How Generalizable Is My Behavior Cloning Policy? A Statistical Approach to Trustworthy Performance Evaluation
作者: Joseph A. Vincent, Haruki Nishimura, Masha Itkina, Paarth Shah, Mac Schwager, Thomas Kollar
分类: cs.RO, cs.AI, cs.LG, stat.AP
发布日期: 2024-05-08 (更新: 2024-07-18)
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
提出一种基于统计的通用行为克隆策略评估框架,解决真实机器人部署中的性能评估难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 行为克隆 策略评估 随机排序 性能下界 机器人学习
📋 核心要点
- 真实机器人策略评估受限于rollout次数少和分布偏移,难以准确评估行为克隆策略的性能。
- 该论文提出一种基于统计的框架,通过少量实验rollout,为机器人性能提供一个严格的下界。
- 实验验证了该框架在模拟和真实机器人操作任务中的有效性,并开源了相关代码和数据。
📝 摘要(中文)
随着机器人策略学习中随机生成模型的兴起,端到端视觉运动策略在通过学习人类演示来解决复杂任务方面越来越成功。然而,由于真实世界评估的成本限制,用户只能进行少量的策略rollout,因此准确评估此类策略的性能仍然是一个挑战。分布偏移加剧了这一问题,导致部署期间性能出现不可预测的变化。为了严格评估行为克隆策略,我们提出了一个框架,该框架使用最少数量的实验策略rollout,为任意环境中的机器人性能提供了一个严格的下界。值得注意的是,通过将标准随机排序应用于机器人性能分布,我们为给定任务的整个性能分布提供了一个最坏情况的界限(通过累积分布函数的界限)。我们建立在已建立的统计结果之上,以确保界限在用户指定的置信水平和紧密度下成立,并尽可能从少的策略rollout中构建。在实验中,我们评估了模拟和硬件中的视觉运动操作策略。具体来说,我们(i)在模拟操作环境中经验性地验证了界限的保证,(ii)找到了部署在硬件上的学习策略推广到新的真实世界环境的程度,以及(iii)严格比较了在分布外环境中测试的两种策略。我们的实验数据、代码和置信界限的实现都是开源的。
🔬 方法详解
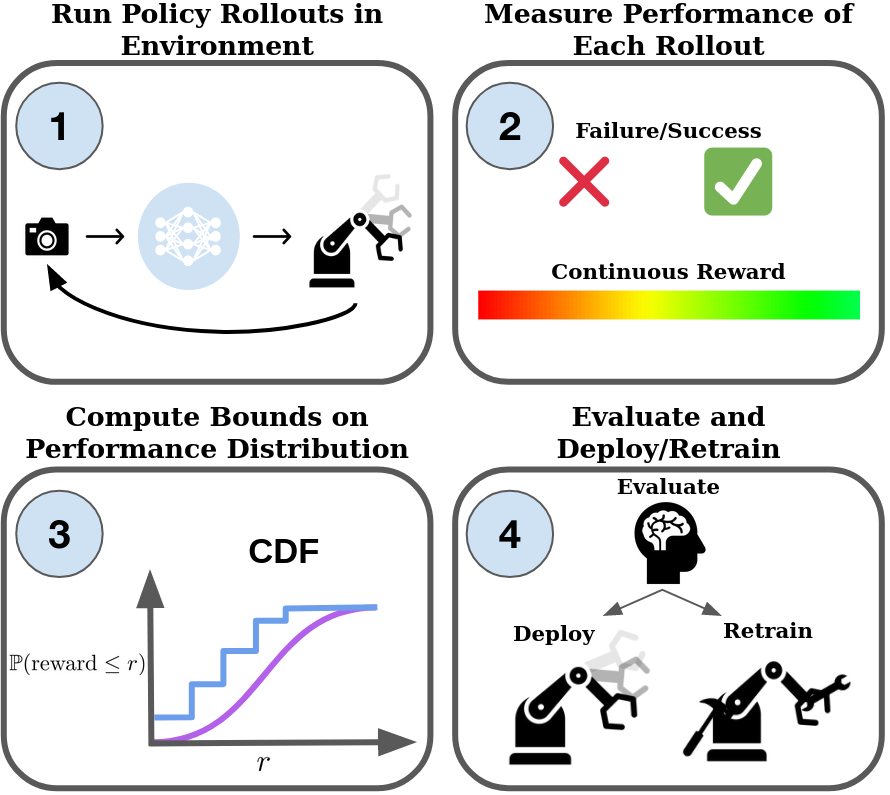
问题定义:论文旨在解决行为克隆策略在真实机器人部署中性能评估不准确的问题。现有方法依赖大量的实验rollout,成本高昂,且难以应对分布偏移带来的性能变化。因此,需要一种方法,能够使用少量实验数据,可靠地评估策略在任意环境下的性能下界。
核心思路:论文的核心思路是利用统计学中的随机排序理论,将机器人性能视为一个随机变量,并基于少量的实验rollout,估计其累积分布函数(CDF)的下界。通过这种方式,可以得到一个在用户指定的置信水平下,策略性能的最坏情况估计。
技术框架:该框架主要包含以下几个步骤:1) 进行少量策略rollout,收集性能数据;2) 利用统计方法,估计性能分布的累积分布函数(CDF);3) 基于随机排序理论,计算CDF的下界;4) 根据用户指定的置信水平和紧密度,调整下界的计算方法。整个框架旨在提供一个可靠的性能下界,帮助用户评估策略的泛化能力。
关键创新:该论文的关键创新在于将随机排序理论应用于机器人策略评估,提出了一种基于统计的性能下界估计方法。与传统的平均性能评估方法相比,该方法能够提供更可靠的性能保证,尤其是在分布偏移的情况下。此外,该方法只需要少量的实验数据,降低了评估成本。
关键设计:论文的关键设计包括:1) 使用标准随机排序来比较性能分布;2) 利用已有的统计结果,确保性能下界在用户指定的置信水平下成立;3) 设计了适用于少量实验数据的下界估计方法;4) 实验中,使用了视觉运动操作任务来验证该方法的有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够在模拟和真实机器人操作任务中,有效地估计策略的性能下界。在模拟环境中,验证了下界估计的准确性。在真实机器人环境中,评估了策略在不同环境下的泛化能力,并比较了两种策略在分布外环境中的性能。实验结果表明,该方法能够为策略评估提供可靠的保证。
🎯 应用场景
该研究成果可应用于各种机器人策略学习场景,尤其是在需要高可靠性和安全性的领域,如自动驾驶、医疗机器人和工业自动化。通过提供策略性能的可靠下界,可以帮助用户更好地评估策略的风险,并选择合适的策略进行部署。此外,该方法还可以用于策略优化,指导策略朝着更鲁棒的方向发展。
📄 摘要(原文)
With the rise of stochastic generative models in robot policy learning, end-to-end visuomotor policies are increasingly successful at solving complex tasks by learning from human demonstrations. Nevertheless, since real-world evaluation costs afford users only a small number of policy rollouts, it remains a challenge to accurately gauge the performance of such policies. This is exacerbated by distribution shifts causing unpredictable changes in performance during deployment. To rigorously evaluate behavior cloning policies, we present a framework that provides a tight lower-bound on robot performance in an arbitrary environment, using a minimal number of experimental policy rollouts. Notably, by applying the standard stochastic ordering to robot performance distributions, we provide a worst-case bound on the entire distribution of performance (via bounds on the cumulative distribution function) for a given task. We build upon established statistical results to ensure that the bounds hold with a user-specified confidence level and tightness, and are constructed from as few policy rollouts as possible. In experiments we evaluate policies for visuomotor manipulation in both simulation and hardware. Specifically, we (i) empirically validate the guarantees of the bounds in simulated manipulation settings, (ii) find the degree to which a learned policy deployed on hardware generalizes to new real-world environments, and (iii) rigorously compare two policies tested in out-of-distribution settings. Our experimental data, code, and implementation of confidence bounds are open-source.