Combining RL and IL using a dynamic, performance-based modulation over learning signals and its application to local planning
作者: Francisco Leiva, Javier Ruiz-del-Solar
分类: cs.RO
发布日期: 2024-05-16
备注: 17 pages, 11 figures
💡 一句话要点
提出一种基于动态性能调制的RL与IL融合方法,用于移动机器人局部规划
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模仿学习 机器人局部规划 动态权重调整 行为克隆
📋 核心要点
- 现有强化学习方法样本效率低,模仿学习泛化性不足,难以适应复杂环境。
- 提出一种动态性能调制方法,根据智能体表现动态调整RL和IL信号的权重,实现平滑过渡。
- 实验表明,该方法在样本效率和性能上均优于纯RL和纯IL,并成功应用于真实机器人。
📝 摘要(中文)
本文提出了一种结合强化学习(RL)和模仿学习(IL)的方法,该方法使用基于动态性能的调制来调整学习信号。具体而言,该方法结合了RL和行为克隆(IL),或动作空间中的纠正反馈(交互式IL/IIL),通过动态地加权待优化的损失函数,同时考虑用于更新策略的反向传播梯度和智能体的估计性能。通过这种方式,RL和IL/IIL损失被组合,以均衡它们对策略更新的影响,同时调节这种影响,使得IL信号在学习过程的开始阶段被优先考虑,并且随着智能体性能的提高,RL信号逐渐变得更加重要,从而实现从纯IL/IIL到纯RL的平滑过渡。该方法被用于学习移动机器人的局部规划策略,通过脚本策略在线合成IL/IIL信号。在仿真中对该方法进行了广泛的评估,实验结果表明,该方法在样本效率方面优于纯RL(在训练环境中达到相同的性能水平,使用的经验大约减少了4倍),同时始终产生具有更好性能指标的局部规划策略(在评估环境中实现了0.959的平均成功率,比纯RL高12.5%,比纯IL高13.9%)。此外,所获得的局部规划策略已成功部署在现实世界中,无需进行任何重大微调。该方法可以扩展现有的RL算法,并且适用于在线生成IL/IIL信号可行的其他问题。
🔬 方法详解
问题定义:论文旨在解决移动机器人局部规划中,纯强化学习样本效率低,纯模仿学习泛化能力差的问题。现有方法要么需要大量的训练数据,要么难以适应未见过的环境。
核心思路:核心思路是结合强化学习和模仿学习的优点,通过动态调整两种学习信号的权重,实现从模仿学习到强化学习的平滑过渡。在学习初期,模仿学习提供指导,加速学习过程;随着智能体性能提升,强化学习逐渐占据主导,提升策略的泛化能力。
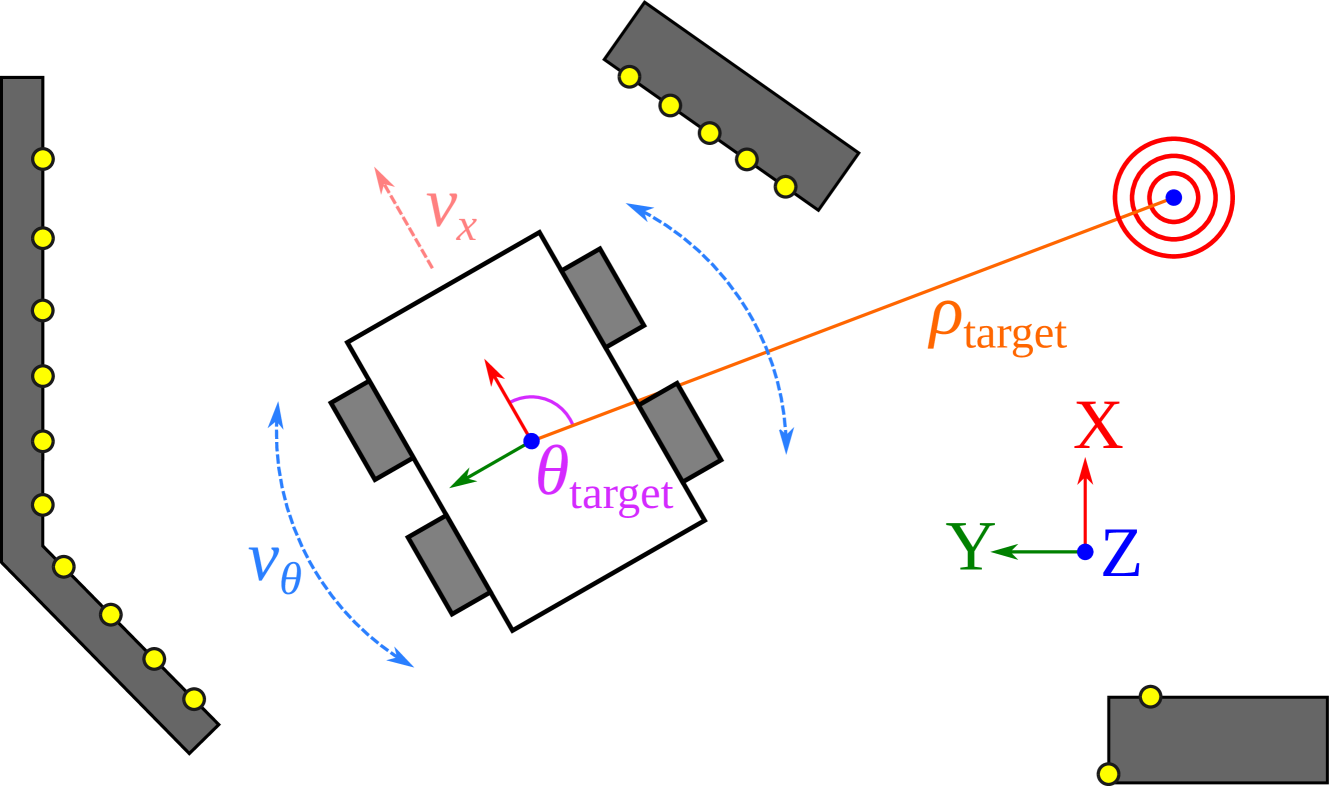
技术框架:整体框架包含以下几个主要部分:1) 环境交互,智能体与环境交互,收集经验数据;2) 模仿学习信号生成,通过脚本策略在线生成模仿学习信号;3) 损失函数计算,分别计算强化学习损失和模仿学习损失;4) 动态权重调整,根据智能体的性能动态调整两种损失的权重;5) 策略更新,使用反向传播更新策略。
关键创新:最重要的创新点在于动态权重调整机制。该机制根据智能体的性能,自适应地调整强化学习和模仿学习信号的权重,避免了固定权重带来的问题。这种动态调整使得智能体能够在学习初期快速学习,并在后期获得更好的泛化能力。
关键设计:关键设计包括:1) 使用行为克隆作为模仿学习方法;2) 使用脚本策略在线生成模仿学习信号;3) 使用基于梯度和智能体性能的动态权重调整策略。具体而言,权重调整策略考虑了反向传播梯度,以均衡两种损失对策略更新的影响,并根据智能体的估计性能,逐步增加强化学习信号的权重。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在样本效率方面优于纯RL,达到相同性能所需的经验减少了约4倍。在评估环境中,该方法实现了0.959的平均成功率,比纯RL高12.5%,比纯IL高13.9%。此外,该方法训练得到的策略成功部署于真实机器人,无需重大微调,验证了其在实际应用中的有效性。
🎯 应用场景
该方法可应用于各种需要结合专家知识和自主学习的机器人任务,例如自动驾驶、无人机导航、机械臂操作等。通过利用专家知识加速学习过程,并利用强化学习提升策略的泛化能力,可以有效解决复杂环境下的机器人控制问题,具有重要的实际应用价值。
📄 摘要(原文)
This paper proposes a method to combine reinforcement learning (RL) and imitation learning (IL) using a dynamic, performance-based modulation over learning signals. The proposed method combines RL and behavioral cloning (IL), or corrective feedback in the action space (interactive IL/IIL), by dynamically weighting the losses to be optimized, taking into account the backpropagated gradients used to update the policy and the agent's estimated performance. In this manner, RL and IL/IIL losses are combined by equalizing their impact on the policy's updates, while modulating said impact such that IL signals are prioritized at the beginning of the learning process, and as the agent's performance improves, the RL signals become progressively more relevant, allowing for a smooth transition from pure IL/IIL to pure RL. The proposed method is used to learn local planning policies for mobile robots, synthesizing IL/IIL signals online by means of a scripted policy. An extensive evaluation of the application of the proposed method to this task is performed in simulations, and it is empirically shown that it outperforms pure RL in terms of sample efficiency (achieving the same level of performance in the training environment utilizing approximately 4 times less experiences), while consistently producing local planning policies with better performance metrics (achieving an average success rate of 0.959 in an evaluation environment, outperforming pure RL by 12.5% and pure IL by 13.9%). Furthermore, the obtained local planning policies are successfully deployed in the real world without performing any major fine tuning. The proposed method can extend existing RL algorithms, and is applicable to other problems for which generating IL/IIL signals online is feasible. A video summarizing some of the real world experiments that were conducted can be found in https://youtu.be/mZlaXn9WGzw.