Greedy Heuristics for Sampling-Based Motion Planning in High-Dimensional State Spaces
作者: Phone Thiha Kyaw, Anh Vu Le, Rajesh Elara Mohan, Jonathan Kelly
分类: cs.RO
发布日期: 2024-05-06 (更新: 2025-11-24)
备注: Submitted to the Autonomous Robots journal
💡 一句话要点
提出G-RRT*算法,通过贪婪启发式采样加速高维空间运动规划。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 运动规划 采样算法 RRT* 启发式搜索 高维空间 机器人 路径规划
📋 核心要点
- 现有Informed sampling方法在路径包含冗余时,采样区域过大,影响收敛速度。
- 提出贪婪Informed Set,基于当前解路径的最大启发式代价缩小采样区域,加速搜索。
- G-RRT*在多种任务中表现优异,能快速找到初始解并渐近收敛到最优路径。
📝 摘要(中文)
本文针对基于采样的运动规划算法收敛速度问题,提出了一种基于贪婪启发式采样的改进方法。现有Informed sampling技术虽然能加速收敛,但当解路径包含冗余或曲折部分时,采样区域仍然过大。本文正式描述了贪婪Informed Set在RRT类规划器中的行为,并分析了贪婪采样对探索和渐近最优性的影响。在此基础上,提出了Greedy RRT (G-RRT),一种双向、随时可用的RRT变体,利用贪婪Informed Set将采样集中在最有希望的搜索区域。在抽象规划基准、MotionBenchMaker数据集中的操作任务以及双臂Barrett WAM问题上的实验表明,G-RRT*能够快速找到初始解并渐近收敛到最优路径,优于最先进的基于采样的规划器。
🔬 方法详解
问题定义:论文旨在解决高维状态空间中,基于采样的运动规划算法收敛速度慢的问题。现有的Informed sampling方法,例如RRT*,虽然通过缩小采样空间来加速搜索,但当初始路径包含大量冗余或非最优部分时,Informed Set仍然会包含大量无用区域,导致采样效率降低。
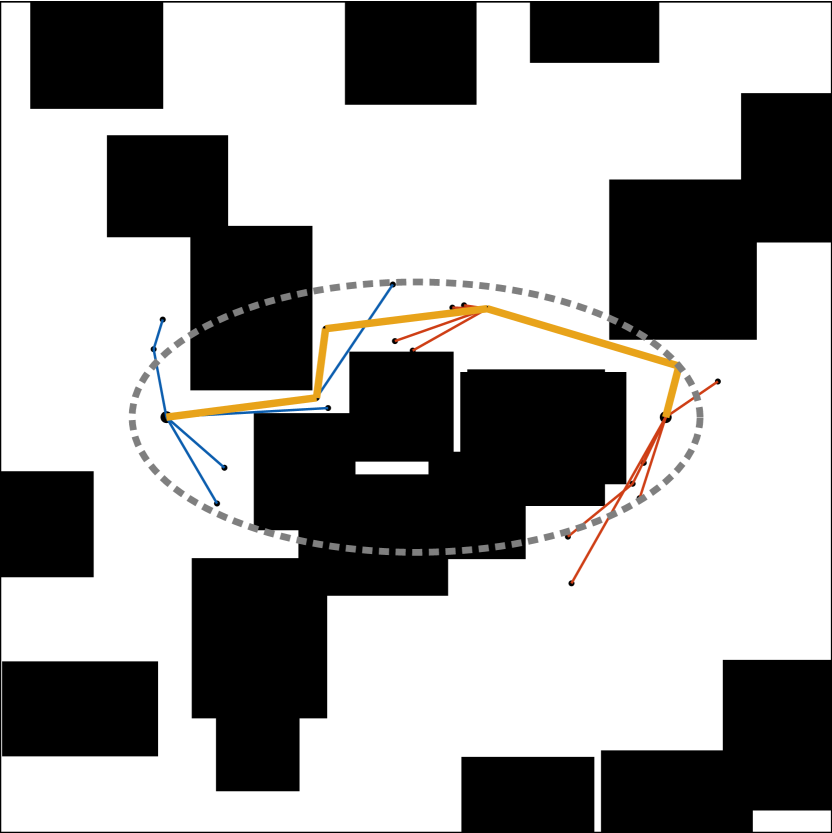
核心思路:论文的核心思路是引入“贪婪”策略,进一步缩小Informed Set。具体来说,不是简单地基于当前最优路径的整体代价来确定采样范围,而是基于路径上具有最大启发式代价的部分来确定。这样可以更积极地排除那些明显不太可能包含最优解的区域,从而更有效地利用采样资源。
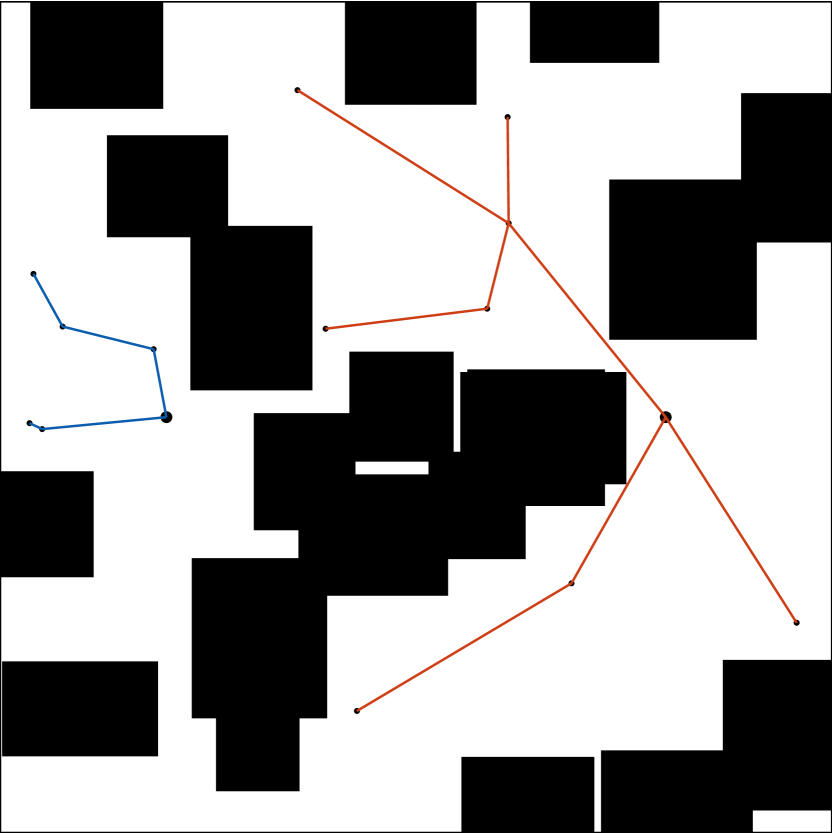
技术框架:G-RRT是RRT算法的一个变体,采用了双向搜索策略和随时可用的特性。其主要流程如下:1) 初始化两棵搜索树,分别从起始状态和目标状态开始生长。2) 在每次迭代中,从贪婪Informed Set中采样一个状态。3) 将采样状态连接到最近的树节点,并尝试连接到另一棵树。4) 如果找到连接两棵树的路径,则更新当前最优路径。5) 基于当前最优路径的最大启发式代价,更新贪婪Informed Set。这个过程不断迭代,直到满足停止条件。
关键创新:论文的关键创新在于提出了贪婪Informed Set的概念,并将其应用于RRT*算法中。与传统的Informed sampling方法相比,贪婪Informed Set能够更积极地缩小采样空间,从而提高采样效率。本质区别在于,传统方法基于整体路径代价,而贪婪方法基于路径上的最大启发式代价。
关键设计:G-RRT的关键设计在于如何计算和更新贪婪Informed Set。具体来说,对于当前最优路径,首先计算路径上每个状态的启发式代价(例如,到目标状态的估计距离)。然后,选择具有最大启发式代价的状态,并基于该代价确定贪婪Informed Set的范围。这个范围通常比基于整体路径代价确定的范围更小。此外,G-RRT还采用了双向搜索和随时可用的策略,以进一步提高算法的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,G-RRT在抽象规划基准、MotionBenchMaker数据集中的操作任务以及双臂Barrett WAM问题上均优于state-of-the-art的基于采样的规划器。G-RRT能够更快地找到初始解,并渐近收敛到最优路径。具体性能提升数据在论文中给出,表明G-RRT*在复杂场景下具有显著优势。
🎯 应用场景
该研究成果可应用于机器人运动规划、自动驾驶、游戏AI等领域。通过更高效的运动规划,机器人可以在复杂环境中更快、更可靠地完成任务,例如在拥挤的仓库中进行拣选和放置操作,或在动态交通环境中进行安全导航。该方法还可以用于生成更逼真的游戏角色动画。
📄 摘要(原文)
Informed sampling techniques accelerate the convergence of sampling-based motion planners by biasing sampling toward regions of the state space that are most likely to yield better solutions. However, when the current solution path contains redundant or tortuous segments, the resulting informed subset may remain unnecessarily large, slowing convergence. Our prior work addressed this issue by introducing the greedy informed set, which reduces the sampling region based on the maximum heuristic cost along the current solution path. In this article, we formally characterize the behavior of the greedy informed set within Rapidly-exploring Random Tree (RRT)-like planners and analyze how greedy sampling affects exploration and asymptotic optimality. We then present Greedy RRT (G-RRT), a bi-directional anytime variant of RRT that leverages the greedy informed set to focus sampling in the most promising regions of the search space. Experiments on abstract planning benchmarks, manipulation tasks from the MotionBenchMaker dataset, and a dual-arm Barrett WAM problem demonstrate that G-RRT* rapidly finds initial solutions and converges asymptotically to optimal paths, outperforming state-of-the-art sampling-based planners.