Learning Tactile Insertion in the Real World
作者: Daniel Palenicek, Theo Gruner, Tim Schneider, Alina Böhm, Janis Lenz, Inga Pfenning, Eric Krämer, Jan Peters
分类: cs.RO
发布日期: 2024-05-01 (更新: 2024-07-31)
💡 一句话要点
提出基于Dreamer-v3的触觉强化学习方法,解决真实机器人环境下的插入任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 触觉感知 强化学习 机器人操作 Dreamer-v3 插入任务
📋 核心要点
- 机器人操作任务中,触觉感知对于解决部分可观测问题至关重要,但如何有效集成触觉信息到控制环路仍然是一个挑战。
- 本文提出使用强化学习算法Dreamer-v3,直接从触觉传感器数据学习控制策略,实现端到端的机器人操作控制。
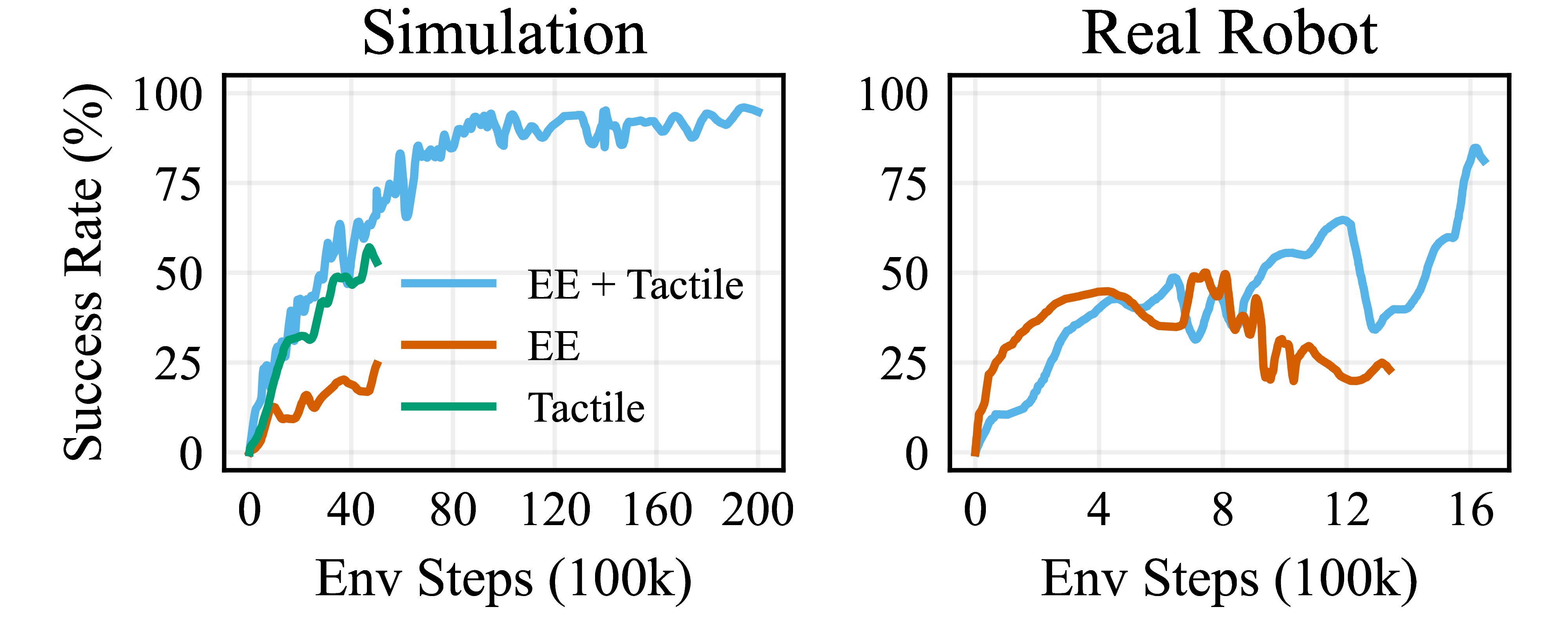
- 通过构建自主重置的机器人平台,在真实环境中进行了大量的训练,初步结果表明该方法能够有效利用触觉信息完成插入任务。
📝 摘要(中文)
本文提出了一种利用强化学习解决部分可观测机器人操作任务的方法,特别是具有挑战性的机器人插入任务。该方法直接从触觉传感器读数映射到动作,使用Dreamer-v3算法在Franka Research 3机器人上进行端到端策略学习,包括仿真环境和真实系统。为了在真实环境中进行广泛的训练,构建了一个能够完全自主重置的机器人平台,无需人工干预。初步结果表明,Dreamer能够利用触觉输入来解决仿真和真实环境中的机器人操作任务。触觉反馈通常可以提高任务性能,但目前设置中未包含其他传感模态。未来计划利用该平台评估更多强化学习算法在触觉任务上的表现。
🔬 方法详解
问题定义:论文旨在解决真实机器人环境下的插入任务,这是一个具有挑战性的部分可观测问题。现有的方法难以有效利用触觉信息,导致在接触密集型操作中表现不佳。
核心思路:论文的核心思路是利用强化学习,特别是Dreamer-v3算法,直接从触觉传感器读数学习控制策略。通过端到端的学习方式,避免了手动设计特征或规则,从而更好地适应复杂的触觉信息。
技术框架:整体框架包括一个Franka Research 3机器人,配备触觉传感器。系统首先在仿真环境中进行预训练,然后在真实环境中进行微调。为了实现自主训练,构建了一个能够自动重置的机器人平台。Dreamer-v3算法接收触觉传感器的输入,输出机器人的动作指令。
关键创新:关键创新在于将Dreamer-v3算法应用于触觉控制,并构建了自主重置的机器人平台,从而能够在真实环境中进行大规模的强化学习训练。与传统方法相比,该方法无需手动设计特征,能够更好地适应复杂的触觉信息。
关键设计:论文中使用了Dreamer-v3算法,这是一种基于世界模型的强化学习算法。具体的参数设置和网络结构细节在论文中可能没有详细描述,需要参考Dreamer-v3的原始论文。损失函数包括重构损失和奖励预测损失,用于训练世界模型和策略网络。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Dreamer-v3算法能够有效利用触觉信息解决机器人插入任务。虽然论文中没有给出具体的性能数据和对比基线,但初步结果表明,在真实环境中,触觉反馈能够提高任务的成功率。自主重置平台的构建使得能够在真实环境中进行大规模的强化学习训练,为后续研究奠定了基础。
🎯 应用场景
该研究成果可应用于各种需要精细操作和触觉反馈的机器人任务,例如装配、医疗手术、以及在恶劣或不可见环境下进行的操作。通过学习触觉信息,机器人可以更好地理解周围环境,提高操作的精度和鲁棒性,从而在工业自动化和智能服务领域发挥重要作用。
📄 摘要(原文)
Humans have exceptional tactile sensing capabilities, which they can leverage to solve challenging, partially observable tasks that cannot be solved from visual observation alone. Research in tactile sensing attempts to unlock this new input modality for robots. Lately, these sensors have become cheaper and, thus, widely available. At the same time, the question of how to integrate them into control loops is still an active area of research, with central challenges being partial observability and the contact-rich nature of manipulation tasks. In this study, we propose to use Reinforcement Learning to learn an end-to-end policy, mapping directly from tactile sensor readings to actions. Specifically, we use Dreamer-v3 on a challenging, partially observable robotic insertion task with a Franka Research 3, both in simulation and on a real system. For the real setup, we built a robotic platform capable of resetting itself fully autonomously, allowing for extensive training runs without human supervision. Our preliminary results indicate that Dreamer is capable of utilizing tactile inputs to solve robotic manipulation tasks in simulation and reality. Furthermore, we find that providing the robot with tactile feedback generally improves task performance, though, in our setup, we do not yet include other sensing modalities. In the future, we plan to utilize our platform to evaluate a wide range of other Reinforcement Learning algorithms on tactile tasks.