Memory-Maze: Scenario Driven Visual Language Navigation Benchmark for Guiding Blind People
作者: Masaki Kuribayashi, Kohei Uehara, Allan Wang, Daisuke Sato, Simon Chu, Shigeo Morishima
分类: cs.RO
发布日期: 2024-05-11 (更新: 2026-01-27)
💡 一句话要点
提出Memory-Maze基准,用于解决视觉语言导航中面向盲人引导的记忆指令理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 盲人引导 记忆指令 机器人导航 基准数据集
📋 核心要点
- 现有视觉语言导航模型难以处理盲人引导场景中基于记忆的路线指令,此类指令包含更多错误和不确定性。
- Memory-Maze基准通过构建迷宫环境和收集人类记忆指令数据,模拟了盲人寻求路线引导的真实场景。
- 实验表明,基于记忆的指令更长且措辞更多样,现有模型难以有效处理其中的错误和歧义。
📝 摘要(中文)
本文提出了Memory-Maze基准,旨在解决视觉语言导航(VLN)机器人引导盲人场景中,对基于记忆的路线指令理解不足的问题。现有的VLN模型难以处理此类场景,因为它们需要理解来自人类记忆的路线描述,这些描述通常包含口吃、错误和细节遗漏,而现有基准通常使用“边想边说”的指令。Memory-Maze包含一个迷宫结构的虚拟环境和来自人类记忆的新型路线指令数据,模拟了为盲人寻求路线指导的场景。分析表明,从记忆中收集的指令数据更长,包含更多样化的措辞。通过评估最先进的模型以及具有模块化感知和控制的基线模型,进一步证明了处理来自基于记忆的指令的错误和歧义是具有挑战性的。
🔬 方法详解
问题定义:现有的视觉语言导航(VLN)模型和基准数据集,主要关注于机器人接收清晰、无歧义的指令,并在已知环境中导航。然而,在盲人引导场景中,机器人需要理解由路人提供的、基于记忆的路线指令。这些指令通常包含口吃、错误、细节遗漏等问题,使得现有模型难以有效导航。因此,该论文旨在解决VLN模型在理解和执行基于记忆的、不完美的路线指令方面的不足。
核心思路:该论文的核心思路是构建一个更贴近真实盲人引导场景的VLN基准,即Memory-Maze。通过模拟迷宫环境,并收集人类基于记忆生成的路线指令,来训练和评估VLN模型在处理不确定性和歧义性指令方面的能力。这种方法旨在弥合现有VLN研究与实际应用之间的差距。
技术框架:Memory-Maze基准主要包含以下几个部分: 1. 迷宫环境:构建一个具有复杂结构的虚拟迷宫环境,为导航任务提供场景。 2. 路线指令数据:收集人类基于记忆生成的路线指令,这些指令包含口吃、错误和细节遗漏等问题。 3. 评估指标:使用标准的VLN评估指标,如导航成功率、路径长度等,来评估模型在Memory-Maze上的性能。 4. 基线模型:提供一个具有模块化感知和控制的基线模型,作为未来研究的参考。
关键创新:该论文的关键创新在于构建了一个更贴近真实盲人引导场景的VLN基准,即Memory-Maze。与现有基准相比,Memory-Maze的路线指令数据来源于人类记忆,更具挑战性和真实性。这使得研究人员可以更好地评估和改进VLN模型在处理不确定性和歧义性指令方面的能力。
关键设计:Memory-Maze的关键设计包括: 1. 迷宫结构:迷宫环境的设计需要保证一定的复杂性,以便测试模型在复杂环境下的导航能力。 2. 指令收集:指令收集过程需要模拟真实场景,例如让参与者在一段时间后回忆路线并生成指令。 3. 基线模型:基线模型采用模块化设计,方便研究人员进行改进和扩展。具体的网络结构和损失函数等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

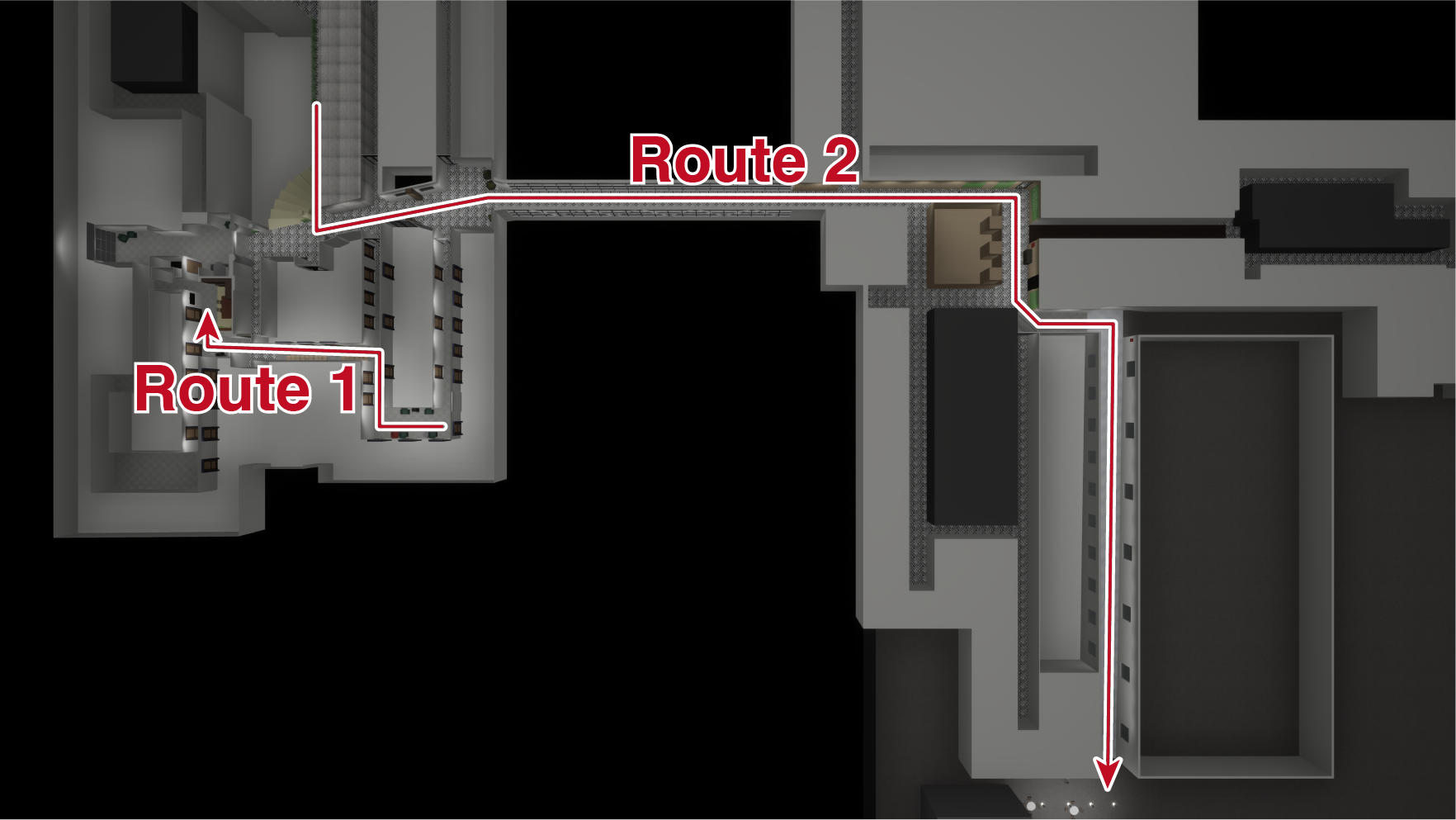
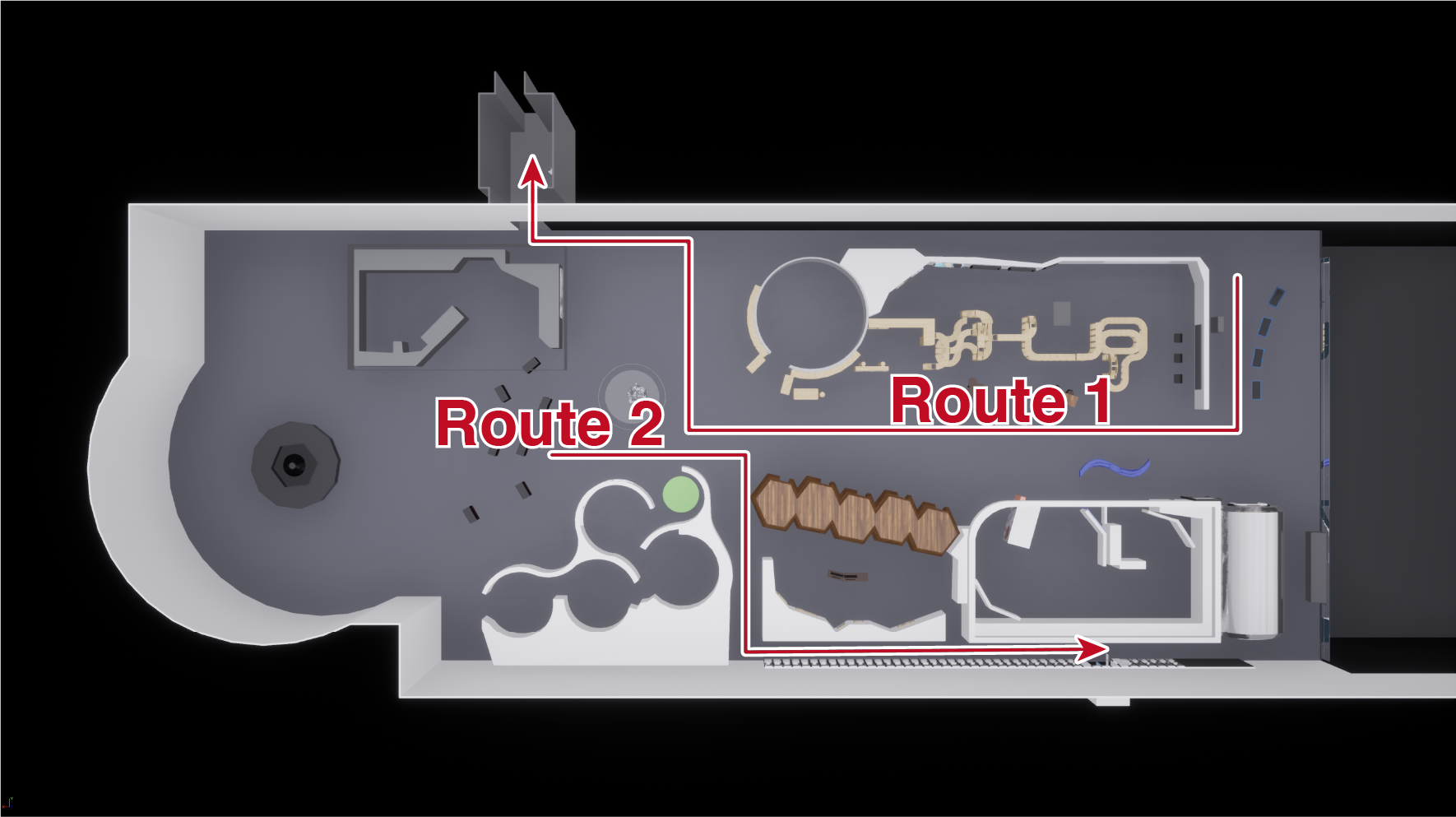
📊 实验亮点
该论文通过实验证明,从记忆中收集的指令数据比现有数据集更长,包含更多样化的措辞。同时,实验结果表明,现有的最先进模型在Memory-Maze基准上的表现不佳,表明处理基于记忆的指令中的错误和歧义仍然是一个巨大的挑战。具体的性能数据和提升幅度未在摘要中详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于开发智能导盲机器人,帮助视障人士在复杂环境中安全、自主地导航。通过提升机器人对自然语言指令的理解能力,特别是对包含错误和歧义的指令,可以显著改善视障人士的出行体验,提高其生活质量。未来,该技术还可扩展到其他需要人机协作的导航场景,如物流配送、室内服务等。
📄 摘要(原文)
Visual Language Navigation (VLN) powered robots have the potential to guide blind people by understanding route instructions provided by sighted passersby. This capability allows robots to operate in environments often unknown a prior. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contains stutters, errors, and omissions of details, as opposed to those obtained by thinking out loud, such as in the R2R dataset. However, existing benchmarks do not contain instructions obtained from human memory in natural environments. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. Our analysis demonstrates that instruction data collected from memory was longer and contained more varied wording. We further demonstrate that addressing errors and ambiguities from memory-based instructions is challenging, by evaluating state-of-the-art models alongside our baseline model with modularized perception and controls.