Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
作者: Gawon Choi, Hyemin Ahn
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-04-05
备注: 8 pages, 11 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出小型语言模型在任务规划中的潜力以解决复杂指令问题
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 任务规划 链式推理 数据集构建 机器人技术 微调技术 领域适应性
📋 核心要点
- 现有的大型语言模型在理解复杂指令时表现良好,但在实际机器人应用中仍面临执行复杂动作的困难。
- 本文提出通过训练小型语言模型进行链式推理,构建COmmand-STeps数据集,以提高小型模型在特定领域的任务规划能力。
- 实验结果表明,微调后的GPT2在特定任务领域的表现与GPT3.5相当,展示了小型语言模型的潜力。
📝 摘要(中文)
在机器人领域,大型语言模型(LLMs)的使用越来越普遍,尤其是在理解人类指令方面。LLMs作为领域无关的任务规划者,能够进行链式推理(CoT),但现代机器人在执行复杂动作时仍面临挑战。本文探讨了小型语言模型是否能够在特定领域内进行链式推理,从而成为有效的任务规划者。为此,研究者构建了COmmand-STeps数据集(COST),该数据集包含高层指令及其对应的可执行低层步骤,并与GPT3.5和GPT4进行比较,结果显示经过微调的GPT2在特定领域的任务规划上与GPT3.5相当。研究成果及数据集已公开,供他人使用。
🔬 方法详解
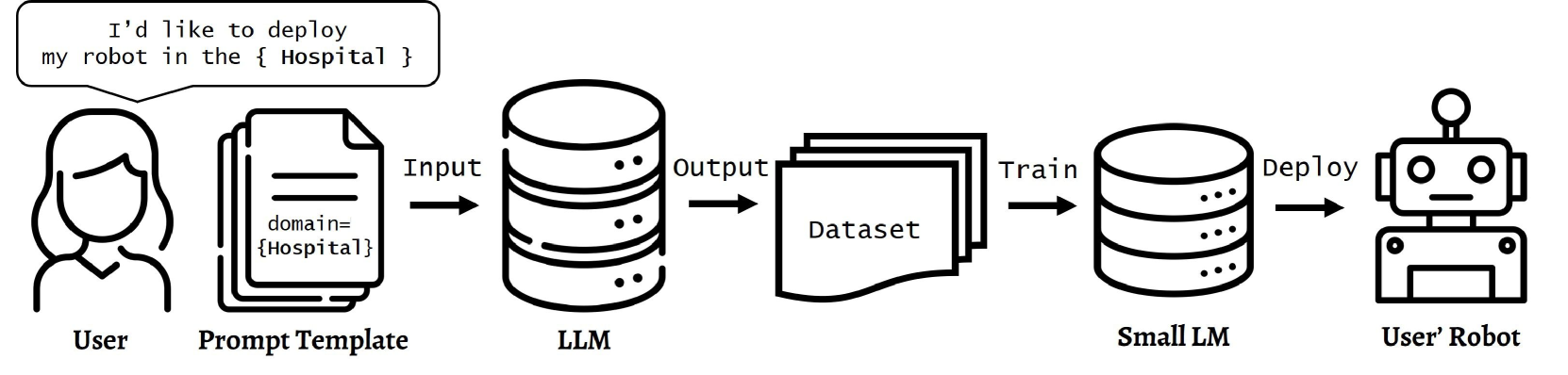
问题定义:本文旨在解决小型语言模型在特定领域内的任务规划能力不足的问题。现有的大型语言模型虽然表现优异,但其应用受限于计算资源和复杂性。
核心思路:通过构建COmmand-STeps数据集,训练小型语言模型进行链式推理,使其能够在特定领域内有效执行任务规划。这样的设计旨在降低对计算资源的需求,同时保持任务规划的有效性。
技术框架:整体框架包括数据集构建、模型训练和性能评估三个主要模块。数据集由高层指令和对应的低层步骤组成,模型训练则使用微调技术,最后通过与大型模型的比较评估性能。
关键创新:最重要的创新在于通过小型语言模型实现链式推理的能力,展示了其在特定任务规划中的有效性,与传统依赖大型模型的方法形成鲜明对比。
关键设计:在模型训练中,采用了特定的损失函数和参数设置,以优化小型语言模型的推理能力。同时,使用了生成提示模板以确保数据集的多样性和有效性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,经过微调的GPT2在特定领域的任务规划能力与GPT3.5相当,表明小型语言模型在特定任务中的有效性。这一发现为小型模型的应用提供了新的视角,可能会推动机器人领域的进一步发展。
🎯 应用场景
该研究的潜在应用领域包括家庭机器人、工业自动化和服务机器人等。通过提升小型语言模型的任务规划能力,可以降低机器人系统的成本,提高其在特定环境中的适应性和灵活性,具有重要的实际价值和未来影响。
📄 摘要(原文)
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning