Demonstration-Enhanced Adaptable Multi-Objective Robot Navigation
作者: Jorge de Heuvel, Tharun Sethuraman, Maren Bennewitz
分类: cs.RO
发布日期: 2024-04-07 (更新: 2025-10-18)
💡 一句话要点
提出动态适应的多目标机器人导航框架以解决用户偏好变化问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人导航 多目标强化学习 用户偏好适应 示范学习 动态调整策略
📋 核心要点
- 现有的强化学习方法在面对用户偏好变化时表现不足,无法动态调整导航策略。
- 本文提出了一种结合示范学习与多目标强化学习的框架,允许机器人在不重新训练的情况下适应用户偏好。
- 通过对比实验和仿真到现实的转移,验证了该框架在导航性能和用户偏好适应性方面的显著提升。
📝 摘要(中文)
在以人为中心的环境中,机器人导航通常依赖学习方法,通过用户反馈或示范进行个性化。然而,个人偏好可能会随时间和环境变化而变化,传统的强化学习方法因静态奖励函数而难以适应这些变化。本文提出了一种结构化框架,将基于示范的学习与多目标强化学习相结合,允许机器人导航策略动态适应用户偏好的变化,而无需重新训练。通过严格的评估,包括基线比较和仿真到现实的转移,展示了该框架在准确适应用户偏好和实现高效导航性能(如避免碰撞和追求目标)方面的能力。
🔬 方法详解
问题定义:本文旨在解决机器人导航中用户偏好变化带来的适应性问题。现有方法依赖静态奖励函数,无法有效应对用户偏好的动态变化。
核心思路:提出的框架结合了基于示范的学习与多目标强化学习,允许机器人在实际应用中动态调整导航策略,以适应不断变化的用户偏好。
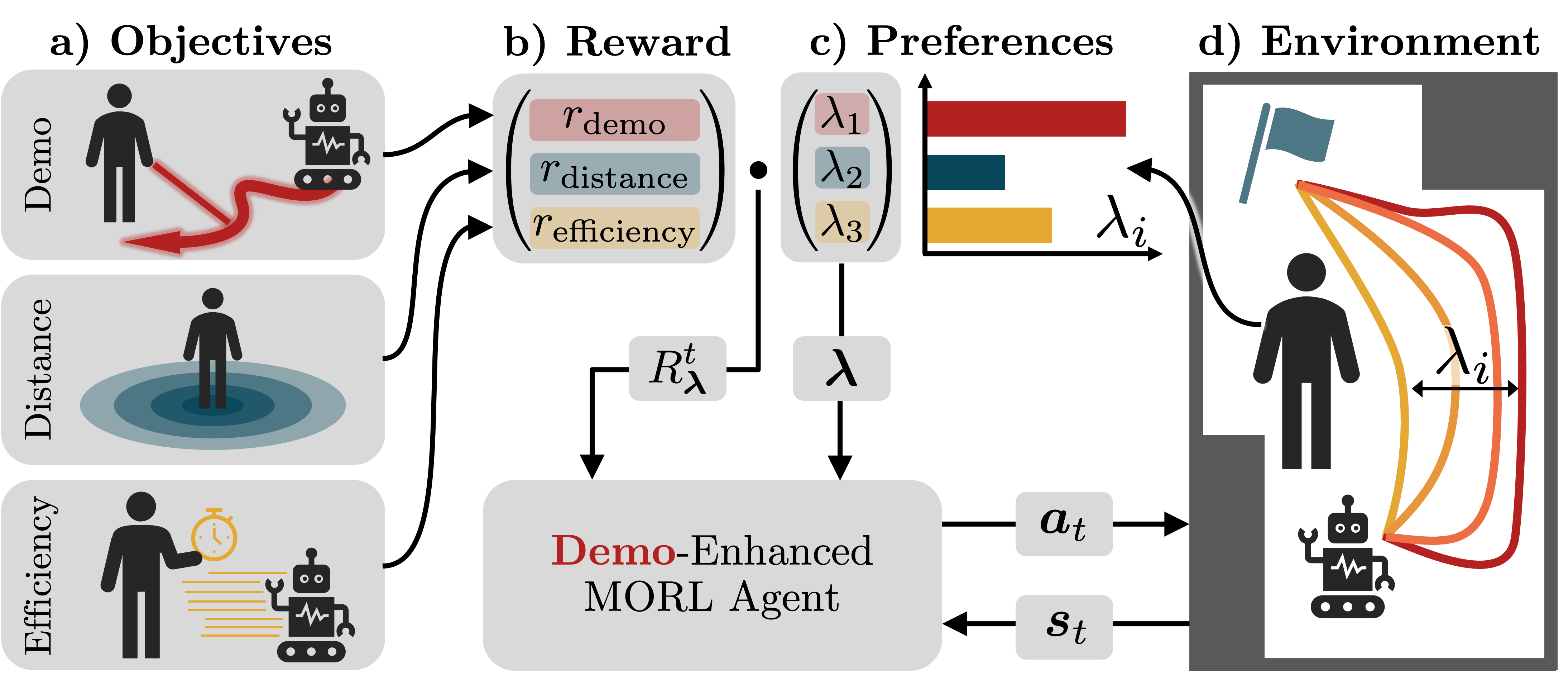
技术框架:该框架包括多个模块,首先通过用户示范数据进行初步学习,然后在实际环境中根据用户反馈动态调整策略,确保导航过程中的灵活性和适应性。
关键创新:最重要的创新在于实现了动态适应性,机器人能够在不进行重新训练的情况下,实时调整其导航策略以反映用户的最新偏好,这与传统方法形成鲜明对比。
关键设计:框架中采用了灵活的损失函数设计,以平衡示范数据的反映程度与其他偏好相关目标,同时在网络结构上进行了优化,以提高学习效率和适应能力。
🖼️ 关键图片
📊 实验亮点
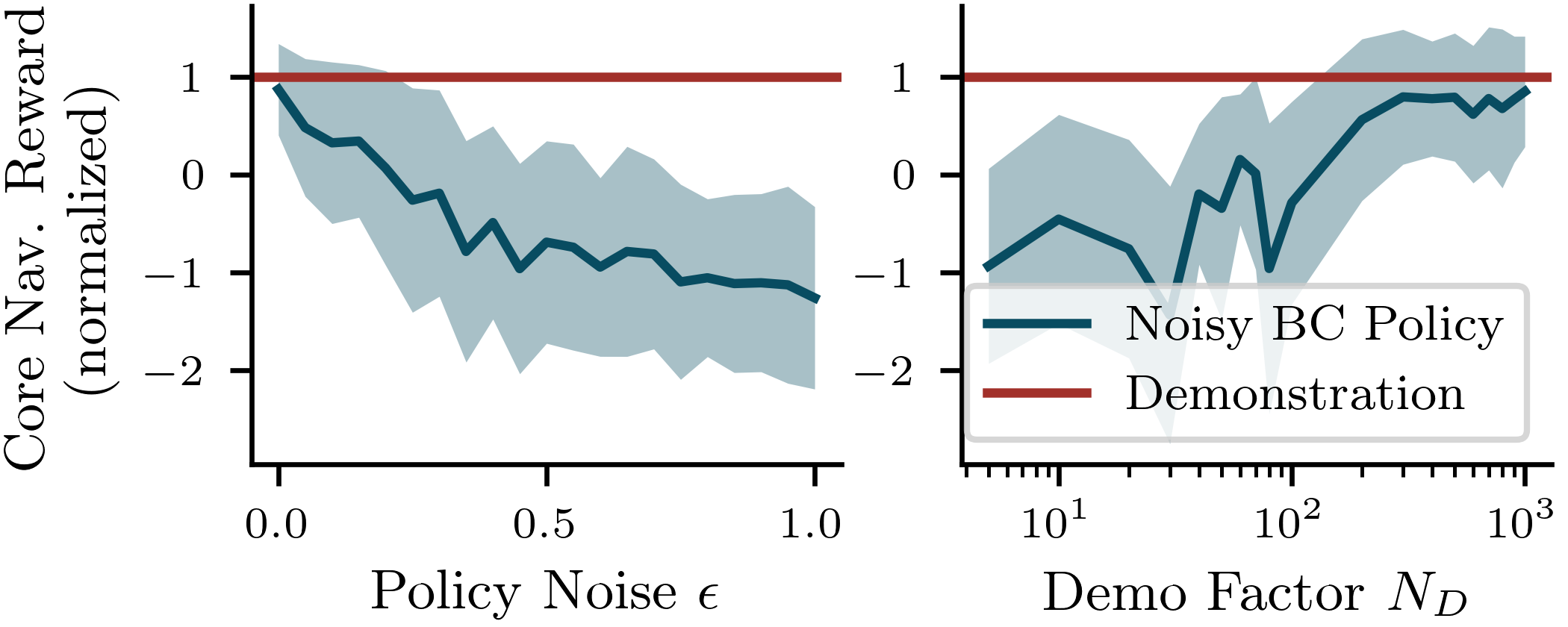
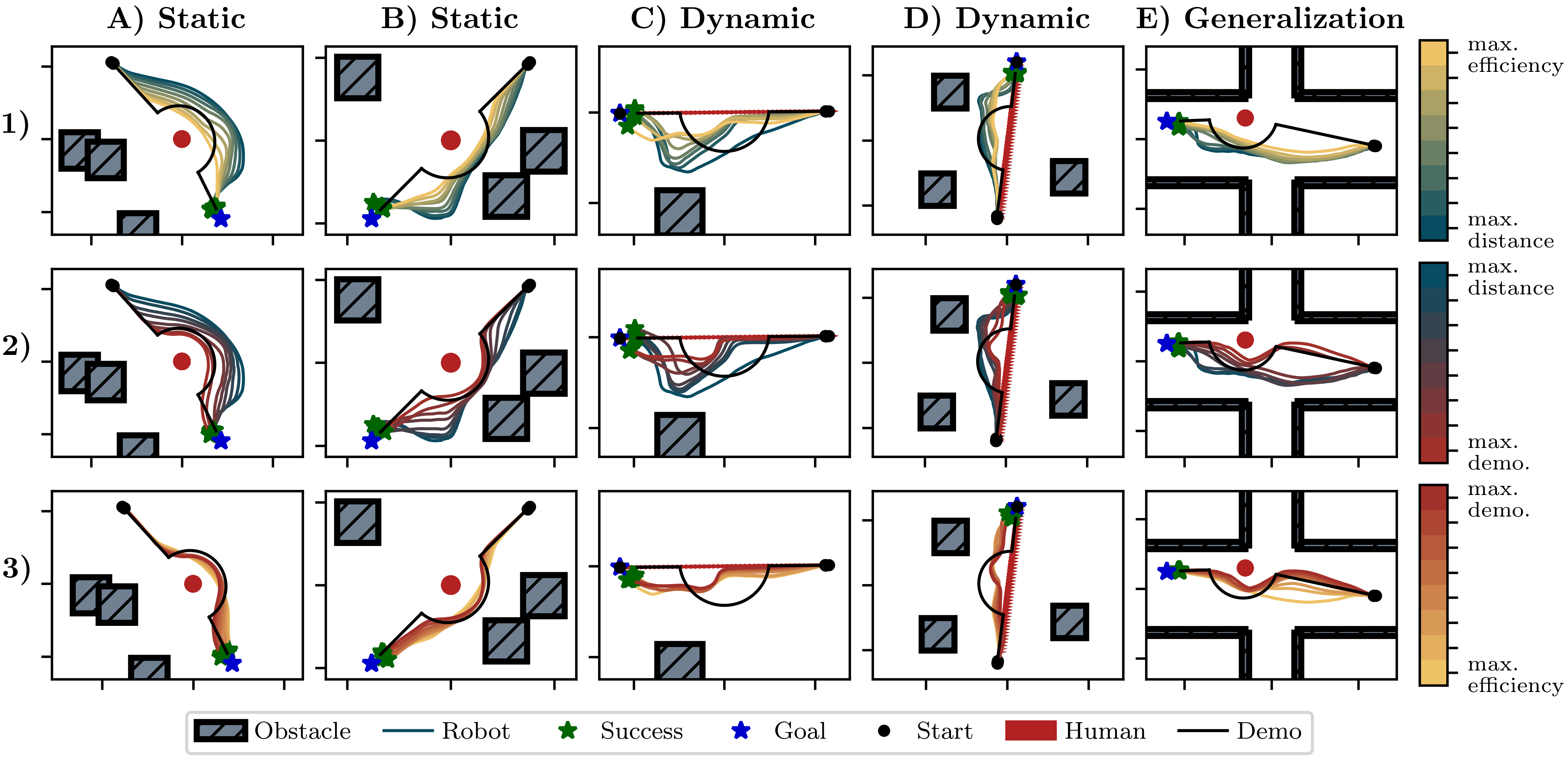
实验结果表明,提出的框架在用户偏好适应性和导航性能方面均优于基线方法。在碰撞避免和目标追求方面,机器人表现出显著的提升,具体性能数据在实验中得到了验证,展示了该方法的有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括智能家居、服务机器人和自主导航系统等。通过实现动态适应的导航策略,机器人能够更好地满足用户的个性化需求,从而提升用户体验和满意度。未来,该技术有望在更广泛的机器人应用中得到推广,推动人机协作的发展。
📄 摘要(原文)
Preference-aligned robot navigation in human environments is typically achieved through learning-based approaches, utilizing user feedback or demonstrations for personalization. However, personal preferences are subject to change and might even be context-dependent. Yet traditional reinforcement learning (RL) approaches with static reward functions often fall short in adapting to evolving user preferences, inevitably reflecting demonstrations once training is completed. This paper introduces a structured framework that combines demonstration-based learning with multi-objective reinforcement learning (MORL). To ensure real-world applicability, our approach allows for dynamic adaptation of the robot navigation policy to changing user preferences without retraining. It fluently modulates the amount of demonstration data reflection and other preference-related objectives. Through rigorous evaluations, including a baseline comparison and sim-to-real transfer on two robots, we demonstrate our framework's capability to adapt to user preferences accurately while achieving high navigational performance in terms of collision avoidance and goal pursuance.