Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
作者: Dhruva Tirumala, Markus Wulfmeier, Ben Moran, Sandy Huang, Jan Humplik, Guy Lever, Tuomas Haarnoja, Leonard Hasenclever, Arunkumar Byravan, Nathan Batchelor, Neil Sreendra, Kushal Patel, Marlon Gwira, Francesco Nori, Martin Riedmiller, Nicolas Heess
分类: cs.RO, cs.AI
发布日期: 2024-05-03
💡 一句话要点
提出基于深度强化学习和自中心视觉的端到端机器人足球训练方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 机器人足球 深度强化学习 自中心视觉 神经辐射场 多智能体学习
📋 核心要点
- 现有机器人足球方法难以实现完全基于板载视觉的端到端控制,限制了其在真实环境中的应用。
- 论文提出一种基于深度强化学习的框架,利用自中心视觉输入直接训练机器人足球策略,无需人工特征工程。
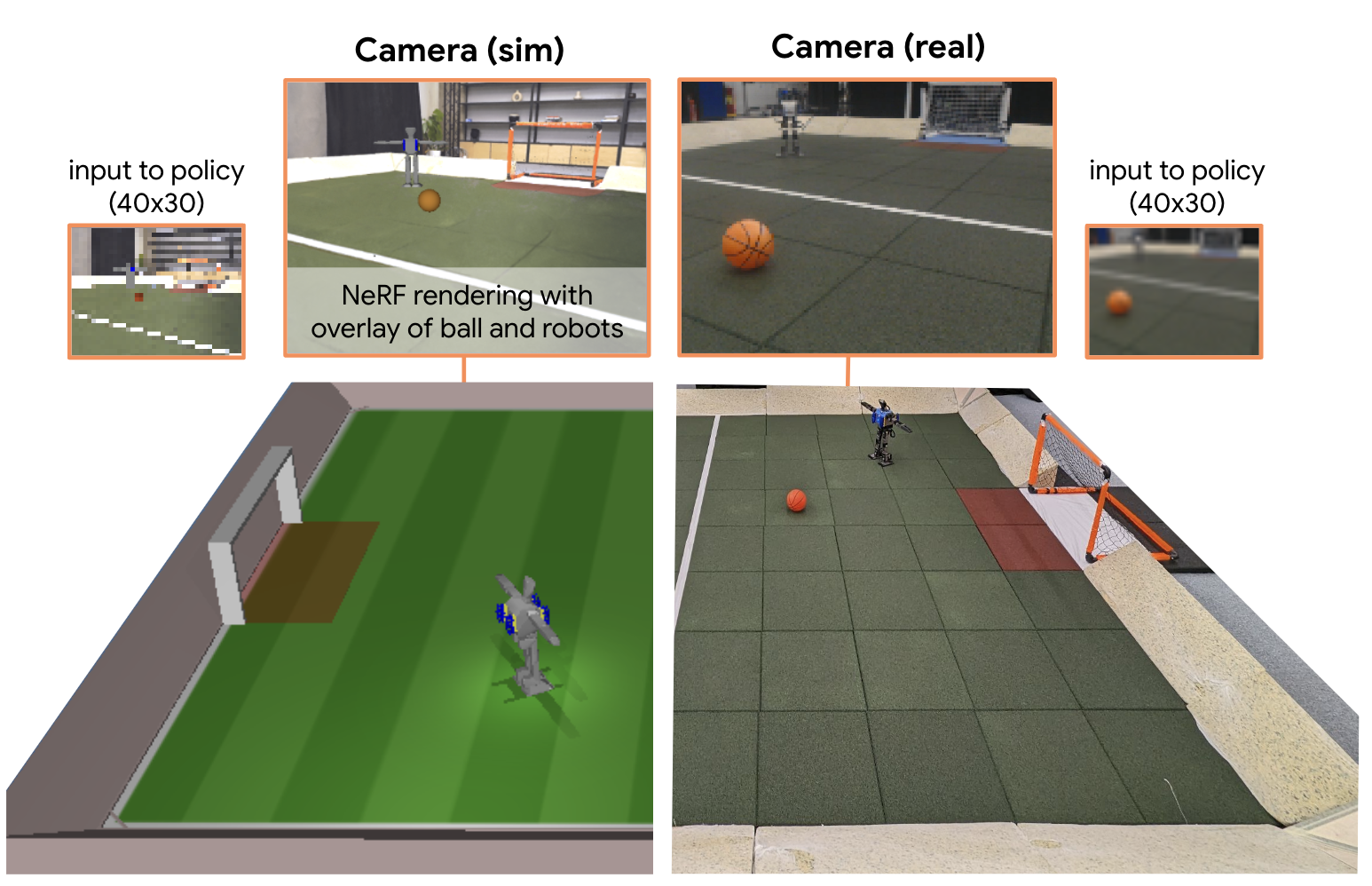
- 通过仿真训练和NeRF渲染提升视觉真实度,策略成功迁移到真实机器人,性能与使用真实状态信息的策略相当。
📝 摘要(中文)
本文应用多智能体深度强化学习(RL)来训练端到端的机器人足球策略,该策略完全基于板载计算和通过自中心RGB视觉进行的感知。这种设置反映了现实世界机器人技术的诸多挑战,包括主动感知、敏捷的全身控制以及在动态、部分可观察的多智能体领域中的长时程规划。我们依靠大规模的、基于仿真的数据生成,从自中心视觉中获得复杂的行为,这些行为可以使用低成本传感器成功转移到物理机器人上。为了实现足够的视觉真实感,我们的仿真将刚体物理与通过多个神经辐射场(NeRFs)学习到的逼真渲染相结合。我们结合了基于教师的多智能体RL和跨实验数据重用,以实现复杂足球策略的发现。我们分析了主动感知行为,包括对象跟踪和寻球,这些行为在简单地优化与感知无关的足球比赛时出现。这些智能体表现出与具有访问特权、真实状态的策略相当的性能和敏捷性。据我们所知,本文首次展示了多智能体机器人足球的端到端训练,将原始像素观测映射到关节级动作,并且可以部署在现实世界中。
🔬 方法详解
问题定义:现有机器人足球方法通常依赖于外部传感器或人工设计的特征,难以实现完全自主的、基于板载视觉的端到端控制。这限制了它们在真实动态环境中的应用,因为真实环境中的感知具有噪声和不确定性。此外,多智能体协作策略的训练也面临着探索空间大、奖励稀疏等挑战。
核心思路:论文的核心思路是利用深度强化学习,直接从自中心视觉输入学习机器人足球策略。通过大规模仿真生成数据,并使用神经辐射场(NeRFs)来提高仿真的视觉真实度,从而实现从仿真到真实环境的策略迁移。同时,采用基于教师的多智能体强化学习和跨实验数据重用,加速策略学习并发现复杂的足球策略。
技术框架:整体框架包括以下几个主要模块:1) 基于物理引擎的机器人足球仿真环境;2) 使用NeRFs进行逼真渲染的视觉模拟器;3) 基于深度强化学习的策略学习模块,该模块使用自中心视觉作为输入,输出机器人的关节控制指令;4) 基于教师的多智能体强化学习框架,用于指导智能体学习复杂的协作策略;5) 策略迁移模块,用于将仿真环境中学习到的策略迁移到真实机器人上。
关键创新:最重要的技术创新点在于实现了完全基于板载视觉的端到端机器人足球策略学习。与传统方法相比,该方法无需人工特征工程,可以直接从原始像素输入学习复杂的控制策略。此外,使用NeRFs进行逼真渲染,显著提高了仿真环境的真实度,从而实现了从仿真到真实环境的有效策略迁移。
关键设计:论文中关键的设计包括:1) 使用多个NeRFs来模拟不同光照和视角下的视觉效果;2) 采用基于教师的多智能体强化学习,利用专家策略指导智能体学习;3) 使用跨实验数据重用,加速策略学习;4) 设计合适的奖励函数,鼓励智能体学习足球相关的行为,例如寻球、传球和射门。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法训练的机器人足球策略在仿真环境中表现出与使用真实状态信息的策略相当的性能和敏捷性。更重要的是,该策略成功迁移到真实机器人上,实现了基于板载视觉的自主足球比赛。这证明了该方法在解决真实世界机器人问题方面的有效性。
🎯 应用场景
该研究成果可应用于其他需要自主导航和控制的机器人应用场景,例如无人驾驶、物流机器人、家庭服务机器人等。通过结合深度强化学习和逼真视觉仿真,可以降低机器人开发的成本和周期,并提高机器人在复杂环境中的适应能力。此外,该研究也为多智能体协作策略的学习提供了一种新的思路。
📄 摘要(原文)
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .