RoboMP$^2$: A Robotic Multimodal Perception-Planning Framework with Multimodal Large Language Models
作者: Qi Lv, Hao Li, Xiang Deng, Rui Shao, Michael Yu Wang, Liqiang Nie
分类: cs.RO
发布日期: 2024-04-07 (更新: 2024-06-08)
备注: Accepted by ICML 2024; Project page: https://aopolin-lv.github.io/RoboMP2.github.io/
期刊: Proceedings of the 41st International Conference on Machine Learning, PMLR 235:33558-33574, 2024
💡 一句话要点
提出RoboMP$^2$框架以解决机器人多模态感知与规划问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态感知 机器人规划 大型语言模型 语义推理 增强检索 决策支持 智能机器人
📋 核心要点
- 现有方法在未见任务上的泛化能力有限,且忽视了多模态环境信息,影响机器人决策的准确性。
- 本文提出的RoboMP$^2$框架结合了GCMP和RAMP,旨在通过多模态感知和增强检索来提升机器人规划能力。
- 实验结果显示,RoboMP$^2$在VIMA基准和实际任务中表现优越,相较于基线提升约10%。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在多个领域展现了出色的推理能力和通用智能,激励研究者训练端到端的MLLMs或利用大型模型生成策略以供具身代理使用。然而,这些方法在未见任务或场景上的泛化能力有限,并忽视了对机器人决策至关重要的多模态环境信息。本文提出了一种新颖的机器人多模态感知-规划(RoboMP$^2$)框架,包括目标条件多模态感知器(GCMP)和增强检索多模态规划器(RAMP)。GCMP通过定制的MLLMs捕捉环境状态,具备语义推理和定位能力;RAMP利用粗到细的检索方法找到最相关的策略作为上下文示例,以增强规划能力。大量实验表明,RoboMP$^2$在VIMA基准和实际任务中优于基线,提升约10%。
🔬 方法详解
问题定义:本文旨在解决现有多模态大型语言模型在机器人任务中的泛化能力不足和对环境信息利用不充分的问题。现有方法往往无法有效应对未见任务,导致决策质量下降。
核心思路:RoboMP$^2$框架通过结合目标条件多模态感知器(GCMP)和增强检索多模态规划器(RAMP),实现对环境状态的精准捕捉和高效的策略检索,从而提升机器人在复杂环境中的决策能力。
技术框架:RoboMP$^2$框架主要由两个模块组成:GCMP负责环境状态的感知,利用定制的MLLMs进行语义推理和定位;RAMP则通过粗到细的检索方法,找到最相关的策略作为上下文示例,增强规划过程。
关键创新:该框架的创新点在于引入了多模态感知与规划的结合,特别是通过GCMP和RAMP的协同工作,显著提升了机器人在多样化任务中的适应能力和决策效率。
关键设计:GCMP使用定制的MLLMs进行环境状态捕捉,RAMP则采用了基于检索的策略生成方法,具体参数设置和损失函数设计未在摘要中详细说明,需参考原文获取更多技术细节。
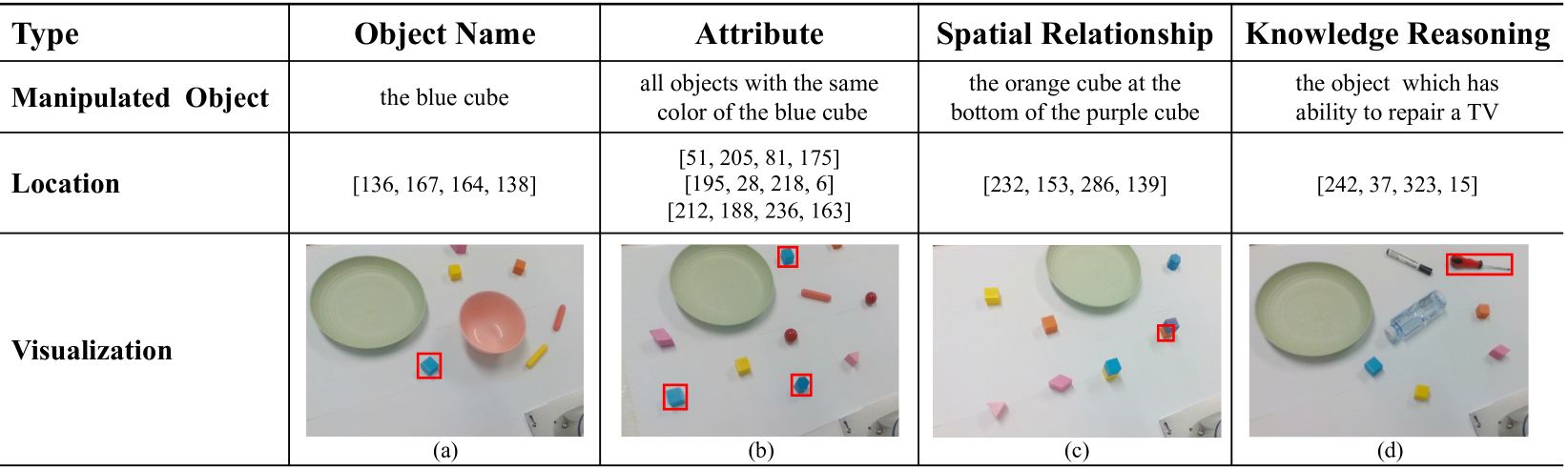
🖼️ 关键图片


📊 实验亮点
在VIMA基准和实际任务中,RoboMP$^2$框架表现出色,相较于基线方法提升约10%。这一显著的性能提升表明该框架在多模态感知和规划方面的有效性,展示了其在机器人领域的应用前景。
🎯 应用场景
RoboMP$^2$框架在机器人操作、自动化制造、智能家居等领域具有广泛的应用潜力。通过提升机器人在复杂环境中的感知与决策能力,该研究有望推动智能机器人技术的实际应用,改善人机交互体验,并促进自主系统的发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have shown impressive reasoning abilities and general intelligence in various domains. It inspires researchers to train end-to-end MLLMs or utilize large models to generate policies with human-selected prompts for embodied agents. However, these methods exhibit limited generalization capabilities on unseen tasks or scenarios, and overlook the multimodal environment information which is critical for robots to make decisions. In this paper, we introduce a novel Robotic Multimodal Perception-Planning (RoboMP$^2$) framework for robotic manipulation which consists of a Goal-Conditioned Multimodal Preceptor (GCMP) and a Retrieval-Augmented Multimodal Planner (RAMP). Specially, GCMP captures environment states by employing a tailored MLLMs for embodied agents with the abilities of semantic reasoning and localization. RAMP utilizes coarse-to-fine retrieval method to find the $k$ most-relevant policies as in-context demonstrations to enhance the planner. Extensive experiments demonstrate the superiority of RoboMP$^2$ on both VIMA benchmark and real-world tasks, with around 10% improvement over the baselines.