构中。此外,我们提出了一种新的场景编码器,它在一个统一的异构图注意力网络中处理智能体及其环境之间的所有关系。通过分析该图中不同边上的注意力值,我们可以深入了解神经网络的内部运作,从而实现更可解释的预测。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景中运动预测不一致和缺乏可解释性的问题。现有方法在编码场景信息时,容易丢失精确的位置信息,导致预测的轨迹偏离实际车道,并且难以理解模型做出预测的原因。
核心思路:论文的核心思路是利用一个细化模块将预测的轨迹投影回实际地图,从而保证轨迹的一致性。同时,使用异构图注意力网络来编码场景信息,通过分析不同边上的注意力值来提高预测的可解释性。
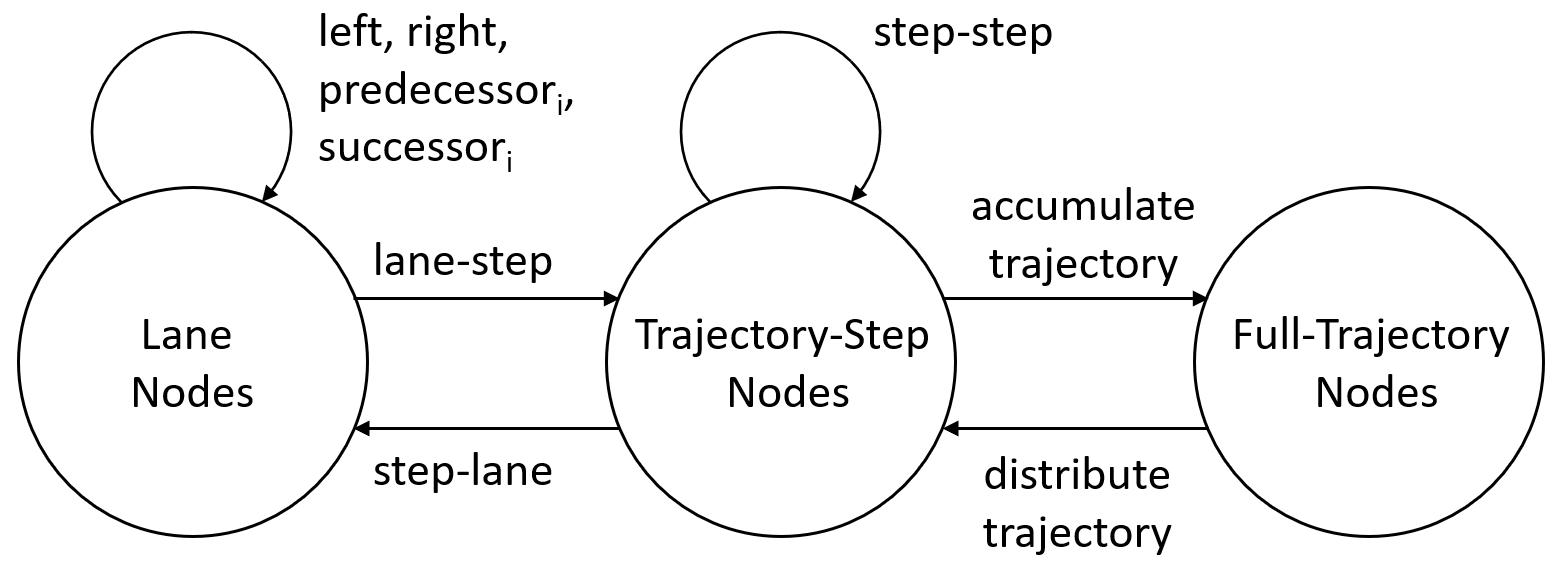
技术框架:整体框架包含两个主要模块:场景编码器和轨迹细化模块。场景编码器使用异构图注意力网络来编码智能体及其环境之间的关系,生成场景表示。轨迹细化模块将预测的轨迹投影回实际地图,修正轨迹偏差。整个流程是先通过场景编码器得到场景表示,然后使用现有的运动预测模型进行轨迹预测,最后使用轨迹细化模块修正预测结果。
关键创新:论文的关键创新在于提出了轨迹细化模块和异构图注意力网络。轨迹细化模块能够有效地将预测轨迹约束在合理的道路范围内,提高预测的一致性。异构图注意力网络能够同时处理智能体和环境之间的多种关系,并且通过分析注意力权重来提高预测的可解释性。
关键设计:异构图注意力网络的设计需要考虑不同类型节点(例如,智能体、车道)和边(例如,智能体之间的交互、智能体与车道之间的关系)的表示方法。轨迹细化模块可能涉及到基于地图信息的投影操作,例如,将轨迹点投影到最近的车道中心线上。损失函数的设计可能包括轨迹预测误差、轨迹一致性损失等。
🖼️ 关键图片


📊 实验亮点
论文提出了一种新的轨迹细化模块和异构图注意力网络,旨在提高运动预测的一致性和可解释性。通过将预测轨迹投影回实际地图,有效纠正了轨迹偏差。异构图注意力网络能够同时处理智能体和环境之间的多种关系,并通过分析注意力权重来提高预测的可解释性。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动驾驶系统,提高车辆对周围交通参与者行为的预测精度和安全性。更一致和可解释的运动预测有助于自动驾驶车辆做出更合理的决策,例如变道、超车和避障,从而提升自动驾驶的可靠性和用户信任度。此外,该方法也可用于交通仿真和智能交通管理等领域。
📄 摘要(原文)
In autonomous driving, accurately interpreting the movements of other road users and leveraging this knowledge to forecast future trajectories is crucial. This is typically achieved through the integration of map data and tracked trajectories of various agents. Numerous methodologies combine this information into a singular embedding for each agent, which is then utilized to predict future behavior. However, these approaches have a notable drawback in that they may lose exact location information during the encoding process. The encoding still includes general map information. However, the generation of valid and consistent trajectories is not guaranteed. This can cause the predicted trajectories to stray from the actual lanes. This paper introduces a new refinement module designed to project the predicted trajectories back onto the actual map, rectifying these discrepancies and leading towards more consistent predictions. This versatile module can be readily incorporated into a wide range of architectures. Additionally, we propose a novel scene encoder that handles all relations between agents and their environment in a single unified heterogeneous graph attention network. By analyzing the attention values on the different edges in this graph, we can gain unique insights into the neural network's inner workings leading towards a more explainable prediction.